深入理解Java关键字volatile
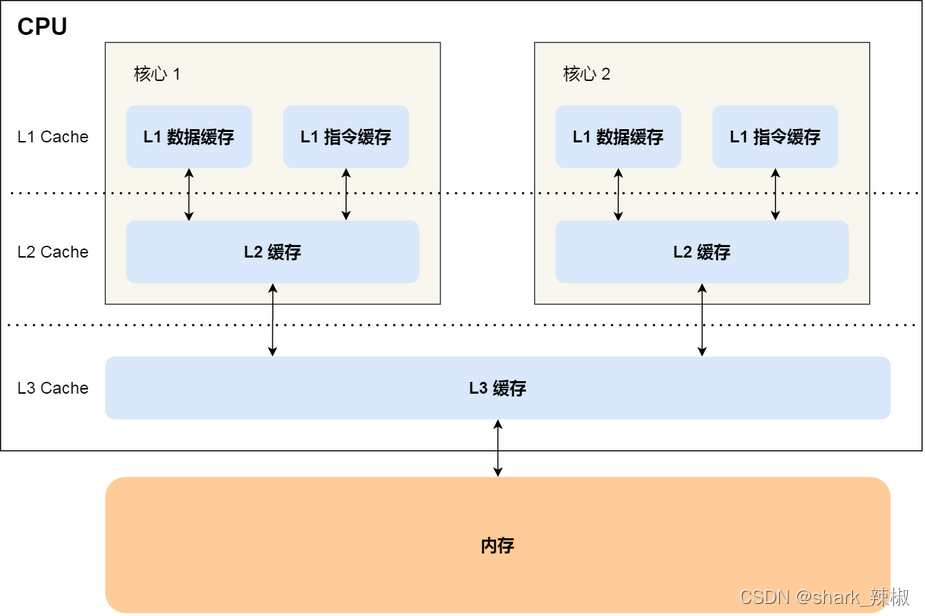
前置知识-了解以下CPU结构
如下图所示,每个CPU都会有自己的一二级缓存,其中一级缓存分为数据缓存和指令缓存,这些缓存的数据都是从内存中读取的,而且每次都会加载一个cache line,关于cache line的大小可以使用命令cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size 进行查看。

如果开发者能够很好的使用缓存技术,那么程序的性能就会很高,具体可以参照笔者之前写的这篇文章
CPU Cache和内存同步技术
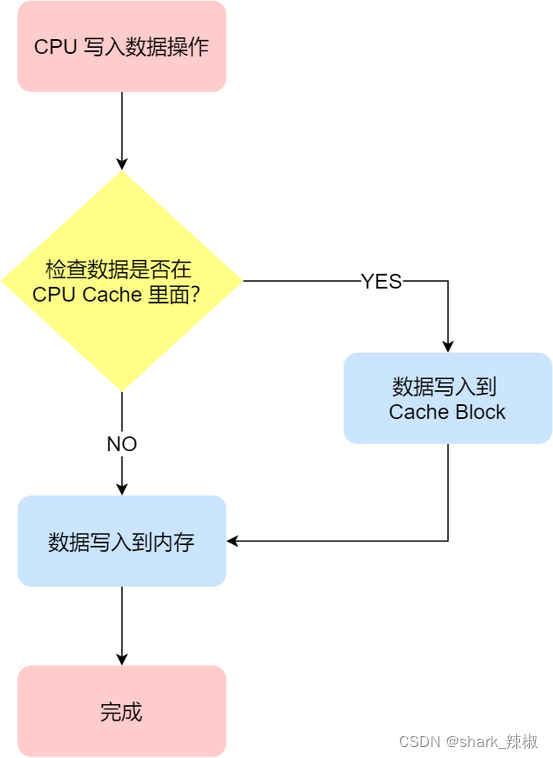
写直达(Write Through)
写直达技术解决cache和内存同步问题的方式很简单,例如CPU1要操作变量i,先看看cache中有没有变量i,若有则直接操作cache中的值,然后立刻写回内存。
若变量i不在cache中,那么CPU就回去内存中加载这个变量到cache中进行操作,然后立刻写回内存中。
这样做的好处就是实现简单,缺点也很明显,因为每次都要将修改的数据立刻写回内存。
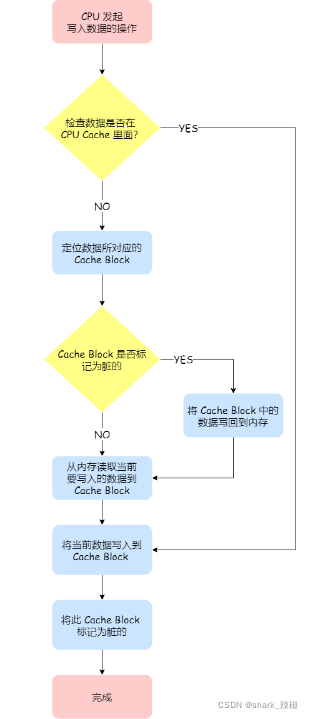
写回(Write Back)
这种方式相较于上者来说性能相对较好一些,举个例子,CPU1要修改变量i,假如变量i在cache中,在修改完之后我们就将这个Cache Block 为脏(Dirty),意味这个数据被改过了和内存不一样。但此时此刻我们不会讲数据写回内存中。
当CPU CACHE需要加载别的变量时,发现这个变量使用的cache block就是变量i的内存空间时,我们再将变量i的值写回内存中。
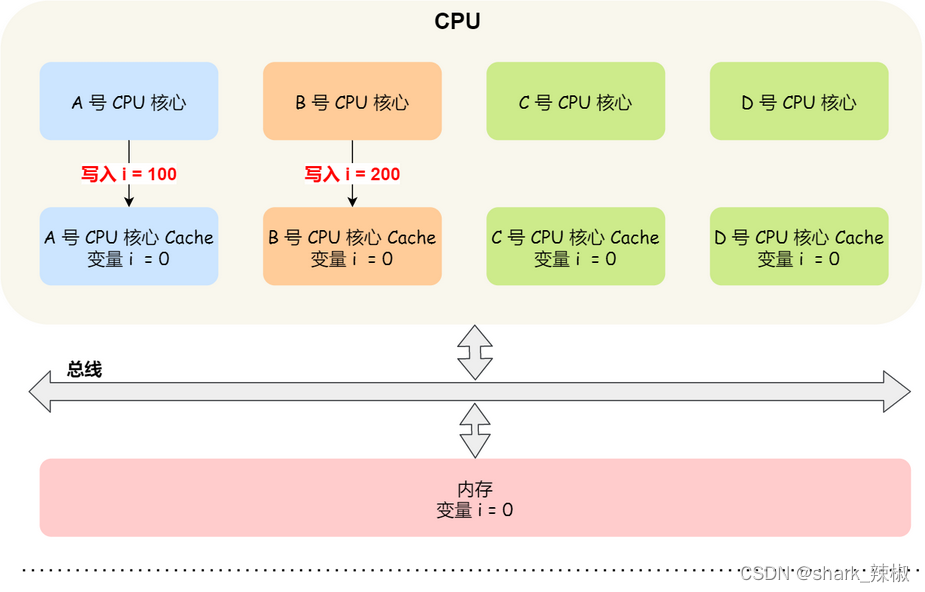
CPU缓存一致性问题(Intel处理器的实现)
由上图我们知道,当一台计算机由多核CPU构成的时候,每个CPU都从内存里加载对应的变量i(假设变量i初值为0)将其改为100,却没有写回内存。
这时候CPU2再去内存从取变量i,进行+1,因为CPU1修改的值没有写回内存,所以CPU2操作的变量i最终结果是0+1=1,这就是经典的缓存一致性问题。
而解决这个问题我们只要攻破以下两点问题即可:
- 写传播问题:即当前
Cache中修改的值要让其他CPU知道 - 事务串行化:例如
CPU1先将变量i改为100,CPU2再将基于当前变量i的值乘2。我们必须保证变量i先加100,再乘2。

解决缓存一致性问题方案1——总线嗅探(Bus Snooping)
总线嗅探是解决写传播的解决方案,举个例子,当CPU1更新Cache中变量i的值时,就会通知其他核心变量i的值被它改了,当其他CPU发现自己Cache中也有这个值的时候就会将CPU1中cache的结果更新到自己的cache中。
这种方式缺点很明显,CPU必须无时不刻监听变化,而且出现变化的数据自己还不一定有,这样的作法增加了总线的压力。
而且也不能保证事务串行化,如下图,CPUA加载了变量修改了值通知其他CPU这个值有变化了。
而CPUB也改了i的值,按照正常的逻辑CPUC、CPUD的值应该是先变为100在变为200。
但是CPUC先收到CPUB的通知先改为200再收到CPUA的通知变为100,这就导致的数据不一致的问题,即事务串行化失败。
解决缓存一致性问题方案2——MESI协议
MESI是总线嗅探的改良版,他很好的解决了总线的带宽压力,以及很好的解决了数据一致性问题。
在介绍MESI之前,我们必须了解以下MESI是什么。
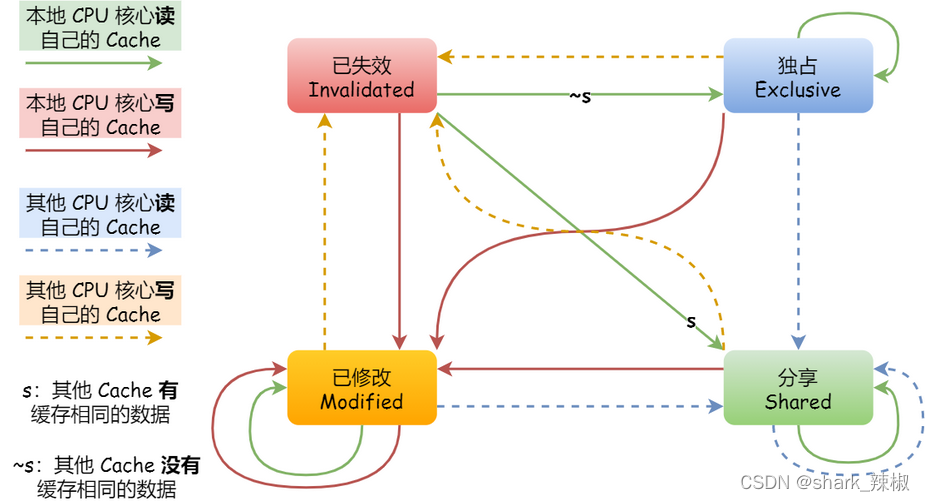
M(Modified,已修改),MESI第一个字母M,代表着CPU当前L1 cache中某个变量i的状态被修改了,而且这个数据在其他核心中都没有。E(Exclusive,独占),说白了就是CPUA将数据加载自己的L1 cache时,其他核心的cache中并没有这个数据,所以CPUA将这个数据加载到自己的cache时标记为E。(S:Shared,共享):说明CPUA在加载这个数据时,其他CPU已经加载过这个数据了,这时CPUA就会从其他CPU中拿到这个数据并加载到L1 cache中,并且所有拥有这个值的CPU都会将cache中的这个值标记为S。(I:Invalidated,已失效):当CPUA修改了L1 cache中的变量i时,发现这个值是S即共享的数据,那么就需要通知其他核心这个数据被改了,其他CPU都需要将cache中的这个值标为I,后面要操作的时,必须拿到最新的数据在进行操作。
好了介绍完这几个状态之后,我们不妨用一个例子过一下这个流程:
- CPUA要加载变量i,发现变量i不在cache中,于是去内存中捞数据,此时通过总线发个消息给其他核心,其他核心的cache中并没有这条数据,所以这个变量的cache中的状态为E(独占)。
- CPUB也加载这个数据了,在总线上发了个消息,发现CPUA有这个数据且并没有修改或者失效的标志,于是他们一起将这个变量i状态设置为S(共享)
- CPUA要改变量i值了,发消息给其他核心,其他核心收到消息将自己的变量i设置为I(无效),CPUA改完后将数据设置为M(已修改)
- CPUA又要改变量i的值了,而且看到变量i的状态为M(已修改),说明这个值是最新的数据,所以不发消息给其他核心了,直接更新即可。
- CPUA要加载新的变量x了,而且变量x要使用的cache空间正是变量i的,所以CPUA将值写回内存中,这时候内存和最新数据同步了。
将其翻译成状态机,如下所示
volatile关键字
基于JMM模型从语言级模型上了解可见性的原理
这里需要提前说明一下JMM内存模型并非我们平时所认为的内存模型,而是Java为程序员提供的抽象级别内存模型,让程序员屏蔽底层的硬件细节。
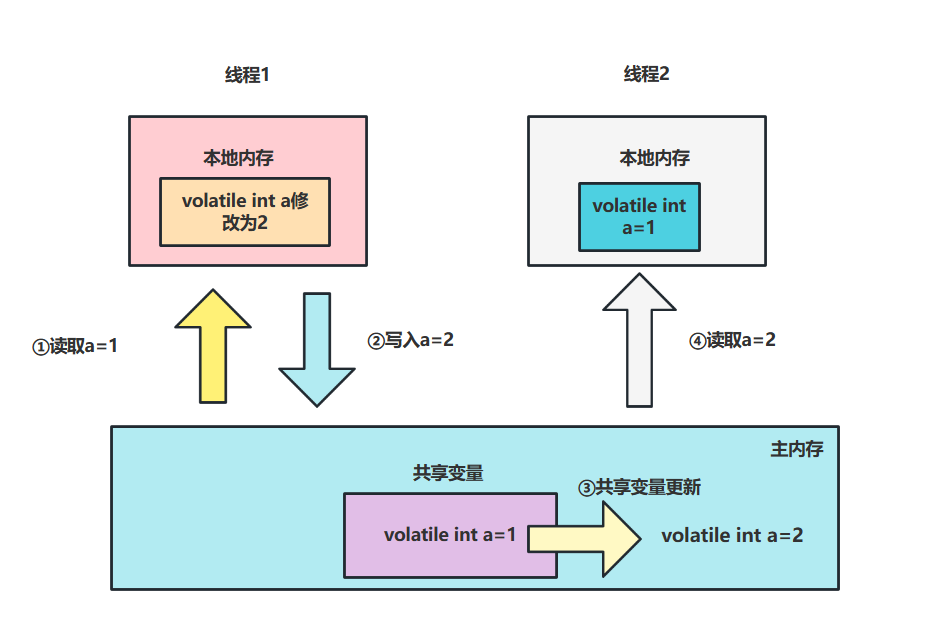
我们都知道volatile是可以保证变量可见性的,从JMM提供的抽象模型上来说,它保证可见性的方式很简单,JMM模型工作机制如下,假设我们有一个volatile共享变量a,值为1,线程1和线程2协作的操作如下
- 由于是
volatile变量,所以线程1就不会对应将本地内存设置为无效,直接从主存中获取,并加载到主存中。 - 然后线程1将值修改为2,由于需要保证可见性,所以
JMM会把这个变量写如主存中。 - 线程2读取,同样因为
volatile修饰的原因,不走本地内存,直接从主存中获取,从而保证缓存一致性。
从硬件层面理解volatile(就Intel处理器而言)
笔者上面说过了,JMM是语言级内存模型,即让程序员了解逻辑原理的内存模型,JMM规范了volatile关键字具备这种特性,真正底层是实现并非如此。
就Intel处理器而言volatile关键字就是基于我们上文所说的MESI协议。声明为volatile的变量每当被一个线程修改后,就会通知其他线程该变量状态为无效(参考上面MESI协议设置为Invalid标记),此时其他线程若需要对这个变量进行进一步操作就需要重新去主存中读取了。
当然如果是AMD可能就另当别论了。
volatile保证可见性代码示例
代码如下所示,读者可以试试看加上num变量volatile和删除volatile的效果
public class VolatileModify {
private volatile static int num = 0;
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
while (num == 0) {
//注意不要加这句话,实验会失败
// System.out.println("循环中");
}
System.out.println("num已被修改为:1" );
});
Thread t2 = new Thread(() -> {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
num++;
System.out.println("t2修改num为1" );
});
t1.start();
t2.start();
}
}
这里笔者直接给出结论,加上volatile后,这两个线程实际上会做这几件事(我们假设这两个线程在不同CPU上):
1. 线程1获取共享变量num的值,此时并没有其他核心上的线程获取,状态为E。
2. 线程2启动也获取到num的值,此时总线嗅探到另一个CPU也有这个变量的缓存,所以两个CPU缓存行都设置为S。
3. 线程2修改num的值,通过总线嗅探机制发起通知,线程1的线程收到消息后,将缓存行变量设置为I。
4. 线程1下次在读取数据是从主存中读取,所以就结束死循环。
输出结果
/**
* 加volatile关键字
* t2修改num为1
* num已被修改为:1
*/
而不加volatile,则t1无法感知改变就会一直走CPU Cache中的值,导致死循环。
/**
* 不加volatile
*t2修改num为1
*/
volatile确保禁止指令重排序
关于指令重排序可以参考笔者编写的这篇文章
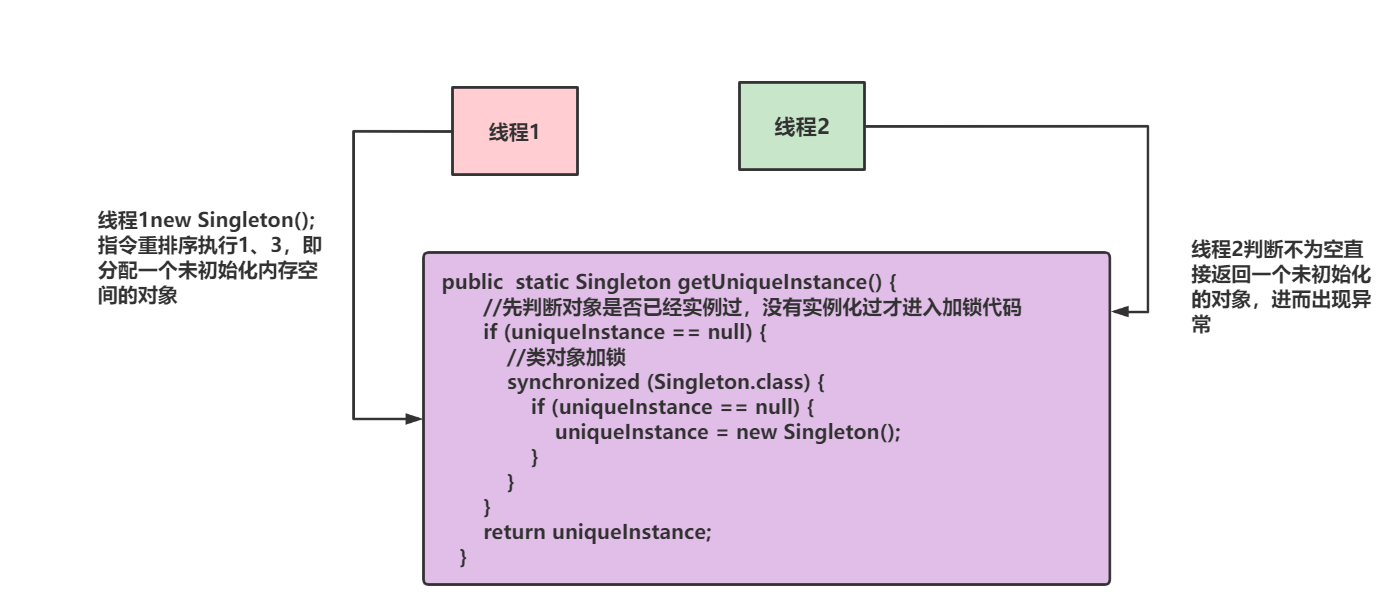
而volatile不仅可以保证可见性,还可以避免指令重排序,我们不妨看一段双重锁校验的单例模式代码,代码如下所示可以看到经过双重锁校验后,会进行new Singleton();
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
//先判断对象是否已经实例过,没有实例化过才进入加锁代码
if (uniqueInstance == null) {
//类对象加锁
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
这一操作,这个操作乍一看是原子性的,实际上编译后再执行的机器码会将其分为3个动作:
1. 为引用uniqueInstance分配内存空间
2. 初始化uniqueInstance
3. uniqueInstance指向分配的内存空间
所以如果没有volatile 禁止指令重排序的话,1、2、3的顺序操作很可能变成1、3、2进而导致一个线程执行1、3创建一个未初始化却不为空的对象,而另一个线程判空操作判定不空直接返回出去,从而导致执行出现异常。
volatile无法保证原子性
无法保证原子性代码示例
我们不妨看看下面这段代码,首先我们需要了解一下num++这个操作在底层是如何实现的:
1. 读取num的值
2. 对num进行+1
3. 写回内存中
我们查看代码的运行结果,可以看到最终的值不一定是10000,由此可以得出volatile并不能保证原子性
public class VolatoleAdd {
private static int num = 0;
public void increase() {
num++;
}
public static void main(String[] args) {
int size = 10000;
CountDownLatch downLatch = new CountDownLatch(1);
ExecutorService threadPool = Executors.newFixedThreadPool(size);
VolatoleAdd volatoleAdd = new VolatoleAdd();
for (int i = 0; i < size; i++) {
threadPool.submit(() -> {
try {
downLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
volatoleAdd.increase();
});
}
downLatch.countDown();
threadPool.shutdown();
while (!threadPool.isTerminated()) {
}
System.out.println(VolatoleAdd.num);//9998
}
}
保证原子性的解决方案
- synchronized
public synchronized void increase() {
num++;
}
- 原子类
private static AtomicInteger num=new AtomicInteger(0);
public void increase() {
num.getAndIncrement();
}
- Lock
Lock lock = new ReentrantLock();
public void increase() {
lock.lock();
try {
num++;
} finally {
lock.unlock();
}
}
你有那些场景用到了volatile嘛?
我们希望从视频中切割中图片进行识别,只要有一张图片达到90分就说明本次业务流程是成功的,为了保证执行效率,我们把截取的每一张图片都用一个线程去进行识别分数。
为了做到一张识别90分就结束任务,我们在task内部定义一个变量private CountDownLatch countDownLatch;,为了保证识别到一张图片将识别结果自增为1,我们使用了原子类private volatile AtomicInteger atomicInteger ;,可以看到,笔者为了保证原子类多线程下的可见性加了volatile。
完整代码如下
public class Task implements Callable<Integer> {
private static Logger logger = LoggerFactory.getLogger(Task.class);
private volatile AtomicInteger atomicInteger ;
private CountDownLatch countDownLatch;
public Task(AtomicInteger atomicInteger, CountDownLatch countDownLatch) {
this.atomicInteger = atomicInteger;
this.countDownLatch = countDownLatch;
}
@Override
public Integer call() throws Exception {
int score = (int) (Math.random() * 100);
logger.info("当前线程:{},识别分数:{}", Thread.currentThread().getName(), score);
synchronized (this){
}
if (score > 90 && atomicInteger.getAndIncrement()==0) {
logger.info("当前线程:{} countDown",Thread.currentThread().getName());
countDownLatch.countDown();
logger.info("当前线程:{} 返回比对分数:{}", Thread.currentThread().getName(), score);
return score;
}
return -1;
}
}
测试代码
public class Main {
private static Logger logger = LoggerFactory.getLogger(Main.class);
public static void main(String[] args) throws InterruptedException {
ExecutorService threadPool = Executors.newFixedThreadPool(100);
CountDownLatch countDownLatch=new CountDownLatch(1);
AtomicInteger atomicInteger=new AtomicInteger(0);
for (int i = 0; i < 100; i++) {
Future<Integer> task = threadPool.submit(new Task(atomicInteger,countDownLatch));
}
logger.info("阻塞中");
countDownLatch.await();
logger.info("阻塞结束");
threadPool.shutdown();
while (!threadPool.isTerminated()){
}
}
}
参考文献
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!