次梯度算法介绍
系列文章目录
最优化笔记,主要参考资料为《最优化:建模、算法与理论》
我们知道梯度下降法的前提为目标函数 f ( x ) f(x) f(x) 是一阶可微的. 在实际应用中经常会遇到不可微的函数,对于这类函数我们无法在每个点处求出梯度,但往往它们的最优值都是在不可微点处取到的. 次梯度算法不用知道每个点的梯度,转而求其次梯度,能处理函数不可微的情形.
一、次梯度
1 定义
我们知道可微凸函数 f f f 的一阶条件:
f ( y ) ≥ f ( x ) + ? f ( x ) T ( y ? x ) f(y)\geq f(x)+\nabla f(x)^{\mathrm{T}}(y-x) f(y)≥f(x)+?f(x)T(y?x)
类比可微凸函数的一阶条件,可以给出函数(不一定可微)次梯度的定义.设 f f f为适当凸函数, x ∈ d o m f x\in\mathbf{dom}f x∈domf.若向量 g ∈ R n g\in\mathbb{R}^n g∈Rn 满足
f
(
y
)
≥
f
(
x
)
+
g
T
(
y
?
x
)
,
f(y)\geq f(x)+g^{\mathrm{T}}(y-x),
f(y)≥f(x)+gT(y?x),
则称g 为函数
f
f
f 在点
x
x
x处的一个次梯度.进一步地,称集合
?
f
(
x
)
=
{
g
∣
g
∈
R
n
,
f
(
y
)
≥
f
(
x
)
+
g
T
(
y
?
x
)
,
?
y
∈
d
o
m
f
}
\partial f( x) = \{ g\mid g\in \mathbb{R} ^n, f( y) \geq f( x) + g^{\mathrm{T} }( y- x) , \forall y\in \mathbf{dom}f\}
?f(x)={g∣g∈Rn,f(y)≥f(x)+gT(y?x),?y∈domf}
为
f
f
f 在点
x
x
x 处的次微分.
由以上定义可得:
- f ( x ) + g T ( y ? x ) f(x)+g^{\mathrm{T}}(y-x) f(x)+gT(y?x)是 f ( y ) f(y) f(y)的一个全局下界.
- 如果 f f f是可微的,则 ? f ( x ) \nabla f(x) ?f(x)是 x x x处的次梯度.
可以看到次梯度的定义包含了可微和不可微的情形,通常不可微点处次梯度不止一个,如下面例所示:
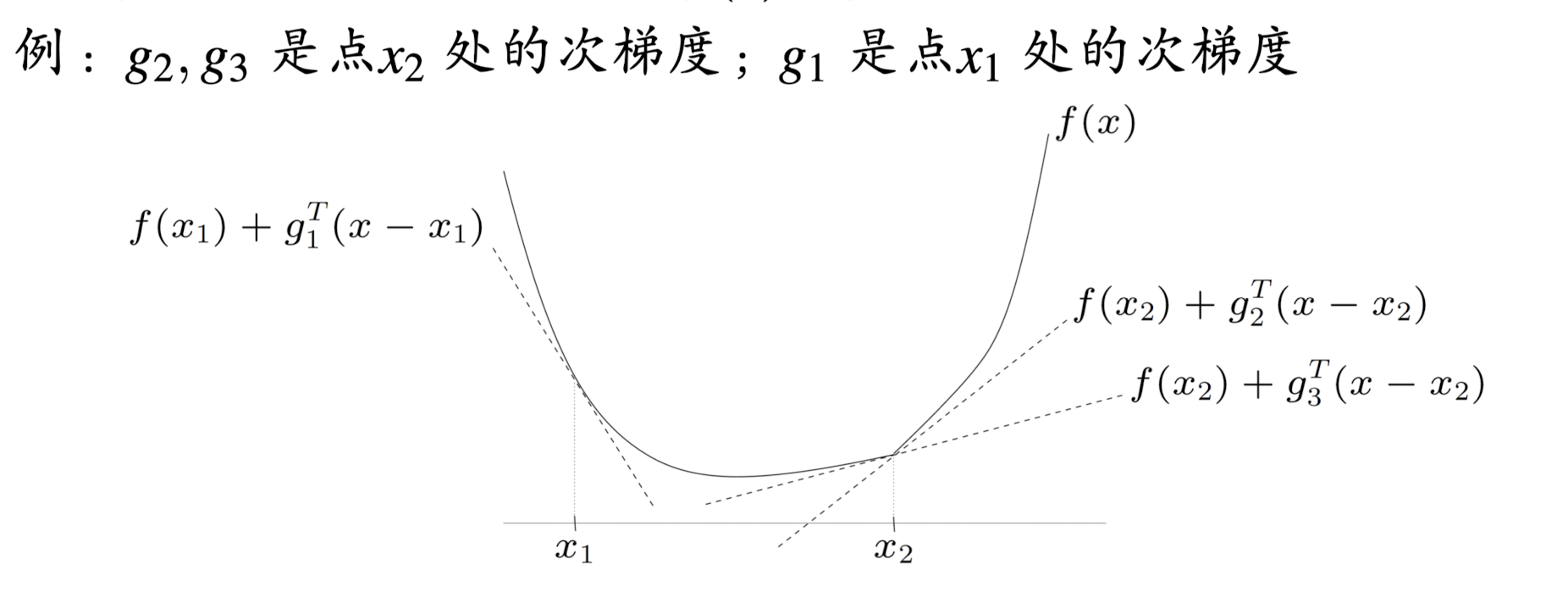
2 存在性
定理(次梯度存在性)
设 f f f为凸函数,dom f f f为其定义域,如果 x ∈ intdom ? f x\in\operatorname{int dom}f x∈intdomf, 则 ? f ( x ) \partial f(x) ?f(x)是非空的.其中 intdom ? f \operatorname{int dom}f intdomf的含义是集合dom f f f的所有内点.
- 也就是说只要是定义域中的内点,次梯度一定存在.
二、次梯度的计算
1 按定义计算
对于绝对值函数,只有在
x
=
0
x=0
x=0处不可微,用定义计算其次梯度:
f
(
y
)
≥
f
(
0
)
+
g
(
y
?
0
)
,
?
y
∈
R
?
∣
y
∣
≥
g
?
y
?
?
1
≤
g
≤
1
f(y)\geq f(0)+g(y-0),\forall y\in R \\ \Rightarrow |y| \geq g\cdot y \\ \Rightarrow -1\leq g \leq 1
f(y)≥f(0)+g(y?0),?y∈R?∣y∣≥g?y??1≤g≤1
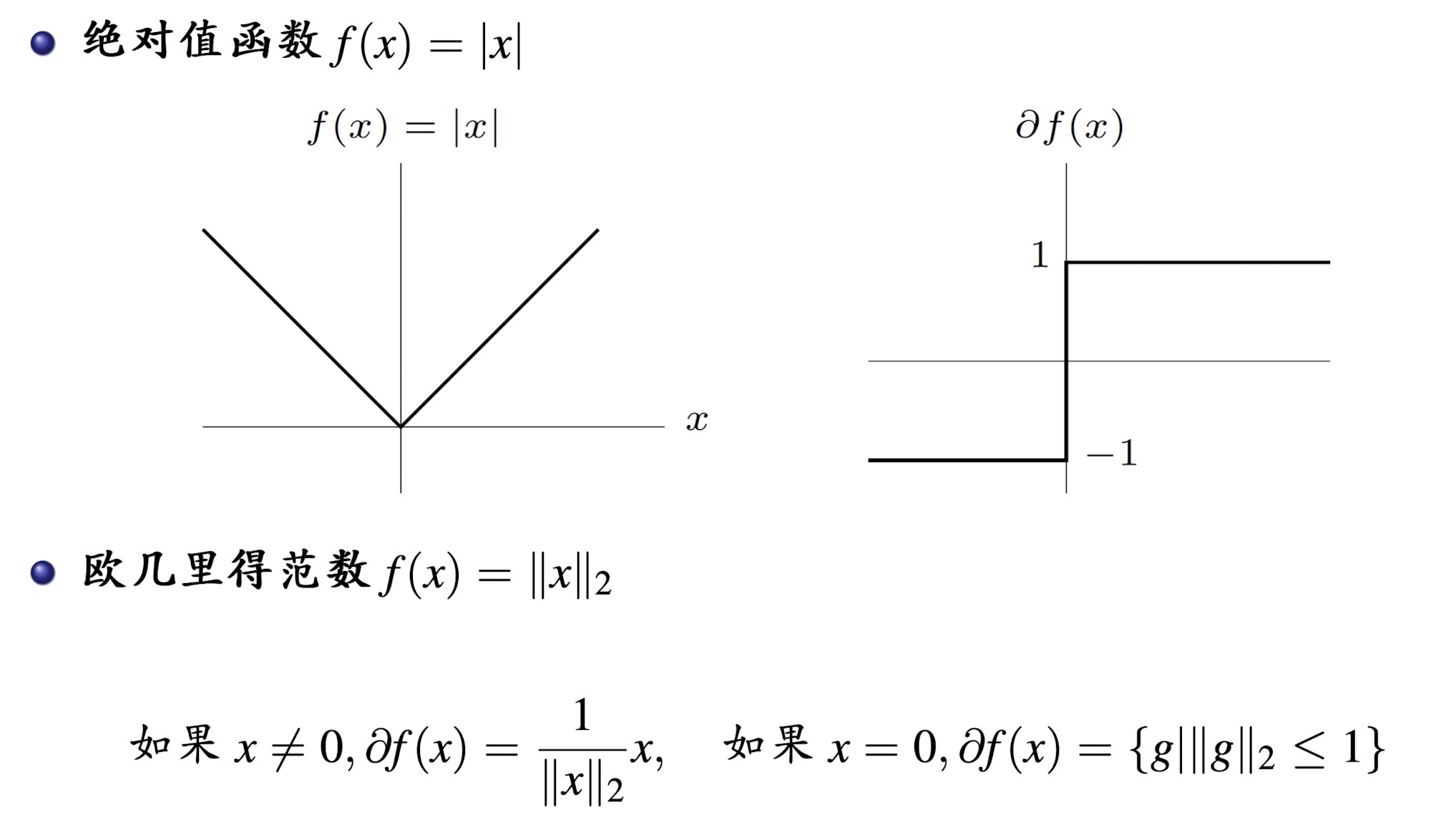

2 常用计算规则



也就是,交点处的次微分为两直线斜率的凸组合。
三、最优性条件
1 无约束优化问题
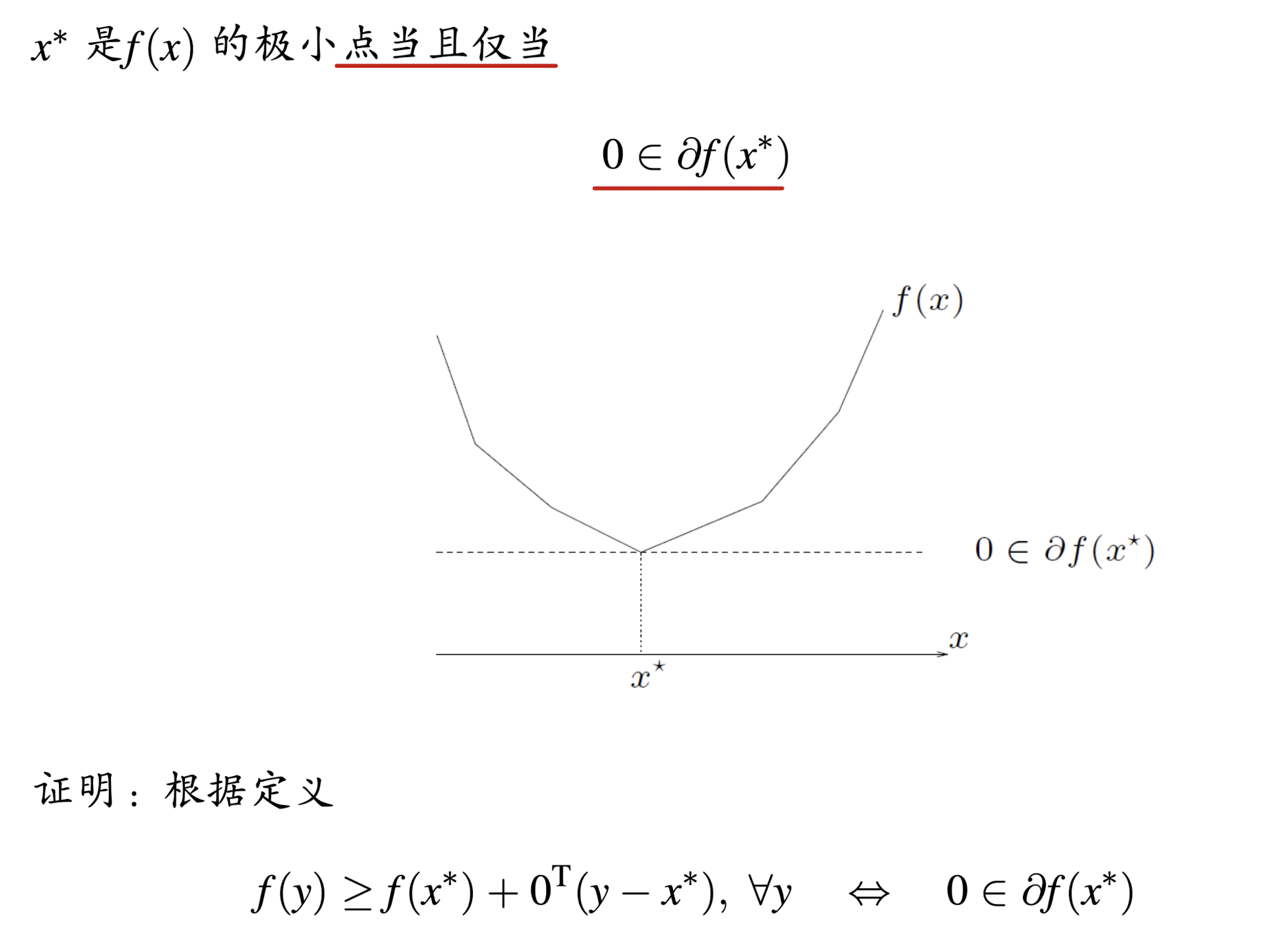
2 约束优化问题

KKT条件写出来,再加上第4条(当对偶变量固定时,拉格朗日函数去最小值)。
四、次梯度算法
1 迭代格式

- 次梯度算法不是下降方法,即无法保证 f ( x k + 1 ) < f ( x k ) f(x^{k+1})<f(x^k) f(xk+1)<f(xk).
2 收敛性
假设条件:

和梯度法不同,若
f
(
x
)
f(x)
f(x)满足上述条件,只有当
α
k
\alpha_k
αk?取消失步长时
f
^
k
\hat{f}^k
f^?k才具有收敛性,一个常用的步长取法
α
k
=
1
k
\alpha_k=\frac1k
αk?=k1?.若
∥
x
0
?
x
?
∥
≤
R
\|x^0-x^*\|\leq R
∥x0?x?∥≤R和
∥
g
i
∥
≤
G
\|g^i\|\leq G
∥gi∥≤G, 可以得到
∣
f
^
k
(
x
)
?
f
?
∣
≤
G
R
k
.
|\hat{f}^k(x)-f^*|\leq \frac{GR}{\sqrt{k}}.
∣f^?k(x)?f?∣≤k?GR?.
也就是说次梯度法收敛性为
O
(
1
k
)
O(\frac{1}{\sqrt{k}})
O(k?1?)的,相较于梯度法更慢,但是可以处理不可微的函数。
参考资料
- 刘浩洋、户将、李勇锋、文再文. 最优化:建模、算法与理论. 高教出版社, 2022.
- http://faculty.bicmr.pku.edu.cn/~wenzw/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!