Triton算法服务部署:初识与试用【Hello world】
0. 写在前面?
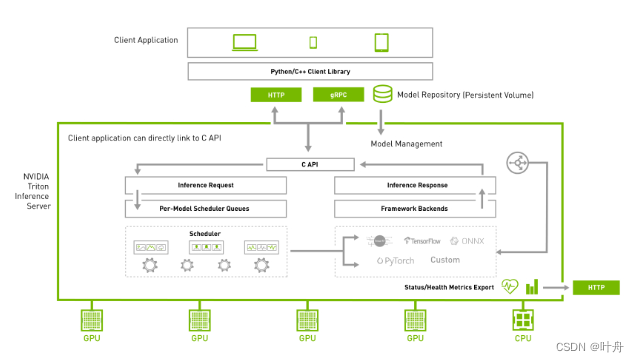
Triton Inference Server 是一款开源推理服务软件,可简化 AI 推理。其可以部署来自多个深度学习和机器学习框架的任何 AI 模型,包括 TensorRT、TensorFlow、PyTorch、ONNX、OpenVINO、Python、RAPIDS FIL 等。Triton 支持在 NVIDIA GPU、x86 和 ARM CPU 或 AWS Inferentia 上跨云、数据中心、边缘和嵌入式设备进行推理。Triton 推理服务器为许多查询类型提供优化的性能,包括实时、批量、集成和音频/视频流。
?一句话总结Triton的用法:将训练好的模型通过配置文件指定运行参数,利用Trition Server将模型部署在后台,用户可以通过接口调用算法服务获取推理结果。
这种模型部署方式其实和我们用Flask、Django、GRPC部署类似,只不过Triton提供了丰富的算法实例配置方式以及调度方式。
通过将算法推理过程服务化,我们就可以专注于模型的前后处理部分以及后续的算法逻辑内容,只在需要进行模型推理时调用一下接口即可。这种方式的好处也是显而易见的:同一种算法,只需部署一次,即可用于其他各种pipline中,提高了复用性。
举个例子,业务上有很多个需求分支,有的需要做行人跟踪,有的需要做人体属性识别,有的需要判断行人的各种行为,它们都需要一个基础模型——人体检测,这个时候,如果我们每个业务分支都实例化一个人体检测,那势必造成显存、内存等资源的浪费,而如果将其服务化,则只需每个业务分支在需要时通过接口从服务器调用一下即可。
下面,我们参考官方文档给出一个最简单的测试、试用Triton的方式。
1. Triton用法之Hello World
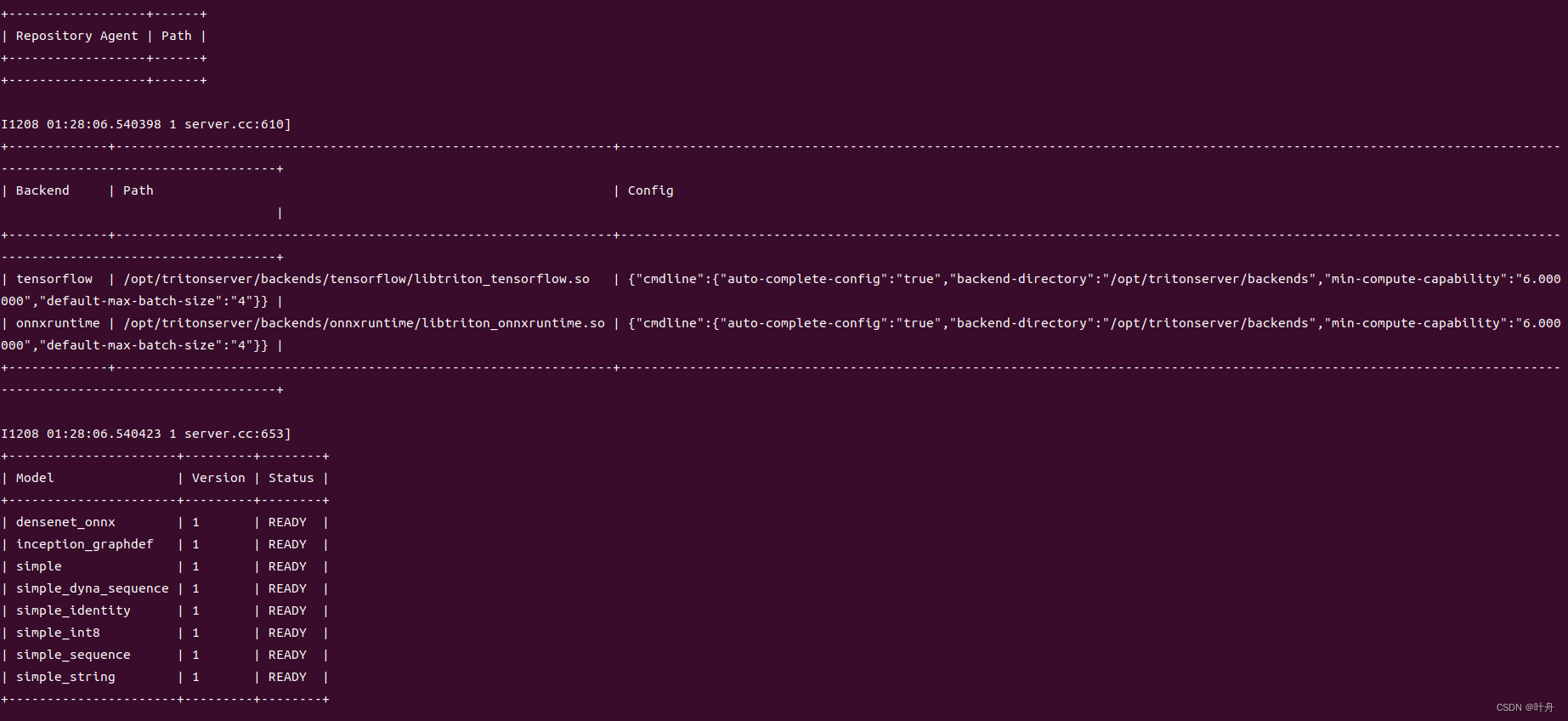
1.1 创建模型仓库
先clone 官方的Server代码:
git clone https://github.com/triton-inference-server/server.git然后进到docs/examples目录下,并下载需要的模型:
cd docs/examples
./fetch_models.sh这一步需要注意,直接运行上述脚本,可能会报无法连接SSL的错误,可以通过将脚本中的https改为http来解决:

1.2 拉取server镜像并启动服务
前置条件:需要安装好支持Nvidia GPU的docker。
先拉取Triton的Server的镜像:
# 其中的23.04可以替换为你想用的其他版本
docker pull nvcr.io/nvidia/tritonserver:23.04-py3然后即可通过命令启动Server:
# 其中的23.04可替换为其他版本,path_to_server需要改为上面clone的server的路径
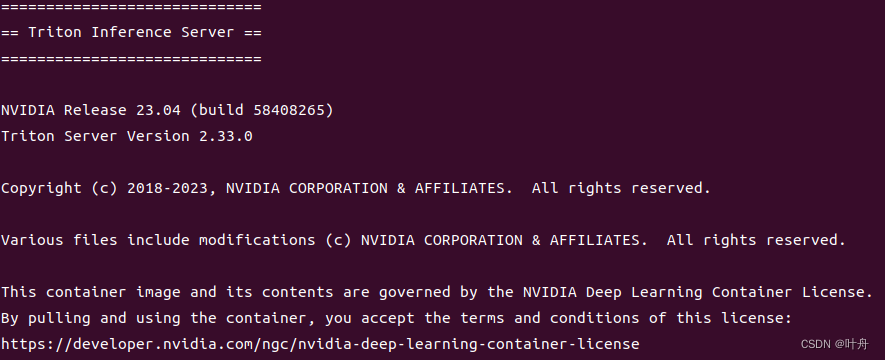
docker run --gpus=1 --rm -p8000:8000 -p8003:8003 -p8002:8002 -v path_to_server/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:23.04-py3 tritonserver --model-repository=/models启动后,看到如下内容即表示服务启动成功:

启动server后,可以通过以下命令测试一下是否能连上:
curl -v localhost:8000/v2/health/ready展示如下形式的内容,表示连接成功:

?1.3 拉取client镜像并进行测试
client这里一般都是自己写的,比如我们之前已有的一些算法推理内容中已经包含了算法的前后处理、模型推理、算法逻辑,现在只把其中的模型推理部分替换为通过Triton调用即可。
这里为了快速测试,我们使用官方提供的一个镜像:
# 其中的23.04可以替换为其他版本
docker pull nvcr.io/nvidia/tritonserver:23.04-py3-sdk拉取镜像后,启动一个容器,进入其中,并进行测试:
# 1. 进入容器
docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:23.04-py3-sdk
# 2. 执行测试
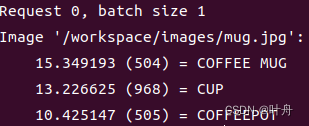
/workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg执行测试后,看到如下结果,表示测试成功(使用的图像是个马克杯,测试结果top3分别是马克杯、杯子、咖啡杯):
参考:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!