Linux内核设计与实现
Unix的历史
Unix虽然已经使用了40年,但计算机科学家仍然认为它是现存操作系统中最强大和最优秀的系统。
下面几个特点是使Unix强大的根本原因。
- Unix仅仅提供几百个系统调用并且有一个非常明确的设计目的。
- 在Unix中,所有的东西都被当做文件对待。这种抽象使对数据和对设备的操作是通过一套相同的系统调用接口来进行的:open()、read()、write()、lseek()和close()。
- Unix的内核和相关的系统工具软件是用C语言编写而成——正是这个特点使得Unix在各种硬件体系架构面前都具备令人惊异的移植能力,并且使广大的开发人员很容易就能接受它。
- Unix的进程创建非常迅速,并且有一个非常独特的fork()系统调用。
- Unix提供了一套非常简单但又很稳定的进程间通信元语,快速简洁的进程创建过程使Unix的程序把目标放在一次执行保质保量地完成一个任务上。
Linux
Linux是类Unix系统,但它不是Unix。
仅管Linux借鉴了Unix的许多设计并且实现了Unix的API(由Posix标准和其他Single Unix Specification定义的)。
内核
用户界面是操作系统的外在表象,内核才是操作系统的内在核心。
系统其他部分必须依靠内核这部分软件提供的服务,像管理硬件设备、分配系统资源等。
对于提供保护机制的现代系统来说,内核独立于普通应用程序,它一般处于系统态,拥有受保护的内存空间和访问硬件设备的所有权限。
这种系统态和被保护起来的内存空间,统称为内核空间。
相对的,应用程序在用户空间执行。
它们只能看到允许它们使用的部分系统资源,并且只能使用某些特定的系统功能,不能直接访问硬件,也不能访问内核划给别人的内存范围,还有一些使用限制。
当内核运行的时候,系统以内核态进入内核空间执行。
而执行一个普通用户程序时,系统以用户态进入用户空间。
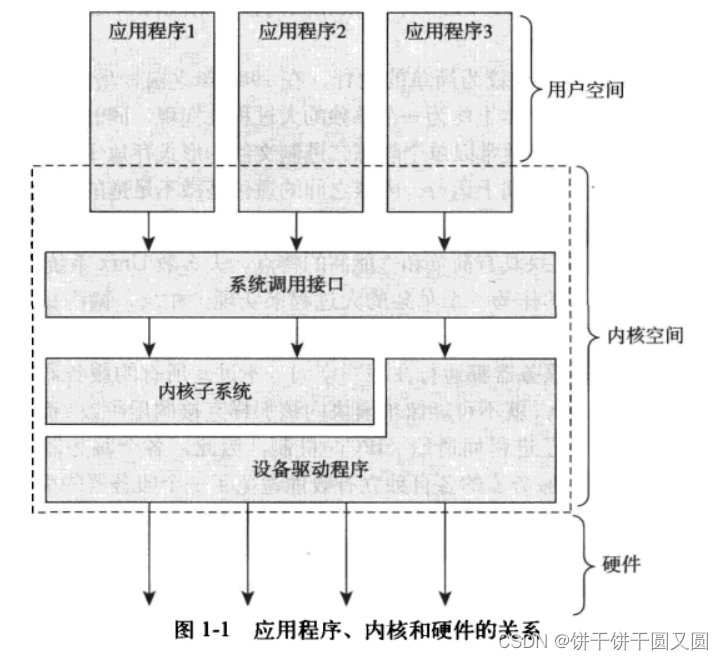
在系统中运行的应用程序通过系统调用来与内核通信。
应用程序通常调用库函数(比如C库函数),再由库函数通过系统调用界面,让内核代其完成各种不同任务。
一些库调用提供了系统调用不具备的许多功能,在那些较为复杂的函数中,调用内核的操作通常只是整个工作的一个步骤而已。
举个例子,拿printf()函数来说,它提供了数据的缓存和格式化等操作,而调用write()函数将数据写到控制台上只不过是其中的一个动作罢了。
不过,也有一些库函数和系统调用就是一一对应的关系,比如,open()库函数除了调用open()系统调用之外,几乎什么也不做。
还有一些C库函数,像strcpy(),根据不需要直接调用系统级的操作。
当一个应用程序执行一条系统调用,我们说内核正在代其执行。
如果进一步解释,在这种情况下,应用程序被称为通过系统调用在内核空间运行,而内核被称为运行于进程上下文中。
内核还要负责管理系统的硬件设备
当硬件设备想和系统通信的时候,它首先要发出一个异步的中断信号去打断处理器的执行,继而打断内核的执行。
中断通常对应着一个中断号,内核通过这个中断号查找相应的中断服务程序,并调用这个程序响应和处理中断。
举个例子,当敲击键盘的时候,键盘控制器发送一个中断信号告知系统,键盘缓冲区有数据到来。
内核注意到这个中断对应的中断号,调用相应的中断服务程序。
该服务程序处理键盘数据然后通知键盘控制器可以继续输入数据了。
为了保证同步,内核可以停用中断——既可以停止所有的中断也可以有选择第停止某个中断号对应的中断。
许多操作系统的中断服务程序,包括Linux的,都不在进程上下文中执行。它们在一个与所有进程都无关的、专门的中断上下文中运行。之所以存在这样一个专门的执行环境,就是为了保证中断服务程序能够在第一时间响应和处理中断请求,然后快速地退出。
这些上下文代表着内核活动的范围。
实际上我们可以将每个处理器在任何指定时间点上的活动必然概括为下列三者之一:

单内核与微内核设计比较
操作系统内核可以分为两大阵营:单内核和微内核。
单内核设计比较简单。
所谓单内核就是把它从整体上作为一个单独的大过程来实现,同时也运行在一个单独的地址空间上。
因此,这样的内核通常以单个静态二进制文件的形式存放于磁盘中。
所有内核服务都在这样的一个大内核地址空间上运行。
微内核的功能被划分为多个独立的过程,每个过程叫做一个服务器。
理想情况下,只有强烈请求特权服务的服务器才运行在特权模式下,其它服务器都运行在用户空间。
不过,所有的服务器都保持独立并运行在各自的地址空间上。因此,就不可能像单模块内核那样直接调用函数,而是通过消息传递处理微内核通信。
可移植性
Linux是一个可移植性非常好的操作系统,它广泛支持许多不同体系结构的计算机。
可移植性是指代码从一种体系结构移植到另外一种不同的体系结构上的方便程度。
有些操作系统在设计时把可移植性作为头等大事之一,尽可能少地涉及与机器相关的代码。
汇编代码用得少之又少,为了支持各种不同类别的体系结构,界面和功能在定义时都尽可能具有普适性和抽象性。
这么做显著的汇报就是需要支持新的体系结构时,所需完成的工作要相对容易许多。
一些移植性非常高而本身又比较简单的操作系统在支持新的体系结构时,可能只需要为此体系结构编写几百行专门的代码就行了。
与之相反,还有一种操作系统完全不顾及可移植性,它们尽最大可能追求代码的性能表现,尽可能多地使用汇编代码。
压根就是只为在一种硬件体系结构使用。内核的特性都是围绕硬件提供的特性设计的。
Linux差不多所有的接口和核心代码都是独立于硬件体系结构的C语言代码。
但是,在对性能要求很严格的部分,内核的特性会根据不同的硬件体系进行调整。
调度程序的主体程序放在kernel/sched.c文件中,用C语言编写,与体系结构无关。可是,调度程序需要进行的一些工作,比如说切换处理器上下文和切换地址空间等,却不得不依靠相应的体系结构完成。
于是,内核用C语言编写了函数context_switch()用于实现进程切换,而在它的内部,则会调用switch_to()和switch_mm()分别完成处理器上下文和地址空间的切换。
而对于Linux支持的每种体系结构,它们的switch_to()和switch_mm()实现都各不相同。
所以,当Linux需要移植到新的体系结构上的时候,只需要重新编写和提供这样的函数就可以了。
与体系结构相关的代码都放在arch/architecture/目录中。
字长和数据类型
能够由机器一次完成处理的数据称为字。
这和我们在文档中用字符(8位)和页(许多字,通常是4KB或8KB)来计量数据是相似的。
字是指位的整数数目——比如说,1,2,4,8等。
处理器通用寄存器和它的字长是相同的。
数据对齐
对齐是跟数据块在内存在的位置相关的话题。
如果一个变量的内存地址正好是它长度的整数倍,它就被称作是自然对齐的。
举例来说,对于一个32位类型的数据,如果它在内存中的地址刚好可以被4整除(也就是最低两位为0),那它就是自然对齐的。
也就是说,一个大小为2n字节的类型,它地址的最低有效位的后n位都应该为0。
一些体系结构对对齐的要求非常严格。通常像RISC的系统,载入未对齐的数据会导致处理器陷入。
还有一些系统可以访问没有对齐的数据,只不过性能会下降。编写可移植性高的代码要避免对齐问题,保证所有的类型都能够自然对齐。
结构体填补
为了保证结构体中每一个成员都能够自然对齐,结构体要被填补。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!