YOLOv8算法改进【NO.96】针对小目标检测有效果的ASF-YOLO
?前? ?言
? ? ? ?YOLO算法改进系列出到这,很多朋友问改进如何选择是最佳的,下面我就根据个人多年的写作发文章以及指导发文章的经验来看,按照优先顺序进行排序讲解YOLO算法改进方法的顺序选择。具体有需求的同学可以私信我沟通:第一,创新主干特征提取网络,将整个Backbone改进为其他的网络,比如这篇文章中的整个方法,直接将Backbone替换掉,理由是这种改进如果有效果,那么改进点就很值得写,不算是堆积木那种,也可以说是一种新的算法,所以做实验的话建议朋友们优先尝试这种改法。
第二,创新特征融合网络,这个同理第一,比如将原yolo算法PANet结构改进为Bifpn等。
第三,改进主干特征提取网络,就是类似加个注意力机制等。根据个人实验情况来说,这种改进有时候很难有较大的检测效果的提升,乱加反而降低了特征提取能力导致mAP下降,需要有技巧的添加。
第四,改进特征融合网络,理由、方法等同上。
第五,改进检测头,更换检测头这种也算个大的改进点。
第六,改进损失函数,nms、框等,要是有提升检测效果的话,算是一个小的改进点,也可以凑字数。
第七,对图像输入做改进,改进数据增强方法等。
第八,剪枝以及蒸馏等,这种用于特定的任务,比如轻量化检测等,但是这种会带来精度的下降。
...........未完待续
一、创新改进思路或解决的问题
? ? ? ?这篇CVPR顶会提出的出了一种新的基于注意尺度序列融合的YOLO框架(ASF-YOLO),该框架结合了空间和尺度特征,实现了准确快速的细胞实例分割。
二、基本原理

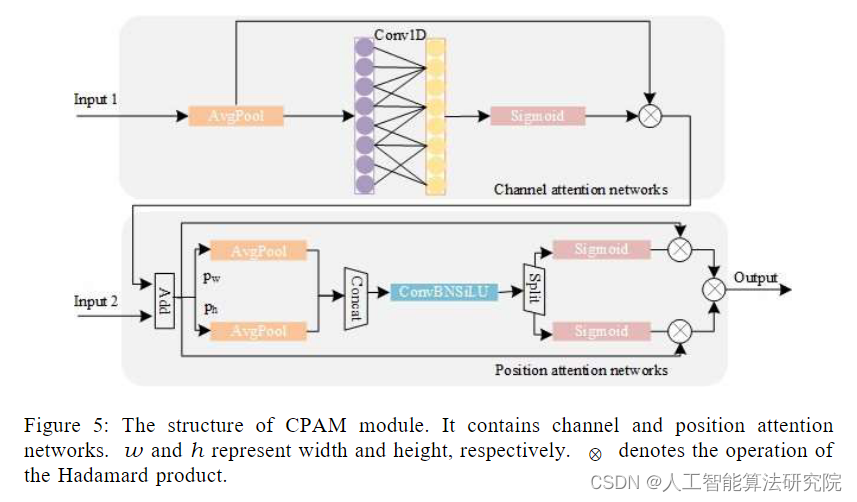
?摘要:我们提出了一种新的基于注意尺度序列融合的YOLO框架(ASF-YOLO),该框架结合了空间和尺度特征,实现了准确快速的细胞实例分割。基于YOLO分割框架,我们使用尺度序列特征融合(SSFF)模块来增强网络的多尺度信息提取能力,并使用三重特征编码器(TPE)模块来融合不同尺度的特征图以增加详细信息。我们进一步引入了一种通道和位置注意机制(CPAM)来集成SSFF和TPE模块,该模块专注于信息通道和空间位置相关的小对象,以提高检测和分割性能。在两个细胞数据集上的实验验证表明,所提出的ASF-YOLO模型具有显著的分割精度和速度。在2018年数据科学碗数据集上,它实现了0.91的盒mAP、0.887的掩码mAP和47.3 FPS的推理速度,优于最先进的方法。
?
?
三、?添加方法
部分代码如下所示,详细改进代码可私信我获取。(扣扣2453038530)
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], #10
[4, 1, Conv, [512, 1, 1]], #11
[[-1, 6, -2], 1, Zoom_cat, []], # 12 cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]], #14
[2, 1, Conv, [256, 1, 1]], #15
[[-1, 4, -2], 1, Zoom_cat, []], #16 cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]], #18
[[-1, 14], 1, Concat, [1]], #19 cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]], #21
[[-1, 10], 1, Concat, [1]], #22 cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[4, 6, 8], 1, ScalSeq, [256]], #24 args[inchane]
[[17, -1], 1, Add, []], #25
[[25, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]四、总结
预告一下:下一篇内容将继续分享深度学习算法相关改进方法。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦
PS:该方法不仅仅是适用改进YOLOv8,也可以改进其他的YOLO网络以及目标检测网络,比如YOLOv7、v6、v4、v3,Faster rcnn ,ssd等。
最后,有需要的请关注私信我吧。关注免费领取深度学习算法学习资料!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!