在极狐GitLab 上使用 DVC 实现简单机器学习
前言
之前我们已经讨论过机器学习领域的相关概念和细节(参考公众号文章?MLOps在极狐GitLab 的现状和前瞻),我们知道构建一个机器学习驱动的应用程序面临许多困难和挑战,比如:数据漂移、模型架构的变化或推理延迟等等。这些都是模型预测和质量相关的问题,更多的是算法数据科学家需要面对和处理的领域,不在本文探讨范围之内。
这里我们要讨论和介绍的是立足于极狐GitLab 的 DevOps 平台和 DVC 等工具,构建一个精简版机器学习应用的过程,包括训练数据集处理,模型训练,模型评估,模型打包,服务部署等步骤,几乎涵盖了机器学习生命周期所有阶段。
整体设计
机器学习源代码以及相关超参配置保存在极狐GitLab 的 repo 中,而训练数据集和最终生成的模型则由 DVC 管理,数据索引文件保存在当前 repo 项目,而实际数据保存在 DVC 后端配置的阿里云 OSS 中,这里没有使用具有相似功能的 LFS 而使用 DVC 的原因如下:
1. LFS对于大文件有大小限制
比如 Github 针对 Free 和 Pro 版本,其可以使用的 LFS 上限是 2GB,即使是 Enterprise Cloud 版本,最大也不超过5GB(Github LFS)。对于其他代码托管平台比如GitLab,Atlassian 也都存在一样都问题,一些 SCM 平台甚至不提供LFS服务。
对于机器学习应用来说,数据集和模型动辄十几 GB 大小,这就远远超出了 LFS 的能力范围,这使得LFS无法真正用于机器学习应用的构建。
2. LFS无法选择后端存储平台
对于提供 LFS 的代码托管平台来说,使用什么后端存储是由这些平台决定的,比如极狐GitLab就使用腾讯云的 OSS 作为 LFS 存储平台。
对于机器学习来说,训练数据集和模型的存储位置需要根据实际情况由用户来决定,比如使用 Google driver, HDFS 或者本地存储等等,即使 LFS 可以支持这些后端存储,但无法动态更改,灵活性较差。
而使用 DV C就没有上述限制,同LFS一样,较大的训练数据集和模型保存在 DVC 的远端存储中,GIT 的 repo 中仅仅保存上述存储的“元数据”,我们可以理解为“引用”,这些“元数据”可以和机器学习源代码作为一个整体实现版本控制。
而保存实际数据的后端存储,不受代码托管平台限制,DVC 支持多种后端存储平台,比如:Amazon S3,AliCloud OSS,HDFS, SSH,Local storage 等等,足以支持绝大部分使用场景和需求,而可以支持的文件大小,完全在于后端存储的具体配置。
这里DVC和GIT整合使用的场景,可以用下图表示:
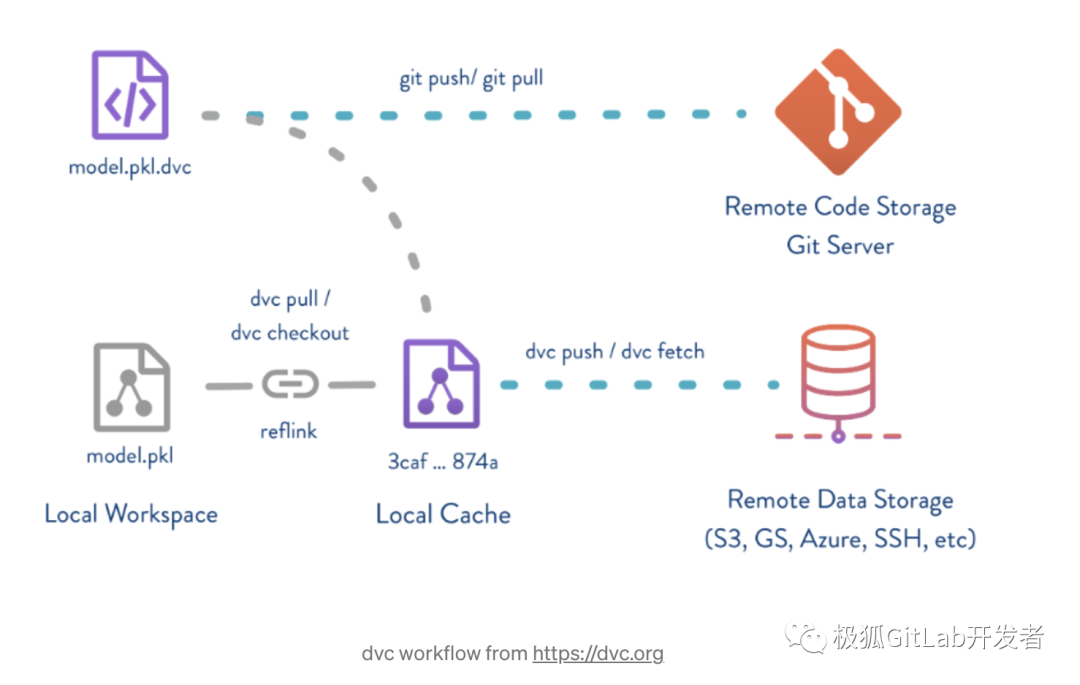
更多关于 DVC 的资料和用法,可以参见官网。
本示例机器学习项目会基于如下几个设计原则:
-
DVC 中创建 2 个阿里云 OSS 的远端存储,分别保存训练数据集和模型,并且训练数据集已经上传保存好。
-
项目的Pipeline使用自定义 Runner 运行所有 job,主要是出于安全和效率方面考虑。比如:数据安全,获取训练数据便捷性,模型训练时间等等。
-
基于当前分支代码构和数据建出模型后,其评估结果会显示在 MR 的 Comments中供 reviewer 参考,进而决定模型可用还是需要继续训练优化。
-
通过评估的模型会在被打包为镜像,此外还会被保存在 DVC 的远端存储中,确保repo 中保存的永远是完整的版本一致的机器学习应用。
-
模型部署阶段会从极狐GitLab 的 registry 中拉取指定镜像,为了简化流程,会直接将模型部署在当前 Runner 所在主机,模型预测会从训练测试数据集中随机抽取数据调用这个服务进行预测。
-
任何分支上源代码/训练数据集的更改都会触发模型训练。
整体流程可以用下图表示:
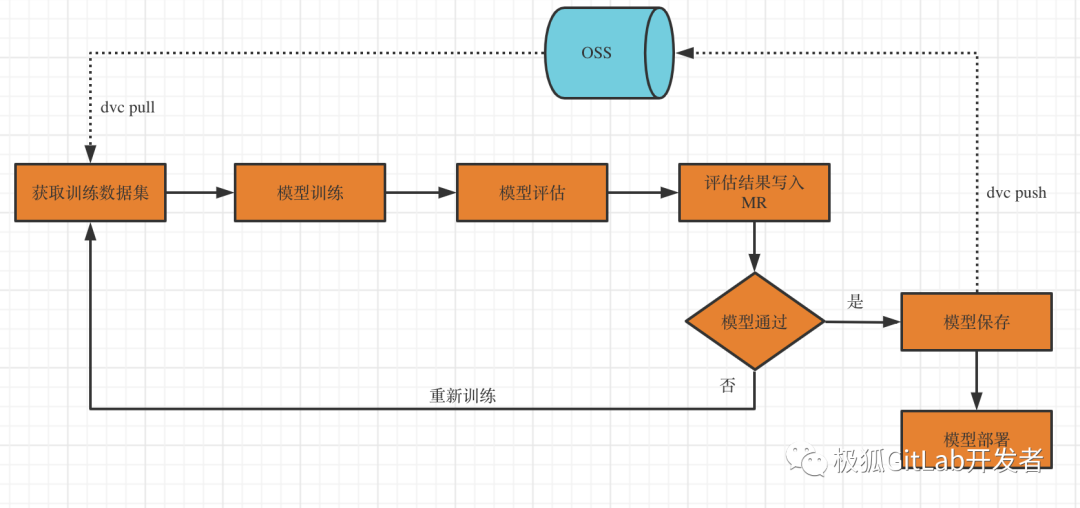
项目实现
本示例项目位于:https://gitlab.cn/mlops/demo
代码介绍
-
train.py
从本地指定目录中读取训练数据集,进行数据过滤后训练模型,最终模型保存在 artifact 指定目录中(model/),供后续stage使用
-
eval.py
从指定目录中读取 train 阶段训练的模型,使用训练集的测试数据进行评估,模型评估结果保存在artifact指定目录中(model/eval),后续 stage 会通过?CML 将模型评估结果发送到对应 MR 的 comments 中。
-
inference_client.py
从训练集测试数据中随机抽取数据,调用 deploy 阶段部署的 fashion-mnist 模型服务进行预测,预测结果直接输出在命令行。
-
.dvc/
dvc 配置目录,保存 dvc 的相关配置信息,比如 remote storage。本实例中用到 2 个remote storage:ossremote_traindata 和 ossremote,分别保存模型训练数据集和模型。
注意:这里有用到阿里云 OSS 的 credential 信息(accesskey和secretkey),这些信息会保存在 .dvc/config.local 中,但该文件并不存储在 repo 中,需要在运行中通过 dvc 命令再做配置。
-
model/
保存最终训练的模型 .dvc 文件,此外,该目录还作为artifact 目录,在 pipeline 的不同 job 中共享临时生成的模型数据。
-
train_data/
保存模型训练数据集的 .dvc 文件,此外,该目录作为artifact 目录,在 pipeline 的不同 job 中共享模型数据训练数据集。
Pipeline
本示例的 pipeline 主要有如下几个自定义stage:
-
train
基于当前 branch,通过 dvc 命令从 ossremote_traindata 这个 remote storage 中拉取模型训练数据集到本地。
从本地 load 训练数据集并训练出模型。
-
eval
使用训练测试数据集,评估 train 阶段生成的模型,并生成评估结果文件。
将评估结果文件通过 CML 发送到 MR 的 comments 中。
-
build
构建一个基于模型的 docker 镜像,并保存到极狐GitLab 的 registry 中。
-
deploy
通过 dvc 命令,将基于当前 branch 代码和训练集生成的模型 push 到 ossremote 这个 remote storage 中,并将. dvc 文件保存到当前 repo。
从极狐GitLab 的 registry 拉取镜像,并部署这个模型评估服务。
-
inference
使用模型测试数据集的随机数据,调用 deploy 阶段的模型评估服务进行预测。
配置
-
阿里云OSS
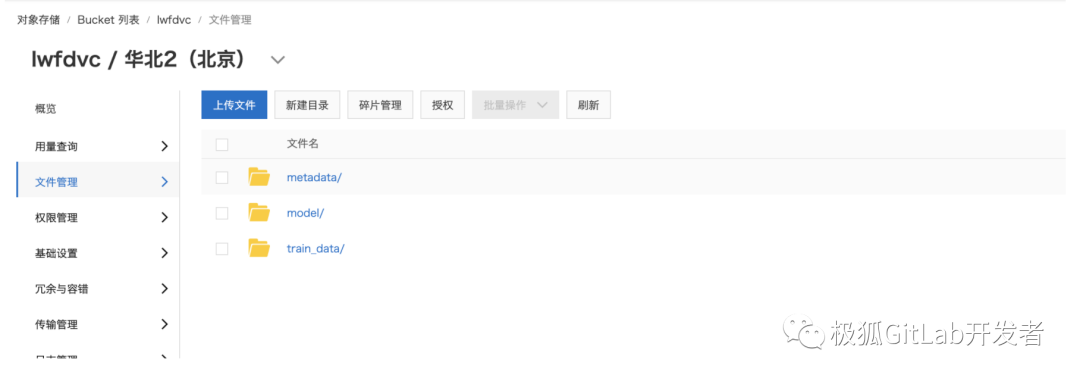
在本示例中 DVC 使用阿里云的 OSS 作为后端存储,保存相对比较大的模型训练数据和最终生成的模型,这里我们使用北京 region 中的 lwfdvc 这个 bucket 下的两个不同目录来保存上述两种数据,如下所示:
-
lwfdvc/model 保存不同版本的训练模型。
-
lwfdvc/train_data 保存不同版本的模型训练数据集。这里就是保存 fashion-mnist 的 60000 个训练数据和10000 个测试数据,下载地址位于?data。
-
?CI/CD variable
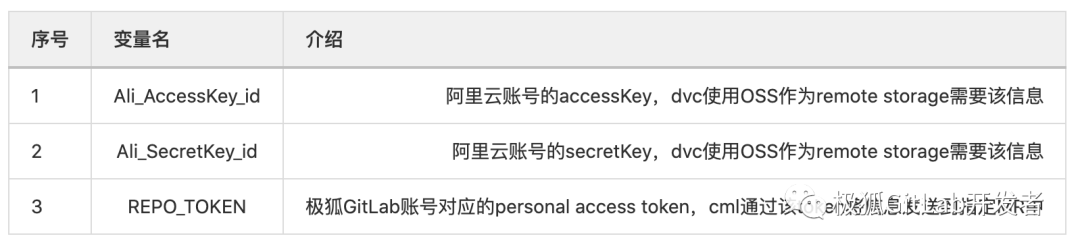
注意:上述变量推荐开启 Masked 功能。
运行示例
更改main分支上代码,以触发模型训练机制。
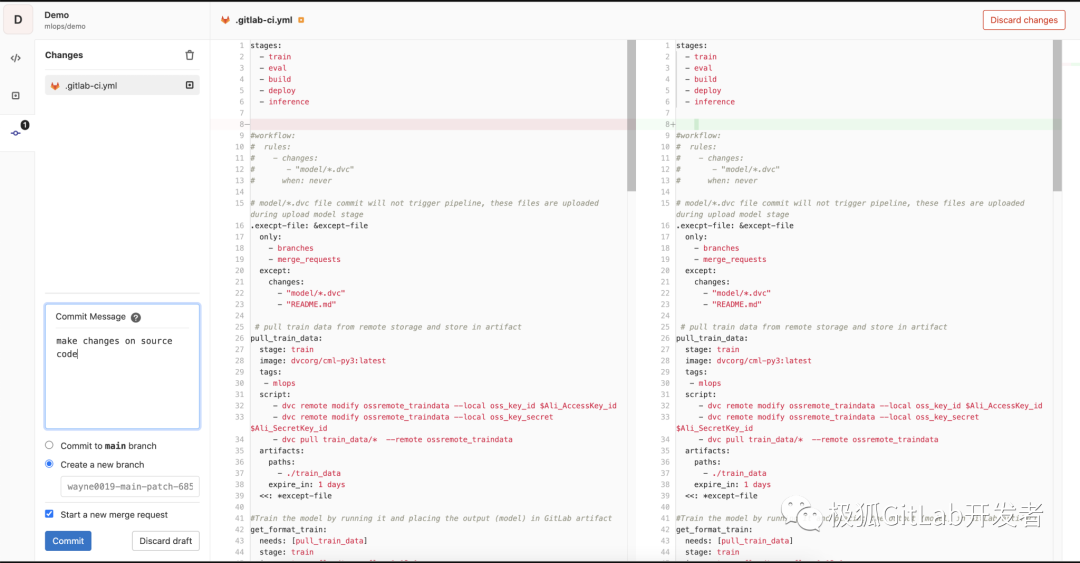
-
首先,为需要做的更改创建一个MR,随后会触发Merge Request Pipeline流程。
注意:这里一定要有MR,这是DevOps推荐的正规工作流程,同时,也为后续模型评估结果的展示提供便利。
如果没有MR,那么接下来的 Merge Request Pipeline 也不会被触发。
-
触发 Pipeline for Merge Request 流程。
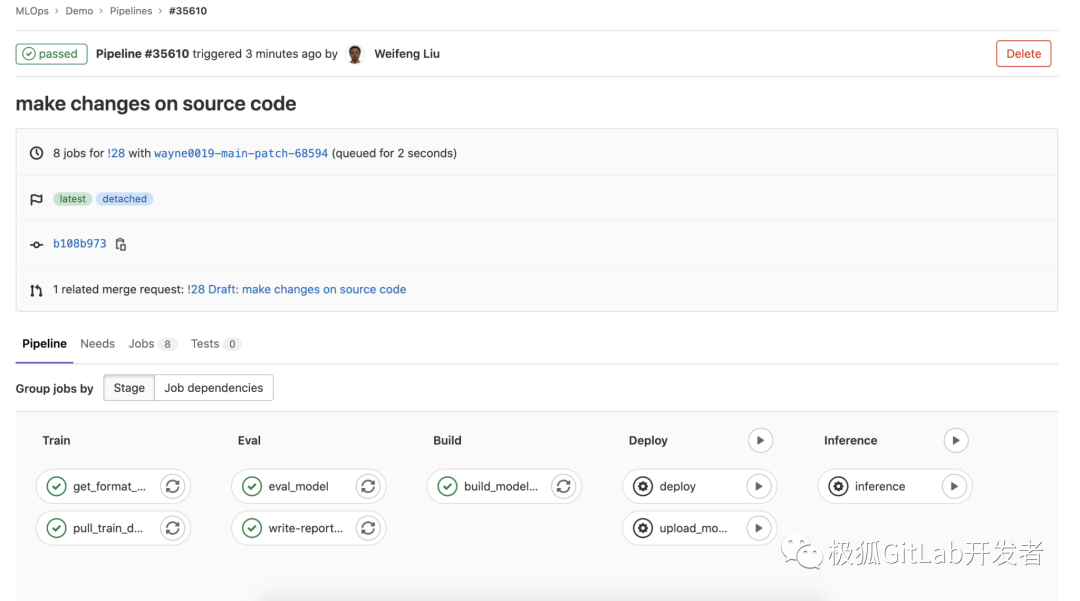
模型的训练,评估和构建会自动完成,后续的部署和预测需要手动触发,由于此时模型评估结果我们还不知道,所以 “Deploy”?和?“Inference” 可以不执行。
模型评估的 “write-report-mr” 这个 job 会将当前模型的评估结果写回到 MR 的 comments 中,如下所示:
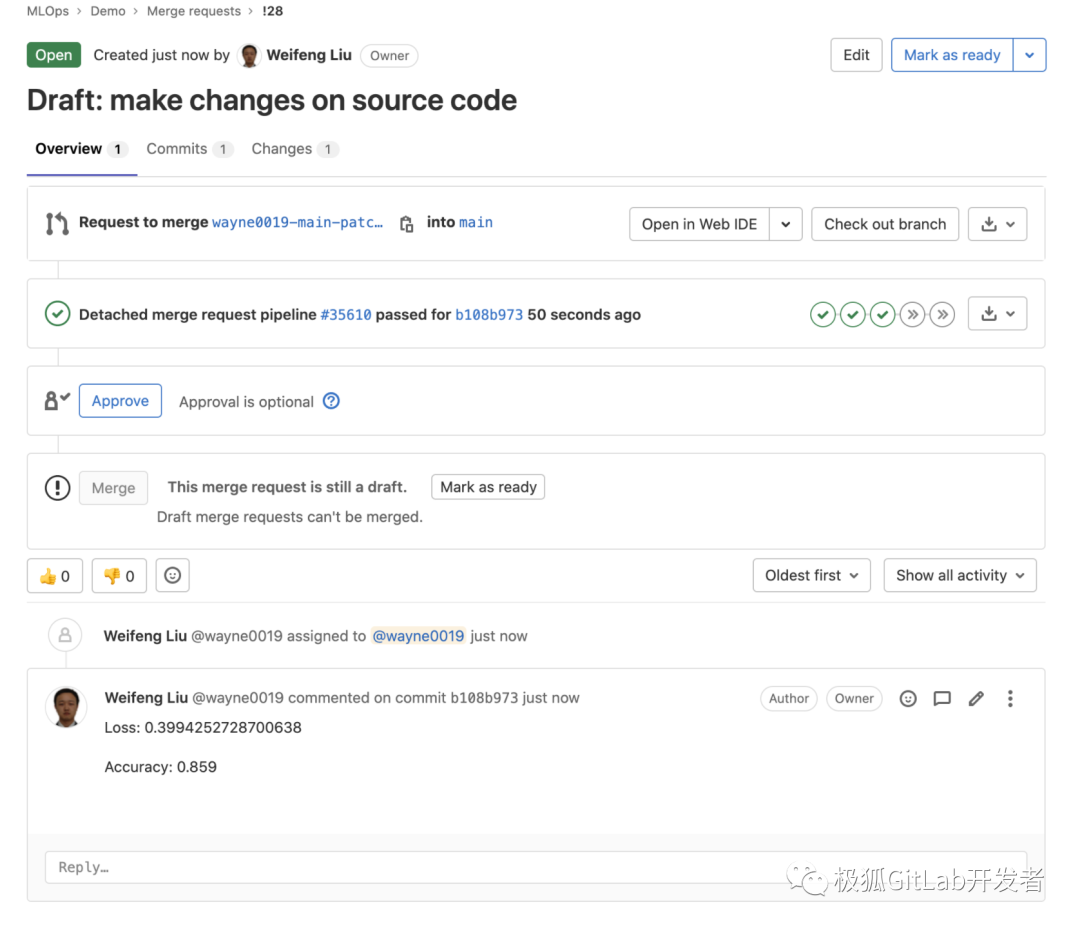
MR的 reviewer 可以根据模型评估结果来决定是否 approval 这个MR。
-
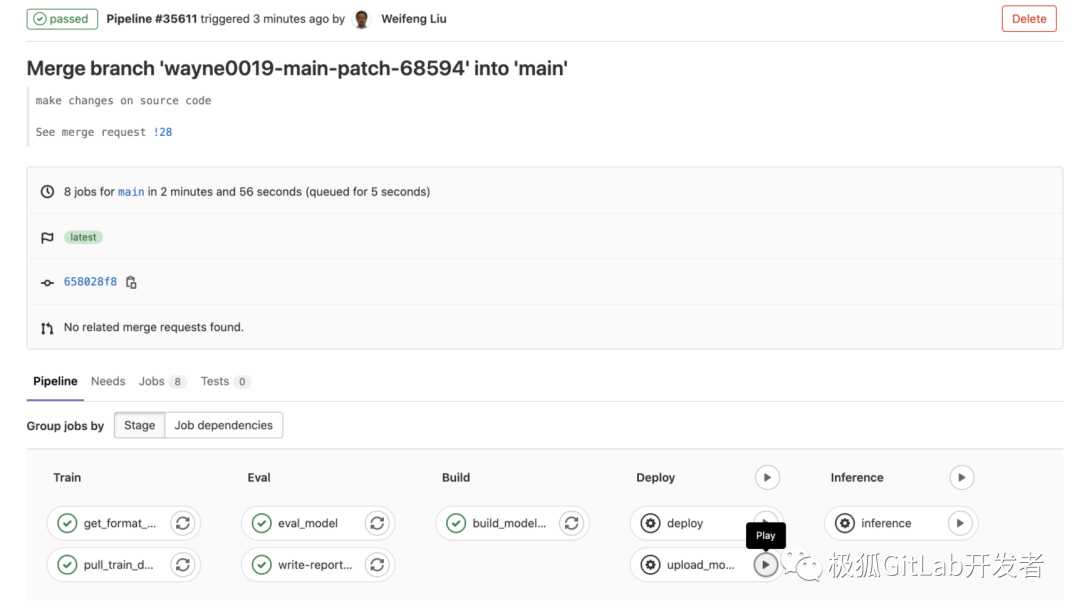
MR被 approval,更改被 merge 到 main 分支,再次触发 Pipeline 流程。
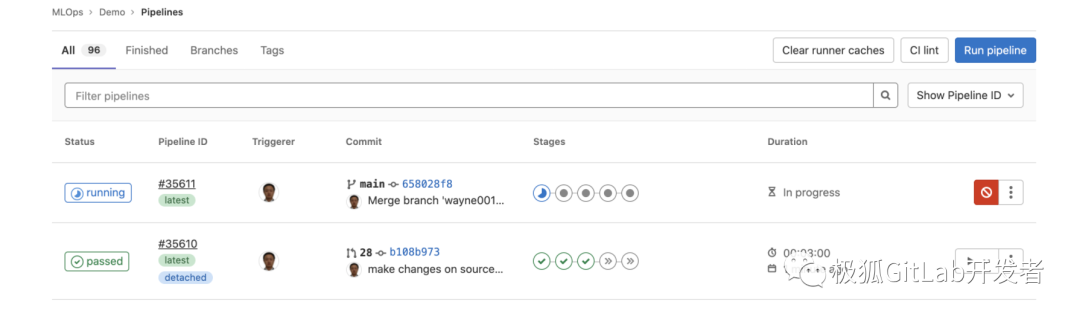
此时 main 分支上生成的模型是符合我们预期的,手动触发“upload_model_dvc”任务,将这个模型(model/fashion-mnist)上传到OSS中,同时,本地 repo 仅仅保存 “.dvc” 后缀的模型引用文件(model/fashion-mnist.dvc)。
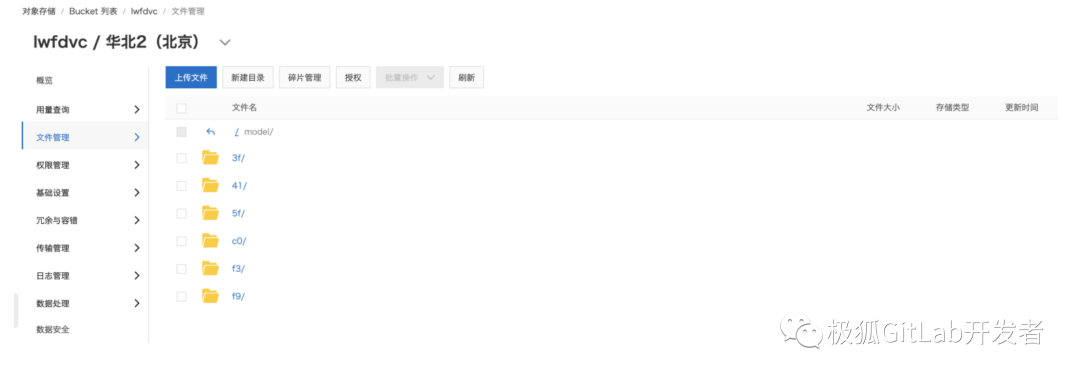
这个 “.dvc” 后缀的模型引用文件内容很简单,仅仅记录了文件的路径,大小和哈希值,内容如下:
outs:
- md5: f39e8ebadd2ede11763b440eb5f24204
size: 69328
path: fashion-mnist打开阿里云 OSS 目录,可以从 lwfdvc/model 目录下找到这个刚刚上传的模型文件,文件夹名字就是上面 dvc文件中的md5值前缀,就是 f3 目录:
-
部署和使用模型服务
手动触发执行 deploy 和 inference 任务,从当前项目的容器仓库中拉取模型镜像,然后部署在 runner 所在主机,并调用预测服务。
至此,基于 main 分支的代码更改和模型训练/评估/部署流程完成。上述过程对于其他分支同样适用。
后续改进
1.?模型版本管理缺少图形化显示,不够直观
当前解决方案虽然实现了数据集和模型与源代码的统一管理,实际模型是保存在阿里云的OSS中,但这些模型的保存方式无法定制化,不能方便的查看版本和其他信息。
解决办法是引入 model registry,即模型仓库。很多开源或者商业机器学习平台都提供有模型仓库,比如 MLFlow,Comet 等,可以以 REST 或者 Webhook 等方式整合这些服务,然后数据集仍然使用 DVC 管理,生成的模型通过评估后,上传保存到指定的模型仓库中,需要注意的是:此时要确保这个模型的版本与当前代码和数据集一致!
2.?部署后的模型服务缺少监控和重训机制
示例中的机器学习应用构建过程在模型通过评估部署后,没有对当前模型性能提供监控,也就是缺少 “CT” 阶段,即持续训练。
一般情况下,模型在运行期性能下降是由于外部环境发生较大变化导致,比如运行环境变更,输入数据超出预期等,使得当前模型无法适应新的数据环境,此时需要根据实际情况采用如下三种复杂度递增的处理方法:
-
重新训练模型
-
依据当前环境,调整训练数据集和超参配置,然后再次触发模型训练
-
调整模型算法,这需要算法数据科学家参与
模型的监控和重训同样是一个复杂重要的过程,我们会在后续文章提及这个话题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!