处理urllib.request.urlopen报错UnicodeEncodeError:‘ascii‘
2023-12-27 14:57:32
参考:[Python3填坑之旅]一·urllib模块网页爬虫访问中文网址出错
目录
六、其他UnicodeEncodeError: 'ascii' codec 问题
一、报错内容
UnicodeEncodeError: 'ascii' codec can't encode characters in position 22-23: ordinal not in range(128)
二、报错截图

三、解决方法
字母、数字和?'_.-~'?等字符一定不会被转码。 在默认情况下,此函数只对 URL 的路径部分进行转码。 可选的?safe?形参额外指定不应被转码的 ASCII 字符,其默认值为?'/'。--Python官方文档
1、urllib解析含中文的url时,单独编码中文部分,最后拼接
# -*- coding: UTF-8 -*-
from urllib import request, error, parse
city = '徐州'
city = parse.quote(city) # urllib处理中文,需要编码
url = 'https://***.***.com/api?city={}'.format(city)? 2、直接对url整体中的中文进行编码,默认不对/字母编码,但会对url中的:=?空格等编码
url = 'https://***.***.com/api?city=徐州'
url = parse.quote(url, safe='/:=?') # urllib处理中文,需要编码四、实例代码
1、单独处理中文编码
# -*- coding: UTF-8 -*-
from urllib import request, error, parse
city = '徐州'
city = parse.quote(city) # urllib处理中文,需要编码
url = 'https://***.***.com/api?city={}'.format(city)
response = request.urlopen(url)
print(response.read().decode('utf-8'), response.getheader('Server'))?2、处理整体url
# -*- coding: UTF-8 -*-
from urllib import request, error, parse
url = 'https://***.***.com/api?city=徐州'
url = parse.quote(url, safe='/:=?') # urllib处理中文,需要编码
response = request.urlopen(url)
print(response.read().decode('utf-8'), response.getheader('Server'))五、运行截图
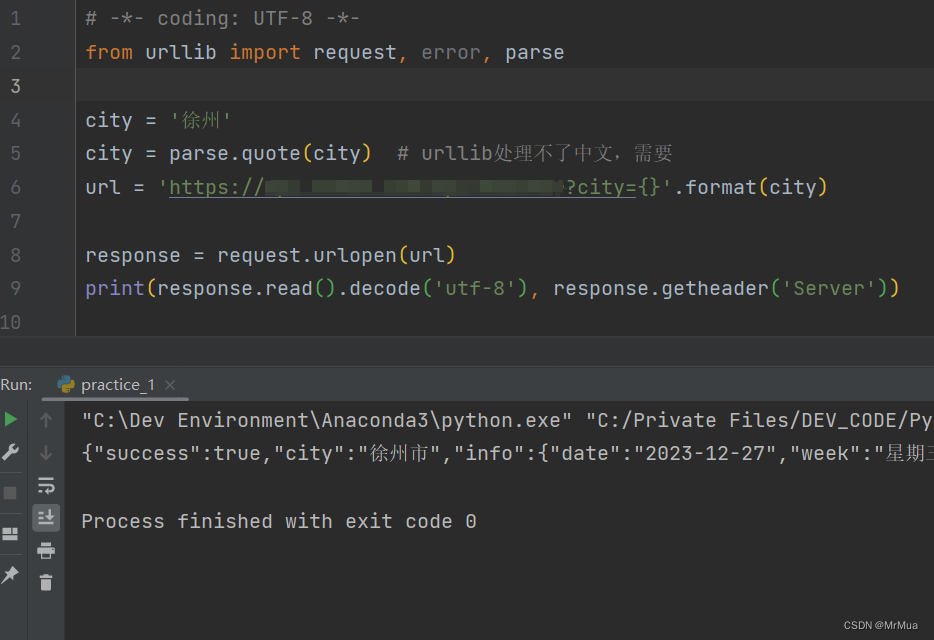
六、其他UnicodeEncodeError: 'ascii' codec 问题
参考:
文章来源:https://blog.csdn.net/qq_39136872/article/details/135240091
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!