Agent Attention:以一种优雅的方式来结合线性注意力和softmax注意力

论文链接:https://arxiv.org/abs/2312.08874
代码地址:https://github.com/LeapLabTHU/Agent-Attention
1. 简介
????近年来,视觉 Transformer 模型得到了极大的发展,相关工作在分类、分割、检测等视觉任务上都取得了很好的效果。然而,将 Transformer 模型应用于视觉领域并不是一件简单的事情。与自然语言不同,视觉图片中的特征数量更多。由于 Softmax 注意力是平方复杂度,直接进行全局自注意力的计算往往会带来过高的计算量。针对这一问题,先前的工作通常通过减少参与自注意力计算的特征数量的方法来降低计算量。例如,设计稀疏注意力机制(如 PVT)或将注意力的计算限制在局部窗口中(如 Swin Transformer)。尽管有效,这样的自注意力方法很容易受到计算模式的影响,同时也不可避免地牺牲了自注意力的全局建模能力。
????与 Softmax 注意力不同,线性注意力将 Softmax 解耦为两个独立的函数,从而能够将注意力的计算顺序从 (query?key)?value 调整为 query?(key?value),使得总体的计算复杂度降低为线性。然而,目前的线性注意力方法效果明显逊于 Softmax 注意力,难以实际应用。
????注意力模块是 Transformers 的关键组件。全局注意力机制具良好的模型表达能力,但过高的计算成本限制了其在各种场景中的应用。本文提出了一种新的注意力范式,代理注意力 (Agent Attention),同时具有高效性和很强的模型表达能力。
????具体来说,代理注意力在传统的注意力三元组 (Q,K,V) 中引入了一组额外的代理向量 A,定义了一种新的四元注意力机制 (Q, A, K, V)。其中,代理向量 A 首先作为查询向量 Q 的代理,从 K 和 V 中聚合信息,然后将信息广播回 Q。由于代理向量的数量可以设计得比查询向量的数量小得多,代理注意力能够以很低的计算成本实现全局信息的建模。
????此外,本文证明代理注意力等价于一种线性注意力范式,实现了高性能 Softmax 注意力和高效线性注意力的自然融合。该方法在 ImageNet 上使 DeiT、PVT、Swin Transformer、CSwin Transformer 等模型架构取得了显著的性能提升,能够将模型在 CPU 端加速约 2.0 倍、在 GPU 端加速约 1.6 倍。应用于 Stable Diffusion 时,代理注意力能够将模型生成速度提升约 1.8 倍,并显著提高图像生成质量,且无需任何额外训练。
2. Agent Attention设计方式
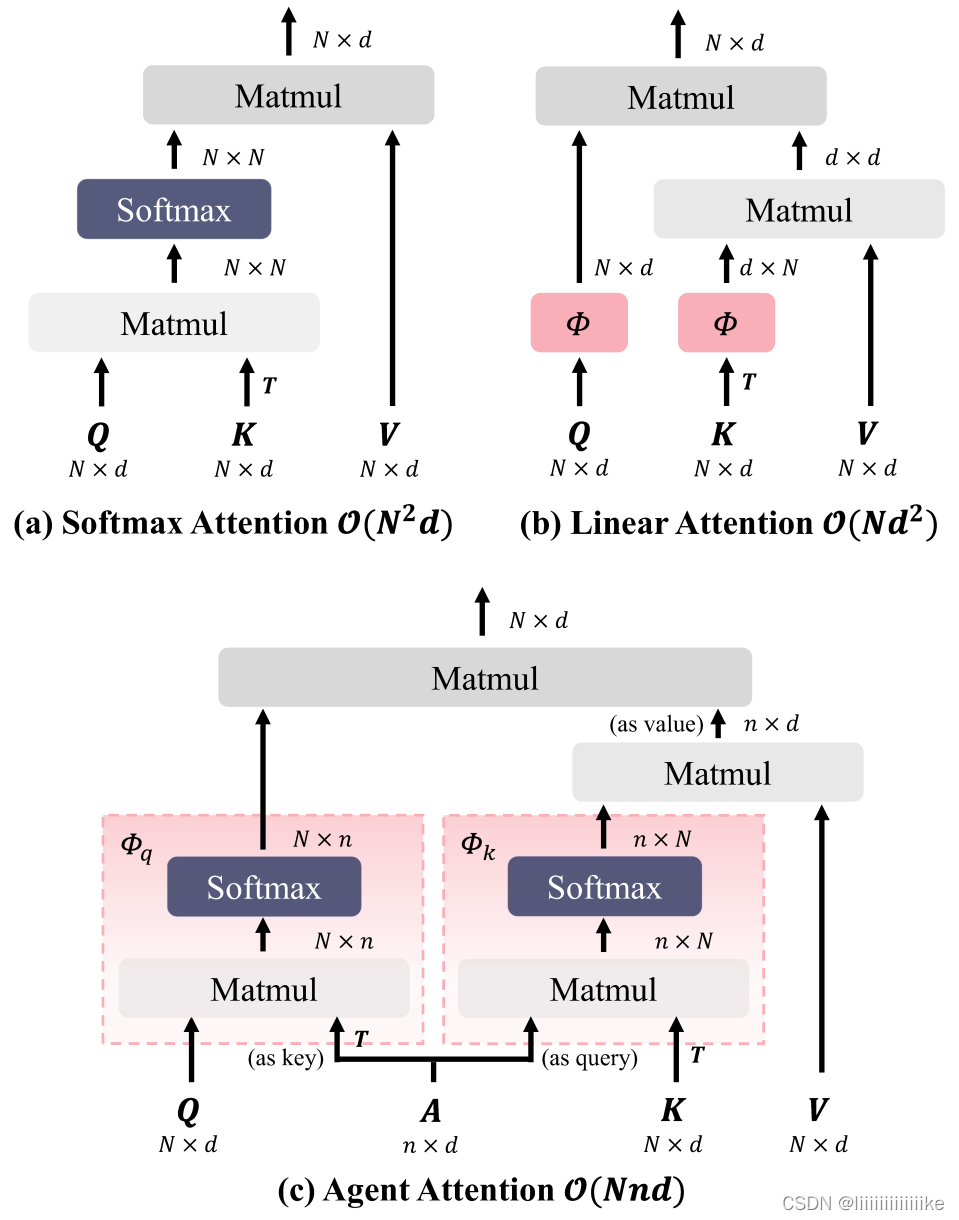
????在本文中,我们创新性地向注意力三元组 (Q,K,V) 引入了一组额外的代理向量 A,定义了一种四元的代理注意力范式 (Q, A, K, V)。如图 1 ? 所示,在代理注意力中,我们不会直接计算 Q 和 K 之间两两的相似度,而是使用少量的代理向量 A 来收集 K 和 V 中的信息,进而呈递给 Q,以很低的计算成本实现全局信息的建模。从整体结构上看,代理注意力由两个常规 Softmax 注意力操作组成,并且等效为一种广义的线性注意力,实现了高性能 Softmax 注意力和高效线性注意力的自然融合,因而同时具有二者的优点,即:计算复杂度低且模型表达能力强。
????简单理解为:softmax式注意力机制复杂度为O(NNd)、线性注意力O(Ndd)、agent注意力O(Nnd),即取了一个折中的方式,复杂度与Agent数据密切相关。
3. Agent Attention block
????为了更好地发挥代理注意力的潜力,本文进一步做出了两方面的改进。一方面,我们定义了 Agent Bias 以促进不同的代理向量聚焦于图片中不同的位置,从而更好地利用位置信息。另一方面,作为一种广义的线性注意力,代理注意力也面临特征多样性不足的问题,因此我们采用一个轻量化的 DWC 作为多样性恢复模块。
在以上设计的基础上,本文提出了一种新的代理注意力模块,其结构如下图:
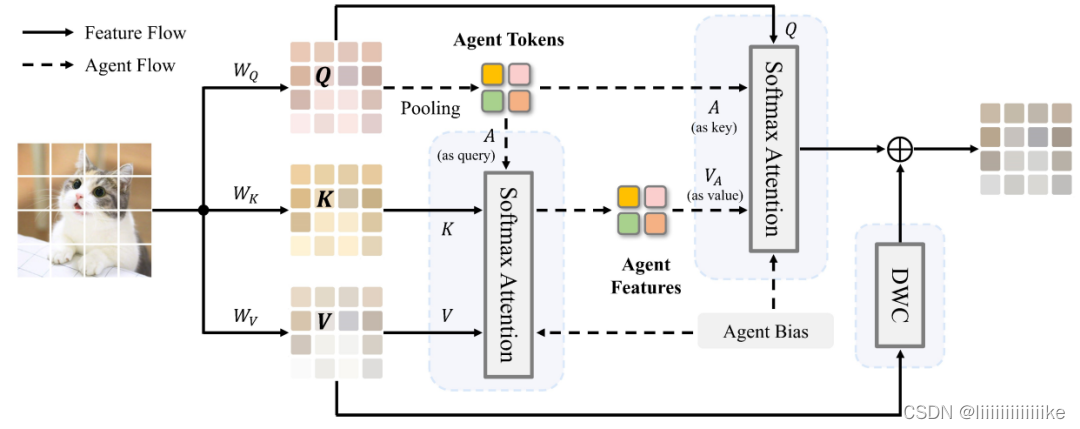
结合了 Softmax 注意力和线性注意力的优势,代理注意力模块具有以下特点:
(1) 计算复杂度低且模型表达能力强。之前的研究通常将 Softmax 注意力和线性注意力视为两种不同的注意力范式,试图解决各自的问题和局限。代理注意力优雅地融合了这两种注意力形式,从而自然地继承了它们的优点,同时享受低计算复杂性和高模型表达能力。
(2) 能够采用更大的感受野。得益于线性计算复杂度,代理注意力可以自然地采用更大的感受野,而不会增加模型计算量。例如,可以将 Swin Transformer 的 window size 由 7^2 扩大为 56^2,即直接采用全局自注意力,而完全不引入额外计算量。
4. 实验结果
4.1 分类任务
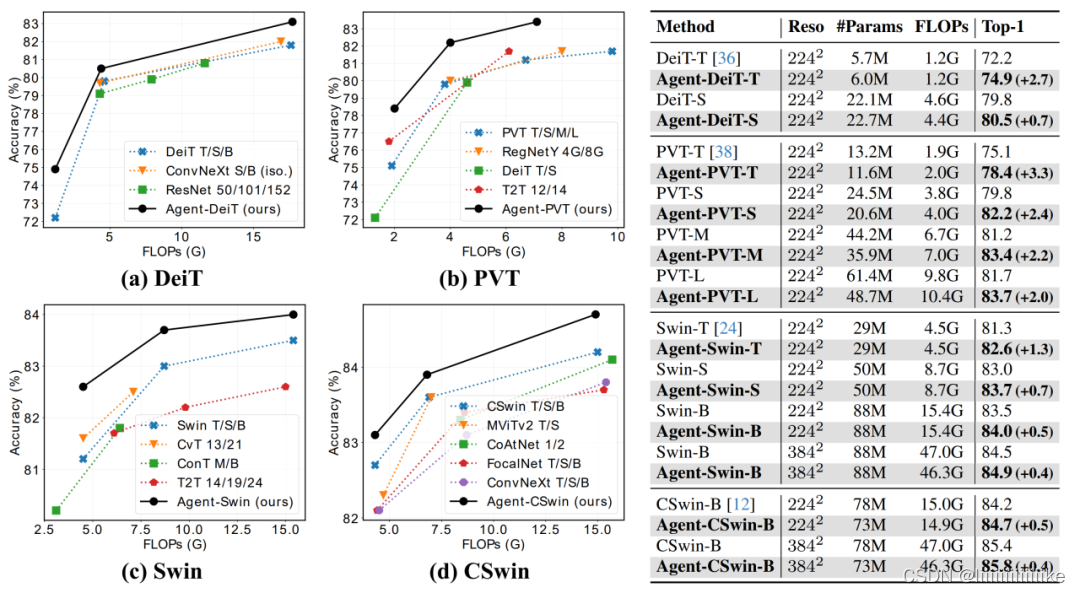
代理注意力是一个通用的注意力模块,本文基于 DeiT、PVT、Swin Transformer、CSwin Transformer 等模型架构进行了实验。如下图所示,在 ImageNet 分类任务中,基于代理注意力构建的模型能够取得显著的性能提升。例如,Agent-Swin-S 可以取得超越 Swin-B 的性能,而其参数量和计算量不到后者的 60%。
4.2 检测和分割
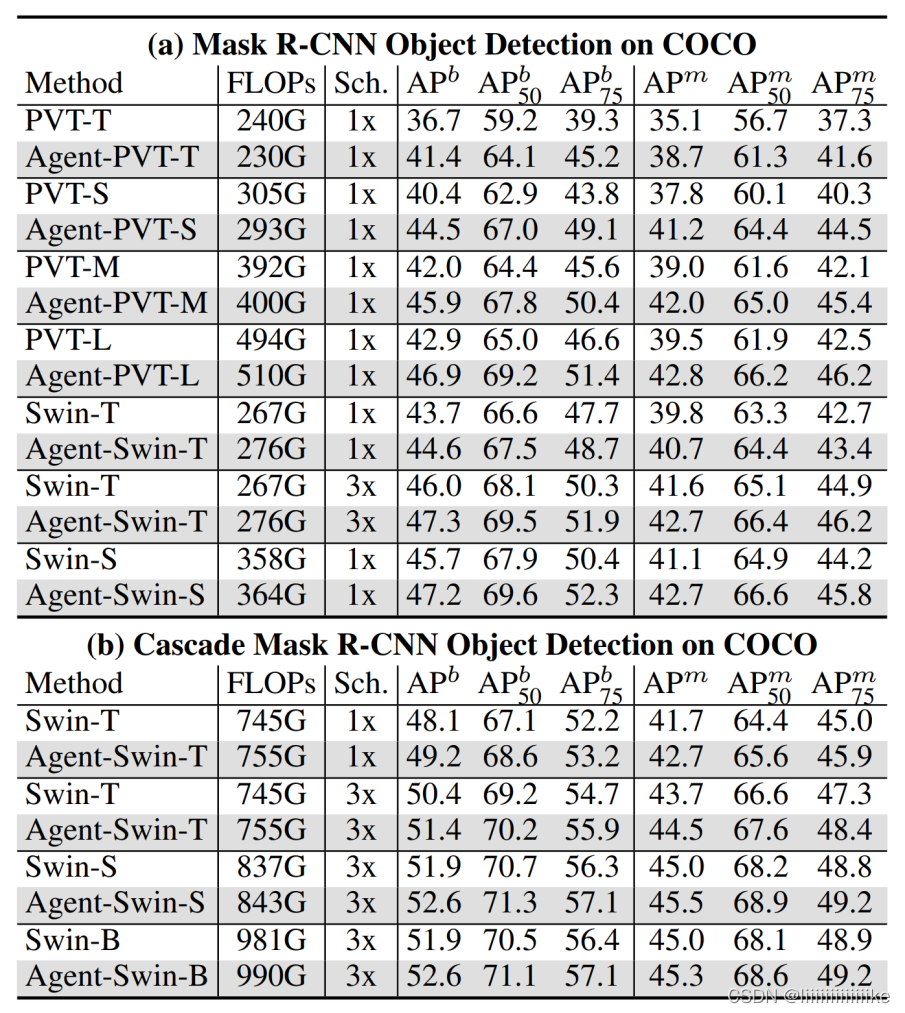
在检测和分割任务中,相较于基础模型,Agent Transformer 也能够取得十分显著的性能提升,这在一定程度上得益于代理注意力的全局感受野。
4.3 Agent Stable Diffusion
特别值得指出的是,代理注意力可以直接应用于 Stable Diffusion 模型,无需训练,即可加速生成并显著提升图片生成质量。如下图所示,将代理注意力应用于 Stable Diffusion 模型,能够将图片生成速度提升约 1.8 倍,同时提升图片的生成质量。
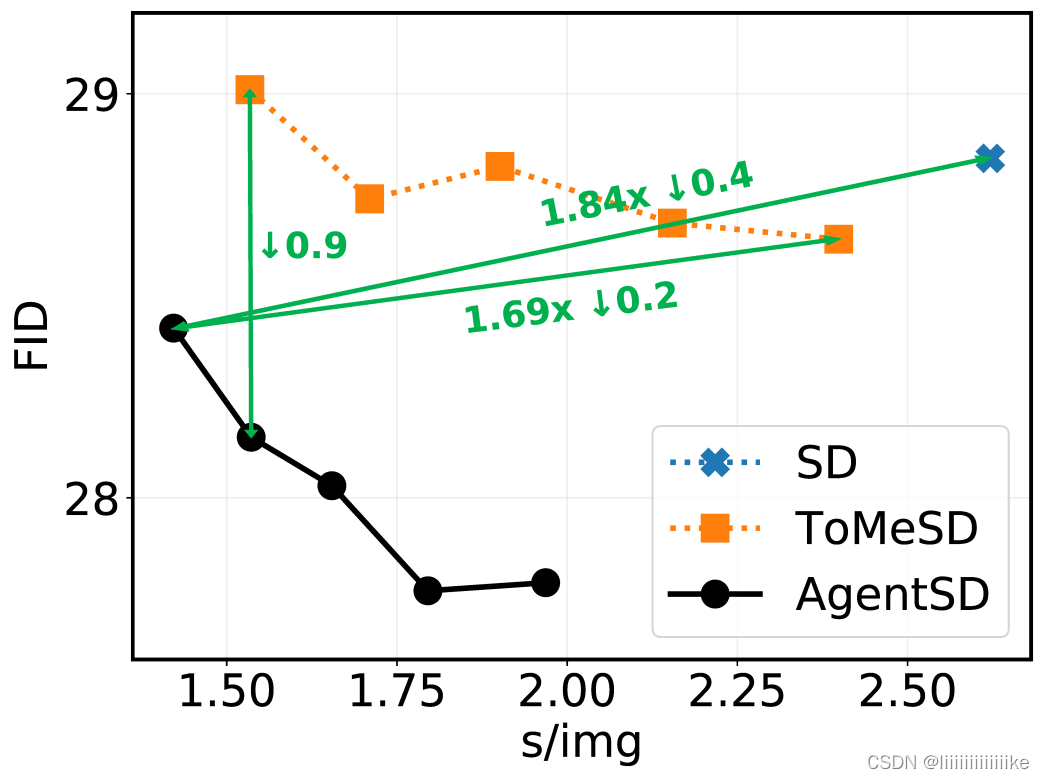
下图中给出了生成图片的样例。可以看到,代理注意力能够显著降低 Stable Diffusion 模型生成图片的歧义和错误,同时提升生成速度和生成质量。

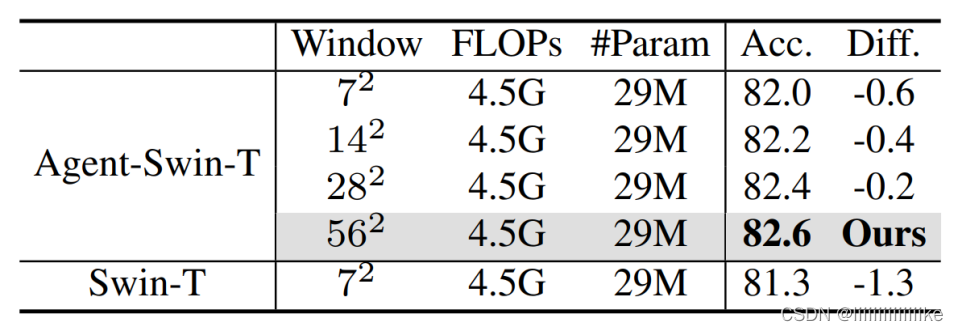
4.4 高分辨率与大感受野
本文还探究了分辨率和感受野对模型性能的影响。如下图所示,我们基于 Agent-Swin-T 将窗口大小由 7^2 逐步扩大到 56^2。可以看到,随着感受野的扩大,模型性能稳步提升。这说明尽管 Swin 的窗口划分是有效的,但它依然不可避免地损害了模型的全局建模能力。
下图中,我们将图片分辨率由 256^2 逐步扩大到 384^2。可以看到,在高分辨率的场景下,代理注意力模型持续展现出显著的优势。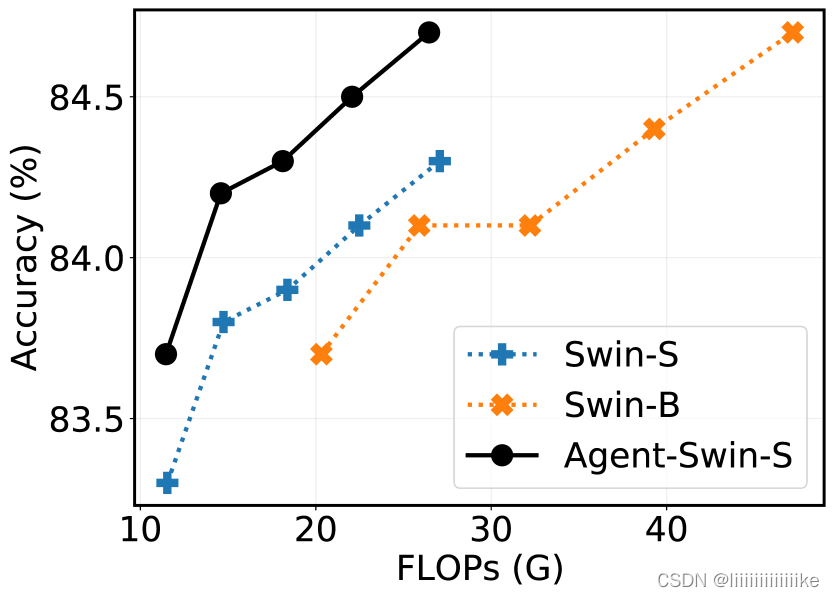
5. 总结
本文的贡献主要在三个方面:
(1) 提出了一种新颖、自然、有效且高效的注意力范式 —— 代理注意力,它自然地融合了高性能的 Softmax 注意力和高效的线性注意力,以线性计算量实现有效的全局信息建模。
(2) 在分类、检测、分割等诸多任务中充分验证了代理注意力的优越性,特别是在高分辨率、长序列的场景下,这或为开发大尺度、细粒度、面向实际应用场景的视觉、语言大模型提供了新的方法。
(3) 创新性地以一种无需训练的方式将代理注意力应用于 Stable Diffusion 模型,显著提升生成速度并提高图片质量,为扩散模型的加速和优化提供了有效的新研究思路。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!