密集检索:我们应该使用什么样的检索粒度?(如何提升召回率)
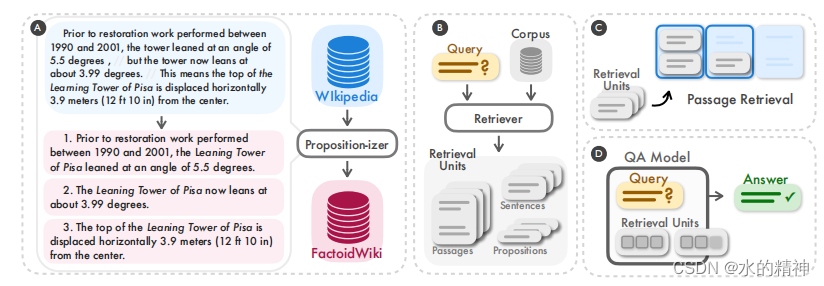
? 最近在做搜索召回提升的研究工作,看到一篇好的论文,思路比较新颖。论文中提出了通过对原文抽取“命题”,对命题进行检索,可以提升10%-20%的召回率。(这里的命题,实际上是不可拆分的子问题。)
在现代的自然语言处理(NLP)任务中,密集检索已经成为获取相关上下文或世界知识的突出方法。当我们使用一个已学习的密集检索器在检索语料库上进行推断时,一个经常被忽视的设计选择是语料库的检索单位,例如文档、段落或句子。我们发现,检索单位的选择对检索和下游任务的性能有显著影响。
不同于典型的采用段落或句子的方法,我们引入了一个新的检索单位——命题,用于密集检索。命题被定义为文本中的原子表达式,每个命题都封装了一个不同的方面,并以简洁、自包含的自然语言格式呈现。
我们进行了不同检索粒度的实证比较。结果表明,基于命题的检索在密集检索中显著优于传统的段落或句子基方法。此外,通过命题进行检索还可以提高下游问答(QA)任务的表现,因为检索的文本更简洁,包含与问题相关的信息,从而减少了对冗长输入令牌的需求,并最大限度地减少了无关信息的包含。
一、介绍
密集检索器是一种流行的技术,用于访问外部信息源以执行知识密集型任务(Karpukhin等,2020)。在使用已学习的密集检索器从语料库中进行检索之前,我们必须做出一个重要的设计决策——检索单位,即我们分割和索引语料库的粒度。
什么事命题呢?
命题是一种精炼的、自包含的语句,它可以准确、完整地表达文本中的某个原子事实,不受其他文本部分影响即可理解。
示范: 段落:乔治·弗兰克·冯·弗兰肯奥教授于1678年在德国西南部记录了最早的复活节兔子现象。 命题:乔治·弗兰克·冯·弗兰肯奥是医学教授。 命题:复活节兔子现象在1678年由乔治·弗兰克·冯·弗兰肯奥首次记录在案。
二、不同检索粒度的比较
在本文中,我们将比较文档、段落和句子等传统检索单位与新提出的命题检索单位之间的性能差异。我们将使用一系列实验来评估不同检索粒度对密集检索和下游任务性能的影响。
首先,我们将简要介绍传统的文档、段落和句子检索单位,并解释它们在密集检索中的使用方式。然后,我们将详细介绍命题检索单位,并解释其在密集检索中的优势和应用。
在比较不同检索粒度的实验中,我们将使用一系列评估指标来衡量性能,包括准确率、召回率和F1分数等。我们将根据实验结果讨论不同检索粒度的优缺点,并确定最适合特定任务的检索粒度。
在密集检索模型的实际应用中,一个至关重要的设计决策就是确定检索粒度,即我们如何将检索语料库划分为不同的单元来进行索引。过去的研究和实践倾向于采用固定的100词段落或句子作为检索单位,但这忽略了检索单元选择对模型检索能力和下游任务性能的潜在影响。事实上,检索粒度的选择对模型能否成功捕获和传递相关知识至关重要。

当预先训练的密集检索器使用来自检索语料库的三个不同粒度时,对5个不同的开放域QA数据集的通道检索性能(Recall@k = 5,20)。下划线表示在密集检索器的训练数据中包含了目标数据集的训练分割的情况。

在检索后读设置下的开放域QA性能(EM =精确匹配),其中检索到的单词到读者QA模型的单词数量限制在l = 100或500。我们使用UnifedQA V2(Khashabi et al.,2022)作为读者模型。从连接的顶部检索文本单元中提取的第一个l个单词作为阅读器模型的输入。下划线表示在密集检索器的训练数据中包含了目标数据集的训练分割的情况。在大多数情况下,我们看到更小的检索单元看到更好的QA性能。
三、命题检索单位的介绍
命题检索单位是一种新型的检索单位,用于密集检索。与传统的文档、段落或句子检索单位不同,命题被定义为文本中的原子表达式,每个命题都封装了一个不同的方面,并以简洁、自包含的自然语言格式呈现。
在命题检索中,语料库被分割成一系列的命题。每个命题都包含一个明确的信息点,如事实、概念或关系等。这种原子化的表示方式使得命题能够更精确地捕捉文本中的信息,并提供更紧凑的表示形式。
与传统的段落或句子检索单位相比,命题检索单位具有以下优点:
- 精确性:命题能够精确地捕获文本中的信息点,避免了传统方法中可能出现的冗余或不相关信息的干扰。
- 简洁性:命题以简洁、自包含的形式呈现信息,减少了输入令牌的长度,提高了模型的效率和可解释性。
- 可扩展性:命题可以轻松地应用于不同的语言和领域,而无需对整个文档或段落进行索引。这使得命题具有更好的可扩展性和灵活性。
- 交互性:由于命题封装了明确的信息点,用户可以更轻松地与检索结果进行交互和过滤。这有助于提高用户体验和任务效率。
四、实验结果与讨论
为了评估不同检索粒度对密集检索和下游任务性能的影响,我们进行了一系列实验。我们使用不同的评估指标来衡量不同检索粒度在密集检索和下游任务中的表现,并使用表格和图表记录了实验结果。
首先,我们比较了文档、段落和句子检索单位在密集检索中的性能。实验结果表明,句子检索单位在大多数情况下表现最好,其次是段落检索单位,最后是文档检索单位。句子检索单位能够更好地捕获文本中的信息,并提供更精确的表示形式。
然后,我们比较了基于命题的检索单位与传统的句子检索单位在密集检索中的性能。实验结果表明,基于命题的检索单位显著优于传统的句子检索单位。命题检索单位能够更准确地捕获文本中的信息点,并提供更紧凑的表示形式。此外,命题检索单位还具有更好的可扩展性和灵活性。
接下来,我们评估了命题检索单位在下游问答任务中的性能。实验结果表明,基于命题的检索可以显著提高下游问答任务的性能。由于命题检索的文本更简洁,包含与问题相关的信息,从而减少了对冗长输入令牌的需求,并最大限度地减少了无关信息的包含。此外,命题检索单位还允许用户更轻松地与检索结果进行交互和过滤,从而提高用户体验和任务效率。
在实验环节中,我们选取了五种广泛使用的开放领域问答数据集,采用六款领先的有监督和无监督双编码器检索模型(如SimCSE、Contriever、DPR、ANCE、TAS-B 和 GTR),在以段落、句子和命题为检索单位的不同情况下,评估了它们在检索和下游问答任务上的性能差异。
实验结果显示,命题检索在检索性能和下游问答任务准确度上均显著超过基于段落和句子的传统方法。尤其是在面对严格的输入令牌长度限制时,命题检索的优势尤为突出。因为命题天然具有更高的问题相关信息密度,从而减少了冗余输入和无关信息的混杂,提高了检索结果的针对性和准确性。
统计数据显示,相比于段落检索,无监督的密集检索器在Recall@20指标上平均提升了10.1个百分点,而有监督的检索器也获得了+2.2个百分点的提升。同时,在开放式问答任务中,基于命题的检索策略同样表现出色,有助于提高模型回答问题的准确性和效率。
五、未来工作
- 优化命题表示:我们将研究如何进一步优化命题的表示方式,以提高其捕获文本信息的能力。例如,我们可以尝试使用更复杂的信息抽取技术或模型结构来提取更丰富的信息点。
- 多粒度检索:除了单个粒度检索外,我们将研究多粒度检索策略,以综合利用不同粒度的信息来提高性能。例如,我们可以同时使用文档、段落、句子和命题等多种粒度进行联合检索。
- 跨语言和领域应用:我们将探索如何将命题检索单位扩展到不同的语言和领域中,以实现跨语言和跨领域的可扩展性和灵活性。这将有助于提高命题检索的实用性和广泛应用价值。
六、相关工作
尽管本文主要关注命题检索单位在密集检索和下游任务中的应用,但相关工作还包括其他检索粒度的比较以及相关技术的探索。
传统的检索粒度,如文档、段落和句子,已经在密集检索和下游任务中得到了广泛的研究和应用。例如,一些工作已经探讨了如何使用文档或段落作为检索单位来提高问答任务的表现(Bigham et al., 2010; Li et al., 2019)。这些研究为命题检索单位的应用提供了有益的参考和启示。
此外,相关工作还包括对其他检索技术的研究,如特征提取、语义理解和实体链接等。这些技术可以与命题检索单位相结合,以进一步提高密集检索和下游任务的表现。例如,实体链接技术可以帮助我们将文本中的实体链接到外部知识库,从而提供更丰富和准确的信息(Nickel et al., 2016)。
七、应用前景
命题检索单位在许多领域中都具有广泛的应用前景。以下是一些潜在的应用方向:
- 问答系统:在问答系统中,命题检索单位可以帮助我们更精确地找到与问题相关的信息,从而提高问答的准确率。同时,由于命题检索的文本更为简洁,可以减少对用户输入的冗长解释的需求,提升用户体验。
- 文档摘要:在文档摘要任务中,命题检索单位可以帮助我们快速提取文档中的关键信息,为用户提供一个简洁、自包含的摘要。这种简洁的表示形式有助于提高摘要的可读性和可理解性。
- 社交媒体分析:在社交媒体分析中,命题检索单位可以帮助我们快速识别和提取社交媒体帖子中的关键信息,如情感分析、主题建模和影响力分析等。这种原子化的表示方式有助于提高分析的精确度和效率。
- 机器翻译:在机器翻译中,命题检索单位可以帮助我们快速找到与目标语言相关的翻译,从而提高翻译的准确性和效率。这种检索方式有助于减少对大规模语料库的依赖,并提高翻译的流畅性和自然度。
- 辅助写作和编辑:在辅助写作和编辑中,命题检索单位可以帮助我们快速找到与写作主题相关的素材和信息,从而丰富写作内容、提高写作效率。这种检索方式有助于减少写作中的冗余和不相关信息的干扰。
这些应用方向只是命题检索单位潜在应用的一部分。随着自然语言处理技术的不断发展,命题检索单位有望在更多领域得到应用和推广。
八、结论
通过深入研究不同检索粒度对密集检索和下游任务性能的影响,本文特别介绍了新提出的命题检索单位。实证比较结果显示,基于命题的检索在密集检索中明显优于传统的句子检索单位,同时在下游问答任务中也取得显著的性能提升。命题检索单位以其精确性、简洁性、可扩展性和交互性等优势脱颖而出,能够更准确地捕捉文本中的信息点,并提供更紧凑的表示形式。由于命题明确封装了信息点,用户能够更轻松地与检索结果进行交互和过滤。
在未来的研究中,我们将进一步探讨命题检索单位的实施细节和优化方法。同时,我们还计划研究如何将命题检索单位与其他自然语言处理任务结合,以进一步提升任务性能和可解释性。总体而言,通过结合其他检索技术和相关技术,我们有望进一步推动密集检索和下游任务的性能,推动自然语言处理领域的进步。
九、个人实践
这篇论文内容很多,描述的比较杂,又没有给出具体的操作方案。下边是我根据论文的自己的实践经验。其实就是构建一个prompt,来抽取文本内容中的知识点。
这里给出我的案例
任务:从给定的文本段落中提取出所有代表独立事实的命题。 定义:命题是一种精炼的、自包含的语句,它可以准确、完整地表达文本中的某个原子事实,不受其他文本部分影响即可理解。 示范: 段落:乔治·弗兰克·冯·弗兰肯奥教授于1678年在德国西南部记录了最早的复活节兔子现象。 命题:乔治·弗兰克·冯·弗兰肯奥是医学教授。 命题:复活节兔子现象在1678年由乔治·弗兰克·冯·弗兰肯奥首次记录在案。 现在,请您基于以上定义和示范,从以下段落中生成类似的命题列表:先进的RAG已经进行了有针对性的改进,以克服了朴素RAG的不足。在检索生成的质量方面,高级RAG结合了前检索和后检索方法。为了解决朴素RAG所遇到的索引问题,高级RAG通过滑动窗口、细粒度分割和元数据等方法进行了索引优化。同时,提出了多种优化检索过程的方法。在具体的实现方面,高级RAG可以通过管道或以端到端的方式进行调整。
看抽取的结果(我是用的chat-gpt 用国内的模型效果差不多!)
- 先进的RAG已经进行了有针对性的改进,以克服了朴素RAG的不足。
- 高级RAG结合了前检索和后检索方法,以提高检索生成的质量。
- 高级RAG通过滑动窗口、细粒度分割和元数据等方法进行了索引优化,以解决朴素RAG所遇到的索引问题。
- 高级RAG提出了多种优化检索过程的方法。
- 在具体的实现方面,高级RAG可以通过管道或以端到端的方式进行调整。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!