HAT(CVPR 2023):Hybrid Attention Transformer for Image Restoration
HAT
? 论文地址:HAT: Hybrid Attention Transformer for Image Restoration
? 代码地址:XPixelGroup/HAT: CVPR2023 - Activating More Pixels in Image Super-Resolution Transformer
摘要
? 通过归因分析attribution analysis method - Local Attribution Map (LAM),发现目前基于Transformer的方法只能来利用有限的输入空间信息。这意味着 Transformer 的潜力在现有网络中仍未得到充分利用。为了激活更多的输入像素以获得更好的恢复,提出了一种新的混合注意Transformer(HAT)。它结合了通道注意力和基于窗口的自注意力机制,从而利用了它们的互补优势。此外,为了更好地聚合窗口之间信息,引入了一个重叠的交叉注意模块来增强相邻窗口特征之间的交互。在训练阶段,采用了相同的任务预训练策略来进一步利用模型的潜力进行进一步改进。
现阶段问题
- SwinIR 比基于 CNN 的方法(例如 RCAN [10])在某些场景利用的输入像素更少。
- 在 SwinIR 的中间特征中会出现阻塞伪影。这表明移位窗口机制不能完美地实现跨窗口信息交互。
主要贡献
- 提出了一种混合注意力 Transformer,即 HAT。结合通道注意和自注意力机制,以利用前者transformer使用全局信息的能力(激活更多像素)和后者Self-attention强大的representative ability
- 引入了一个overlapping的注意力窗口模块来实现相邻窗口特征的更直接的交互,减少阻塞伪影产生。
网络框架
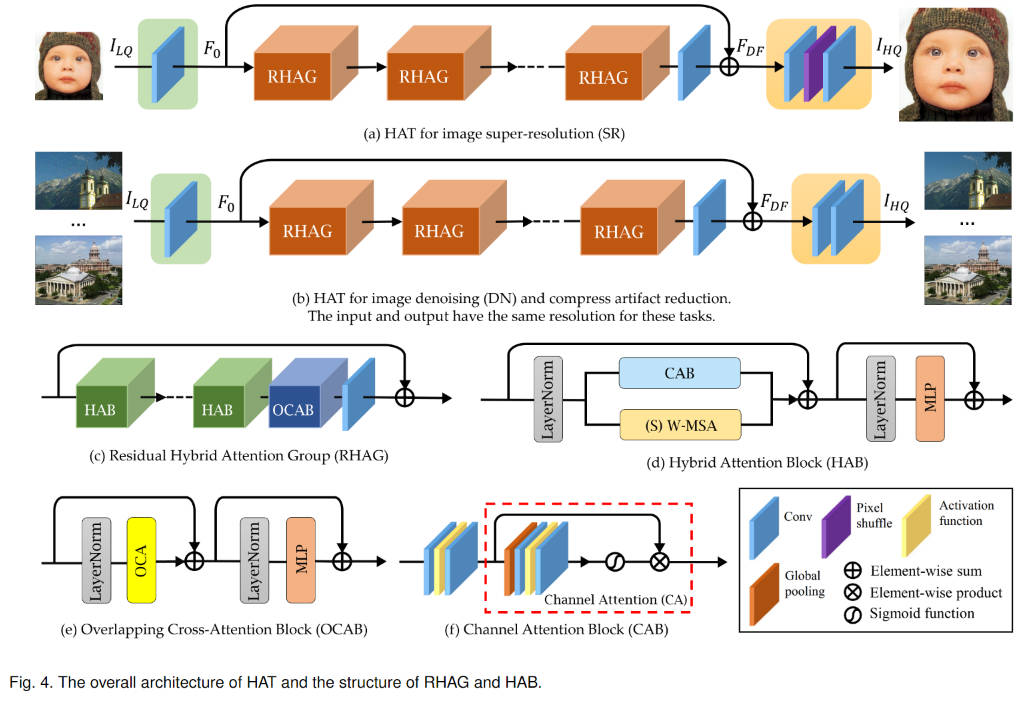
HAB模块
采用标准Swin Transformer块的类似结构,并再其中融入了Channel Attention。
- 增加window size大小为16,扩大窗口感受野,因为根据实验,限制窗口大小能节省计算成本,单通过移位窗口逐步增加感受野,却牺牲了自注意力机制的表征能力。
- 引入通道注意力机制,会激活更多像素,因为其涉及利用全局信息计算,有利于对纹理部分的优化。
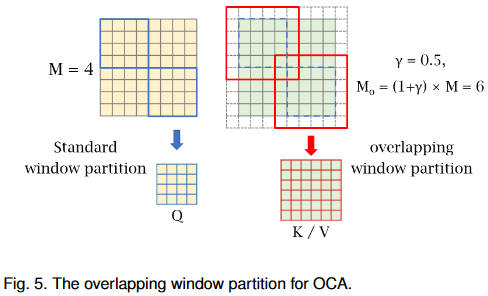
overlapping window partition
? 我们的 OCA 与 Multi-resolution Overlapped Attention (MOA) 根本不同。MOA 使用窗口特征作为token计算全局注意力,而 OCA 使用像素token计算每个窗口特征内的交叉注意力。
? 为什么不全部使用OCA,因为全部使用这种模块会不可避免带来大量计算负担,采用有限数量的OCA可以有效增加窗口之间的交互。
qkv = self.qkv(x).reshape(b, h, w, 3, c).permute(3, 0, 4, 1, 2) # 3, b, c, h, w
q = qkv[0].permute(0, 2, 3, 1) # b, h, w, c
kv = torch.cat((qkv[1], qkv[2]), dim=1) # b, 2*c, h, w
# partition windows
q_windows = window_partition(q, self.window_size) # nw*b, window_size, window_size, c
q_windows = q_windows.view(-1, self.window_size * self.window_size, c) # nw*b, window_size*window_size, c
kv_windows = self.unfold(kv) # b, c*w*w, nw
kv_windows = rearrange(kv_windows, 'b (nc ch owh oww) nw -> nc (b nw) (owh oww) ch',
nc=2, ch=c, owh=self.overlap_win_size, oww=self.overlap_win_size).contiguous() # 2, nw*b, ow*ow, c
k_windows, v_windows = kv_windows[0], kv_windows[1] # nw*b, ow*ow, c
b_, nq, _ = q_windows.shape
_, n, _ = k_windows.shape
d = self.dim // self.num_heads
q = q_windows.reshape(b_, nq, self.num_heads, d).permute(0, 2, 1, 3) # nw*b, nH, nq, d
k = k_windows.reshape(b_, n, self.num_heads, d).permute(0, 2, 1, 3) # nw*b, nH, n, d
v = v_windows.reshape(b_, n, self.num_heads, d).permute(0, 2, 1, 3) # nw*b, nH, n, d
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
结论
? 在这项工作中,我们提出了一种新的混合注意转换器HAT,用于图像恢复。我们的模型结合了通道注意力和自注意力来激活更多像素以进行高分辨率重建。此外,我们提出了一个重叠的交叉注意模块来增强跨窗口信息的交互。此外,我们介绍了一种用于图像超分辨率的相同任务预训练策略。广泛的基准和真实世界的评估表明,我们的HAT在几个图像恢复任务上优于最先进的方法
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!