springcloud项目实战之自定义负载均衡器
系列文章 。
写在前面
本部分看下如何自定义负载均衡器从而满足业务对于负载均衡特定的需求。
源码 。
1:负载均衡的知识点
1.1:什么是负载均衡?
多台服务器随机的选择一台处理请求的技术,叫做负载均衡自己总结的,非官方回答。
1.2:为什么需要负载均衡?
如果老逮着一只羊薅羊毛,这只羊会被薅秃噜皮了,同理如果所有的请求都由一台服务器处理,这台服务器也将不堪重负,也会制约系统的吞吐量,因此我们需要负载均衡技术。
1.3:负载均衡的都有哪些类型?
服务端负载均衡(或者叫网关层负载均衡)和客户端负载均衡,前者参考下图:

这种方式的缺点和优点如下:
- 优点
对于客户端是透明的,不需要关心负载均衡的逻辑,和调用单服务没有任何差别
- 缺点
需要维护网关组件,所以会提高系统的复杂度和故障率。而且多一层网关调用会增加10ms到20ms的网络延时,在高QPS的场景中这十几毫秒的延时将会被无限放大,成为系统的性能瓶颈。
对于网关负载均衡的不足,客户端负载均衡可以很好地解决,不足之处就是客户端需要服务发现,以及自己实现负载均衡方案。客户端负载均衡可参考下图:

1.4:springcloud的负载均衡器是什么?
Loadbalancer。
2:LoadBalancer的工作原理
我们在类dongshi.daddy.loadbalance.Configuration中使用了@LoadBalancer注解,如下:
@Bean
@LoadBalanced
public WebClient.Builder register() {
return WebClient.builder();
}
在使用了该注解后,就会生成一个具有负载均衡能力的WebClient,原理是偷摸的在WebClient塞了了一个特殊的Fitler,实现的方式是,首先看一个自动配置类ReactorLoadBalancerClientAutoConfiguration :
@Configuration(proxyBeanMethods = false)
// 只要Path路径上能加载到WebClient和ReactiveLoadBalancer
// 则开启自动装配流程
@ConditionalOnClass(WebClient.class)
@ConditionalOnBean(ReactiveLoadBalancer.Factory.class)
public class ReactorLoadBalancerClientAutoConfiguration {
// 如果开启了Loadbalancer重试功能(默认开启)
// 则初始化RetryableLoadBalancerExchangeFilterFunction
@ConditionalOnMissingBean
@ConditionalOnProperty(value = "spring.cloud.loadbalancer.retry.enabled", havingValue = "true")
@Bean
public RetryableLoadBalancerExchangeFilterFunction retryableLoadBalancerExchangeFilterFunction(
ReactiveLoadBalancer.Factory<ServiceInstance> loadBalancerFactory, LoadBalancerProperties properties,
LoadBalancerRetryPolicy retryPolicy) {
return new RetryableLoadBalancerExchangeFilterFunction(retryPolicy, loadBalancerFactory, properties);
}
// ...省略部分代码
当存在类WebClient以及存在类型为ReactiveLoadBalancer.Factory.class的bean时,开启自动装配,会生成beanRetryableLoadBalancerExchangeFilterFunction,接着看自动装配类LoadBalancerBeanPostProcessorAutoConfiguration:
// 省略部分代码
public class LoadBalancerBeanPostProcessorAutoConfiguration {
// 内部配置类
@Configuration(proxyBeanMethods = false)
@ConditionalOnBean(ReactiveLoadBalancer.Factory.class)
protected static class ReactorDeferringLoadBalancerFilterConfig {
// 将第一步中创建的ExchangeFilterFunction实例封装到另一个名为
// DeferringLoadBalancerExchangeFilterFunction的过滤器中
@Bean
@Primary
DeferringLoadBalancerExchangeFilterFunction<LoadBalancedExchangeFilterFunction> reactorDeferringLoadBalancerExchangeFilterFunction(
ObjectProvider<LoadBalancedExchangeFilterFunction> exchangeFilterFunctionProvider) {
return new DeferringLoadBalancerExchangeFilterFunction<>(exchangeFilterFunctionProvider);
}
}
// 将过滤器打包到后置处理器中
@Bean
public LoadBalancerWebClientBuilderBeanPostProcessor loadBalancerWebClientBuilderBeanPostProcessor(
DeferringLoadBalancerExchangeFilterFunction deferringExchangeFilterFunction, ApplicationContext context) {
return new LoadBalancerWebClientBuilderBeanPostProcessor(deferringExchangeFilterFunction, context);
}
}
首先生成beanDeferringLoadBalancerExchangeFilterFunction然后将该bean封装到LoadBalancerWebClientBuilderBeanPostProcessor中,这是一个后置bean处理器,就是在该后置bean处理器中完成向WebClient中添加特殊的fitler的工作的:
public class LoadBalancerWebClientBuilderBeanPostProcessor implements BeanPostProcessor {
// ... 省略部分代码
// 对过滤器动手脚
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
// 如果满足以下条件,则将过滤器添加到WebClient中
// 1) 当前Bean是WebClient.Builder实例
// 2) WebClient被@LoadBalanced注解修饰
if (bean instanceof WebClient.Builder) {
if (context.findAnnotationOnBean(beanName, LoadBalanced.class) == null) {
return bean;
}
// 添加过滤器
((WebClient.Builder) bean).filter(exchangeFilterFunction);
}
return bean;
}
}
只有满足类型为web Client.Builder,并且使用了@Balancer注解的才会处理,通过代码((WebClient.Builder) bean).filter(exchangeFilterFunction);添加filter。
3:自定义负载均衡器
我们通过自定义负载均衡器来实现金丝雀发布,即只让一部分用户使用新上线的功能,正常的功能调用如下图:

其中服务B有3个节点,假定新功能上线,我们只替换其中的一个节点,如下图:
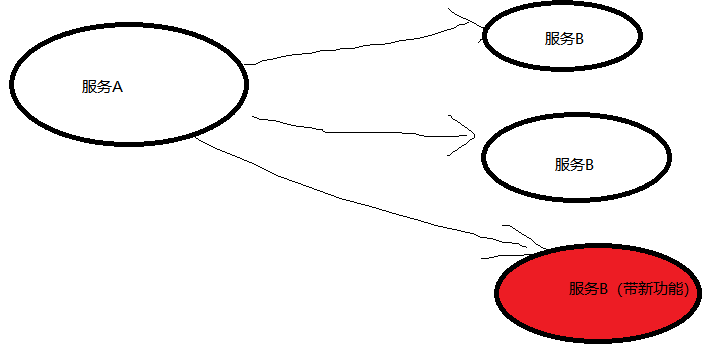
这样只有其中一部分流量会打到部署了新功能的节点上,这就是金丝雀发布,但是这里我们为了更好的控制哪些请求执行到新功能节点,就需要自己来实现一个负载均衡器,这里我们实现的方式是通过请求中的一个特殊标记traffic-version当该值为test001时就把这个请求作为我们的金丝雀处理,那么接下来就可以正式开始我们的工作了。
LoadBalancer组件的顶层接口是ReactiveLoadBalancer,我们这里可以实现其子接口ReactorServiceInstanceLoadBalancer,来定义金丝雀的规则类CanaryRule,源码如下:
// 可以将这个负载均衡策略单独拎出来,作为一个公共组件提供服务
@Slf4j
public class CanaryRule implements ReactorServiceInstanceLoadBalancer {
private ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider;
private String serviceId;
// 定义一个轮询策略的种子
final AtomicInteger position;
public CanaryRule(ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider,
String serviceId) {
this.serviceId = serviceId;
this.serviceInstanceListSupplierProvider = serviceInstanceListSupplierProvider;
position = new AtomicInteger(new Random().nextInt(1000));
}
...
Response<ServiceInstance> getInstanceResponse(List<ServiceInstance> instances, Request request) {
...
// 从请求Header中获取特定的流量打标值
// 注意:以下代码仅适用于WebClient调用,如果使用RestTemplate或者Feign则需要额外适配
DefaultRequestContext context = (DefaultRequestContext) request.getContext();
RequestData requestData = (RequestData) context.getClientRequest();
HttpHeaders headers = requestData.getHeaders();
String trafficVersion = headers.getFirst(TRAFFIC_VERSION);
// 如果没有找到打标标记,或者标记为空,则使用RoundRobin规则进行轮训
if (StringUtils.isBlank(trafficVersion)) {
// 过滤掉所有金丝雀测试的节点(Metadaba有值的节点)
List<ServiceInstance> noneCanaryInstances = instances.stream()
.filter(e -> !e.getMetadata().containsKey(TRAFFIC_VERSION))
.collect(Collectors.toList());
return getRoundRobinInstance(noneCanaryInstances);
}
// 如果某台机器的traffic-version元数据和请求中的traffic-version相等,则可作为金丝雀服务器
// 找出所有金丝雀服务器,用RoundRobin算法挑出一台
List<ServiceInstance> canaryInstances = instances.stream().filter(e -> {
String trafficVersionInMetadata = e.getMetadata().get(TRAFFIC_VERSION);
return StringUtils.equalsIgnoreCase(trafficVersionInMetadata, trafficVersion);
}).collect(Collectors.toList());
return getRoundRobinInstance(canaryInstances);
}
...
}
接着基于Java config方式配置CanaryRule为bean:
// 注意这里不要写上@Configuration注解
public class CanaryRuleConfiguration {
@Bean
public ReactorLoadBalancer<ServiceInstance> reactorServiceInstanceLoadBalancer(
Environment environment,
LoadBalancerClientFactory loadBalancerClientFactory) {
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
// 在Spring上下文中声明了一个CanaryRule规则
return new CanaryRule(loadBalancerClientFactory.getLazyProvider(name,
ServiceInstanceListSupplier.class), name);
}
}
最后使用@LoadBalancerClient加载CanaryRuleConfiguration,从而加载CanaryRule,如下:
...
// value 是要代理的服务类的服务名,这里是template模块的服务名
@LoadBalancerClient(value = "coupon-template-serv-loadbalance", configuration = CanaryRuleConfiguration.class)
public class Loadbalance_CustomerApplication {
...
}
这里我们以给用户发放优惠券来测试,按照如下步骤来进行修改,首先修改RequestCoupon增加属性private String trafficVersion;,用作测试流量打标(客户端传入,即由外部调用决定是否走金,丝雀服务器),接着在WebClient头里添加traffic-version,供CanaryRule中使用,如下:
/**
* 用户领取优惠券
*/
@Override
public Coupon requestCoupon(RequestCoupon request) {
CouponTemplateInfo templateInfo = webClientBuilder.build()
// 声明了这是一个GET方法
.get()
.uri("http://coupon-template-serv-loadbalance/template/getTemplate?id=" + request.getCouponTemplateId())
// 是否走金丝雀服务器的标记
.header(TRAFFIC_VERSION, request.getTrafficVersion())
...
.block();
...
}
做完这些工作后,就可以启动一个customer,一个template了,如下:

为了便于区分测试的效果,我们来修改dongshi.daddy.loadbalance.service.CouponTemplateServiceImpl#loadTemplateInfo代码,模拟新发布的内容:
@Override
public CouponTemplateInfo loadTemplateInfo(Long id) {
System.out.println("金丝雀getTemplate。。。");
Optional<CouponTemplate> template = templateDao.findById(id);
// 模拟金丝雀代码
template.get().setShopId(1000L);
return template.isPresent() ? CouponTemplateConverter.convertToTemplateInfo(template.get()) : null;
}
这样如果是最终在表coupon中插入数据的shopId值等于1000则就是走了新代码逻辑了,也就是被金丝雀了,修改后我们再来启动一个template实例,作为部署了新功能的节点:

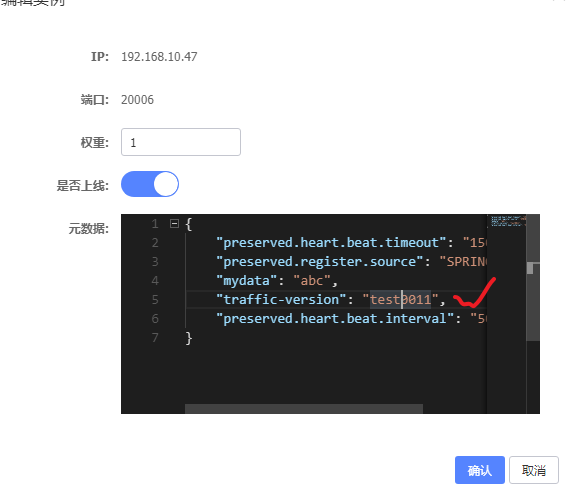
接着我们还需要为新上线的节点添加traffic-version:test0011,如下操作:

接着我们就可以来测试了,如果是如下的请求,则会被金丝雀:
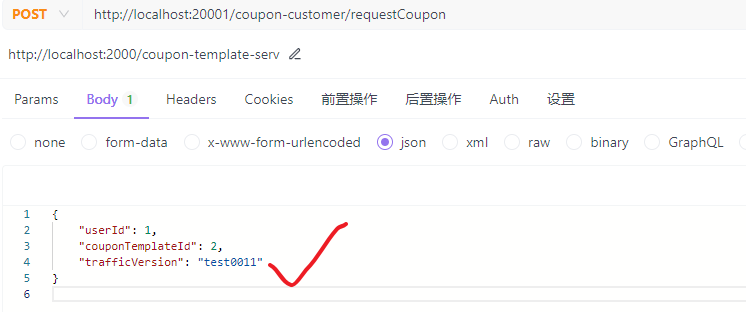
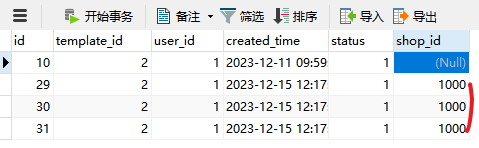
连续执行几次,会发现shopId都是1000,如下:
写在后面
参考文章列表
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!