Kafka基本原理及使用
目录
基本概念
Kafka 是一个分布式流处理平台,主要用于实时处理和传输大规模数据流。
基本MQ功能:
- 异步
- 削峰
- 解耦
与RocketMq对比:
- 高吞吐量和低延迟
- 流式处理
- 生态环境更好
适合业务场景:
-
日志聚合: Kafka 作为一个分布式消息传递系统,非常适合用于收集和存储系统和应用程序产生的大量日志数据。它提供了持久性存储和高吞吐量的写入,是构建日志聚合系统的理想选择。
-
实时数据处理: Kafka 可以与流处理框架(如 Apache Flink、Apache Storm、Spark Streaming)集成,用于实时处理和分析数据流。这使得 Kafka 在需要实时数据处理、计算和分析的场景中非常有用。
-
事件溯源: 对于需要记录系统每个状态变化的场景,例如金融交易、订单处理等,Kafka 支持事件溯源,帮助构建可追溯、可审计的系统。
-
消息队列: Kafka 作为分布式消息队列,可用于解耦生产者和消费者之间的通信。这在微服务架构中尤为重要,帮助构建松耦合的系统。
-
数据集成: Kafka 提供 Kafka Connect,一个用于数据集成的工具,用于连接 Kafka 与其他数据存储系统,支持构建端到端的数据流管道。
-
大数据管道: Kafka 可以作为大数据管道的核心组件,用于连接和传递大规模数据集,以支持数据湖、数据仓库等大数据处理场景。
单机版
环境准备
1. 从官网下载kafka, 这里选择3.4.0版本,官网:Apache Kafka
2. 解压压缩包
tar -zxvf kafka_2.13-3.4.0.tgz3. 启动自带的zookeeper, jps检查是否启动成功
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &4. 修改kafka配置文件config/server.properties, 允许外网客户端连接
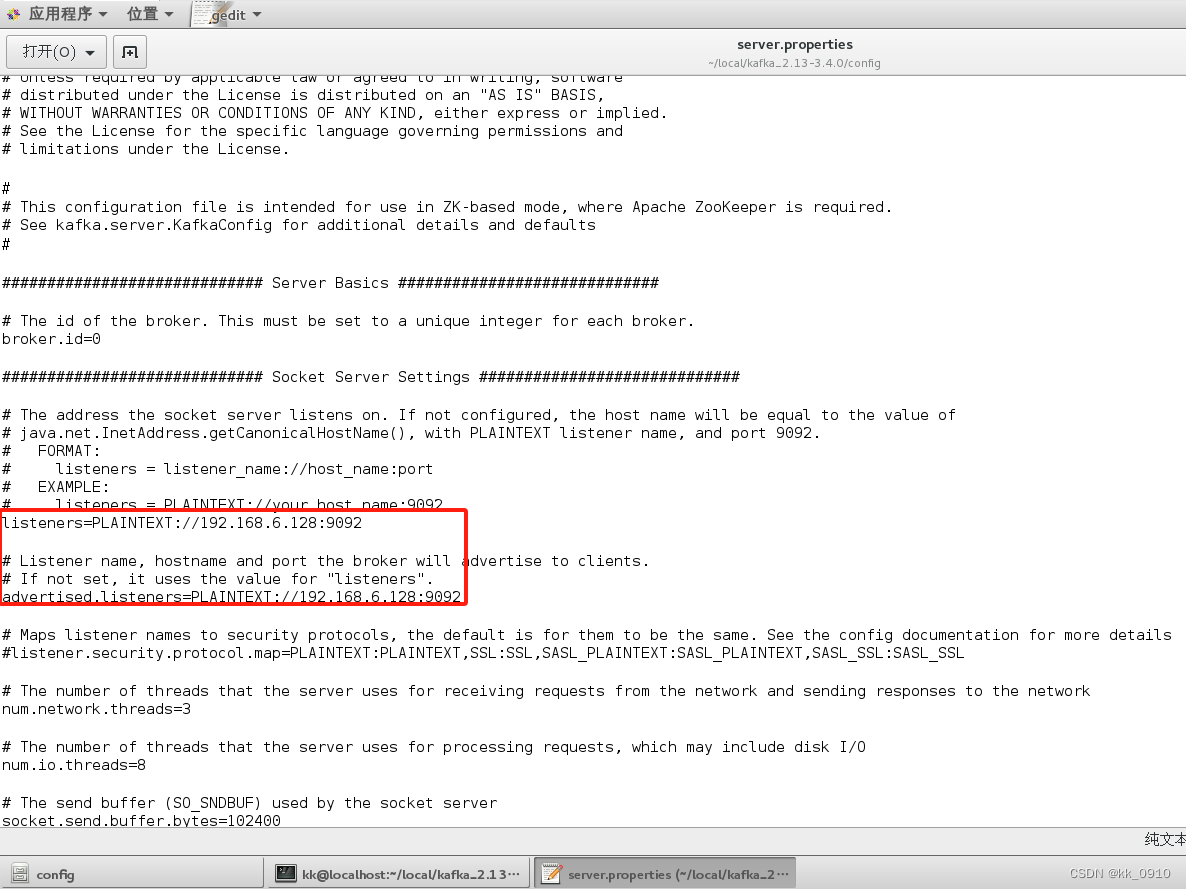
5. 启动kafka
nohup bin/kafka-server-start.sh config/server.properties &?6. jps检查是否启动成功

基本命令使用
1. 创建topic
bin/kafka-topics.sh --create --topic test --bootstrap-server localhost:90922. 查看topic
bin/kafka-topics.sh --describe --topic test --bootstrap-server localhost:9092
3. 发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test4. 消费消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test5. 从起点开始消费消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic test
6. 从指定地方消费消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic test
?7. 分组消费消息
示例:创建三个消费者A,B,C, 其中A和B属于testGrroup消费者组, C属于testGrroup2消费者组
#开一个终端1, 配置消费者组testGrroup
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGrroup --topic test
#开一个终端2, 配置消费者组testGrroup
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGrroup --topic test
#开一个终端3, 配置消费者组testGrroup2
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGrroup2 --topic test
#结果: 终端1和2会竞争消息, 一条只会被其中一个实例消费; 终端3独享消费群组, 每条消息能消费集群版
==
消息模型
成员组成
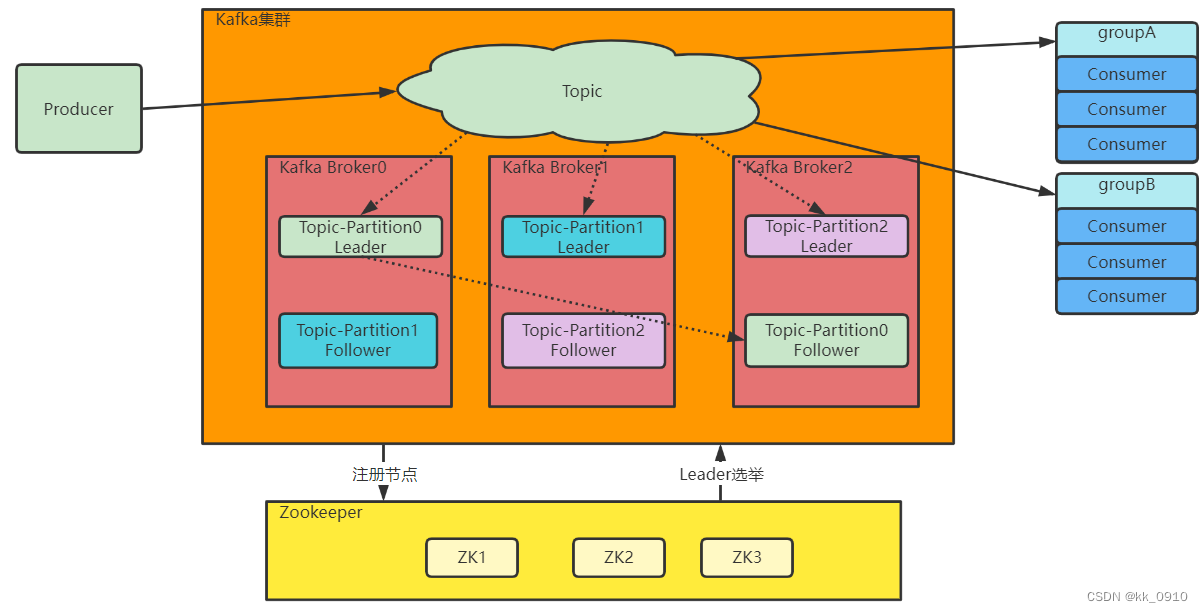
1. Topic(主题):
- 消息在 Kafka 中通过主题进行分类,每个主题都是一个消息的类别。
- 生产者将消息发布到一个或多个主题,消费者订阅一个或多个主题。
- 主题在 Kafka 集群中的分区上进行分布,每个分区可以看作是一个有序的日志文件。
2. Partition(分区):
- Topic只是一个逻辑概念,而Partition就是实际存储消息的组件。每个Partiton就是一个queue队列结构。所有消息以FIFO先进先出的顺序保存在这些Partition分区中。
- 每个主题可以划分为一个或多个分区,分区是 Kafka 消息的基本存储单元。
- 分区允许水平扩展和并行处理,提高了整个系统的吞吐量。
- 分区内的消息有序存储,保证了分区内的顺序性。
3. Producer(生产者):
- 生产者负责将消息发布到指定的主题。
- 生产者可以指定消息的键(key),Kafka 根据键将消息发送到特定的分区。
- 生产者将消息发送到分区的 Leader 副本,并可以等待确认或异步发送。
4. Consumer(消费者):
- 消费者订阅一个或多个主题,从中获取消息。
- 消费者可以以消费者组(Consumer Group)的形式进行组织,每个组内的消费者共享订阅的主题的消息。
- 每个分区只能由同一消费者组内的一个消费者进行消费,确保了消息在消费时的顺序性。
5. Broker(代理服务器):
- Broker 是 Kafka 集群中的节点,负责存储和处理消息。
- 每个分区在集群中有多个副本,其中一个是 Leader 副本,其余是 Follower 副本。Leader 负责处理读写请求,Follower 复制 Leader 的数据。
6. Zookeeper:
- Kafka 使用 ZooKeeper 来进行集群管理和协调。
- ZooKeeper 管理 Kafka 集群的节点、分区的分配,以及监视 Broker 的健康状态。
?成员关系
-
Topic 和 Partition:
- 一个 Topic 包含一个或多个 Partition。
- 每个 Partition 中的消息是有序的,可以保证 Partition 内的消息顺序性。
- Partition 的数量和分布影响了 Kafka 集群的并发处理能力和水平扩展性。
-
Partition 和 Broker:
- Partition 在 Kafka 集群中分布在多个 Broker 上,以实现水平扩展。
- 每个 Partition 在任意时刻只有一个 Broker 的副本是 Leader,其余的是 Follower。
- Leader 负责处理读写请求,Follower 负责复制 Leader 的数据,以实现高可用性和容错性。
-
Topic 和 Broker:
- 一个 Topic 的多个 Partition 可以分布在多个 Broker 上。
- Topic 的所有 Partition 的所有副本的集合构成了整个 Kafka 集群的数据。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!