快乐学Python,数据分析之获取数据方法「公开数据或爬虫」
学习Python数据分析,第一步是先获取数据,为什么说数据获取是数据分析的第一步呢,显而易见:数据分析,得先有数据,才能分析。
作为个人来说,如何获取用于分析的数据集呢?
1、获取现成的数据集
获取数据集的第一种方式,就是获取行业上已经有人整理好的数据集。目前大数据行业持续火爆,数据本身已经变成了一种产业,自然也包含数据集。这些有人已经整理过的数据集,我们统称为现成的数据集。
现成的数据集大概有两种:比赛数据集和行业数据集。
(1)比赛数据集
高水平的数据分析大赛毫无疑问是大数据行业火爆的一大有力证明。现如今,数据分析比赛已经不再简单的是数据分析师、数据科学家们互相切磋的比赛,而演变成了各路公司将自己公司遇到的数据难题抛出来悬赏各路英雄来解决的平台,充满了来自现实世界的挑战。
主流数据分析大赛的比赛题目往往就是赞助商公司面临的实际问题,而数据集也往往来自赞助商公司的真实数据,经过一定脱敏之后开放给所有参赛的数据分析师。比赛中拿到最好结果的团队可以收到不菲的大赛奖金,另一方面其贡献的解决方案可以帮助公司找到后续业务发展的方向,最后,比赛过程中公司贡献的数据集又为数据分析爱好者和初学者们提供了绝佳的学习材料,可谓是一举三得。
作为数据初学者的我们,自然可以去数据分析大赛上找一些现成的数据集来练手用。目前数据分析比赛蓬勃发展,呈现越来越多的趋势。目前数据分析大赛认可度比较高的比赛一个是国际上的 kaggle,一个是国内的天池。
- kaggle 可以说是所有数据分析大赛的鼻祖,也是目前世界范围内规模最大的数据分析比赛,但存在两个问题:一是全英文网站,二是国内访问速度较慢。整体来说对新手并不是很友好。
- 天池是国内目前影响力最大的比赛,整体平台的配置、数据集的丰富度都有保障,并且还有一系列新手赛帮助入门。
这里以天池平台为例,示范如何获得比赛的数据集。
(1)访问天池官网:https://tianchi.aliyun.com/,并使用淘宝账户注册、登录。
(2)选择天池大赛 - 学习赛,进入学习赛题列表。
(3)下滑列表,选择二手车交易价格预测比赛,标题为:零基础入门数据挖掘 - 二手车交易价格预测”。
(4)进入比赛详情页后,点击报名参赛。
(5)点击左侧的赛题与数据,进入数据集的页面,这个页面的上方是数据集的下载链接,下面则是数据集的描述。
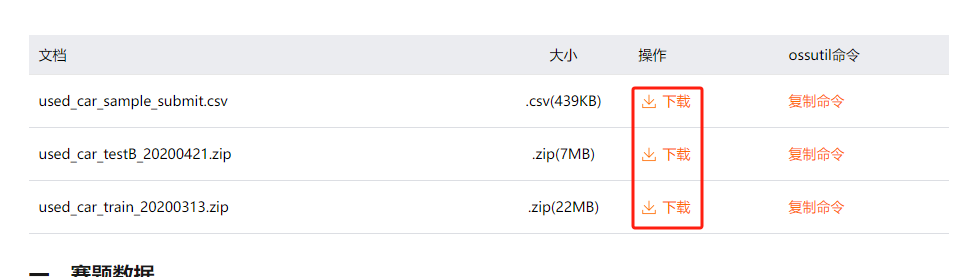
因为分析比赛的数据集都会分为训练集和测试集,我们现阶段不用关心这个,直接看训练集(train.csv) 即可。
(2)行业数据集
除了比赛用的数据集之外,个人还可以从一些行业公开的网站上获得用于分析的数据。在这里列举三个比较常用的,你可以简单参考。
(1)清博智能:http://www.gsdata.cn/
清博智能是一个聚焦新媒体行业的大数据服务网站,提供了大量新媒体渠道的优质榜单,比如微信、头条、抖音……。只需要登录便可查看,同时支持下载为 Excel 格式。
(2)房天下房价指数:https://fdc.fang.com/index/
顾名思义,这里提供的是房价相关的数据集,但数据均值以表格的形式提供的,没有 Excel 的形式。
(3)移动观象台:http://mi.talkingdata.com/app-rank.html
移动观象台提供了热门手机 App 的排行数据,手机 App 排行一直都是数据分析的热点。很多公司都希望通过对榜单进行分析来抓住用户的最新的兴趣以及来调整自己的业务方向。不过遗憾的是,它和房天下一样,移动观象台仅提供了网页访问,不可以下载 Excel 或者 CSV 格式文件。
(3)存在的问题
无论是比赛数据集,还是行业公开的数据集,都有比较明显的短板。
- 比赛数据集:数据集都是脱敏的,往往只能发现一些数据背后的隐藏关系,适合拿来测试一些数据挖掘算法,对于初级的数据分析帮助不大。
- 行业公开数据集:绝大多数行业公开数据集都只能提供网页浏览或者 PDF,基本没有 Excel 可下载,所以只能看,很难在此基础上做自己的分析,而且免费用户能看的都比较有限。
简单来说,虽然个人可以从数据分析比赛和部分行业数据网站访问数据,但这两个渠道都存在一些问题,不能完全满足我们做数据分析的需要。我们还有什么方式可以获取到数据进行分析呢? 首先我们可以先想一下,什么地方的数据最多?答案就是:互联网本身。
2、从广袤的互联网中构建数据集
互联网包含成千上万个网站,而每个网站又包含数不清的帖子、评论、影评等。综合来说,互联网拥有着取之不尽,用之不竭的数据。如果我们可以直接从互联网根据需要拿数据进行分析,那简直不要太美。
一方面,来自互联网的分析数据都是真实用户产生的,分析的结论自然天生就具备极高的可信度。另一方面,来自互联网的数据大多都具备一定的规模,非常适合拿来实验各种各样的数据分析技巧,是学习数据分析的不二之选。
那现在问题来了,互联网的数据,基本都是通过一个个不同的网页的形式呈现。这种类型的数据如果进行数据分析呢? 我们知道,主流的数据分析往往都是基于表格,比如 Excel 或者CSV 文件。那有没有办法把互联网上的一个个网页变为能够被分析的表格呢?答案是肯定的。
通过Python 爬虫这门神奇的技术,就可以做到这件事情。接下来,我们先来了解一下爬虫的基础。如何实现爬虫会在后续文章中一一阐释。
(1)什么是爬虫?
爬虫是一类程序的名称,也有人称之为网络爬虫。爬虫程序简单理解就是下载网页并按照一定的规则提取网页中的信息,而 Python 则是市面上最适合用来开发爬虫程序的语言。
我们通过一个例子来说明爬虫到底可以干什么。
以某电视剧网站为例,我们看到的网页是这样的。
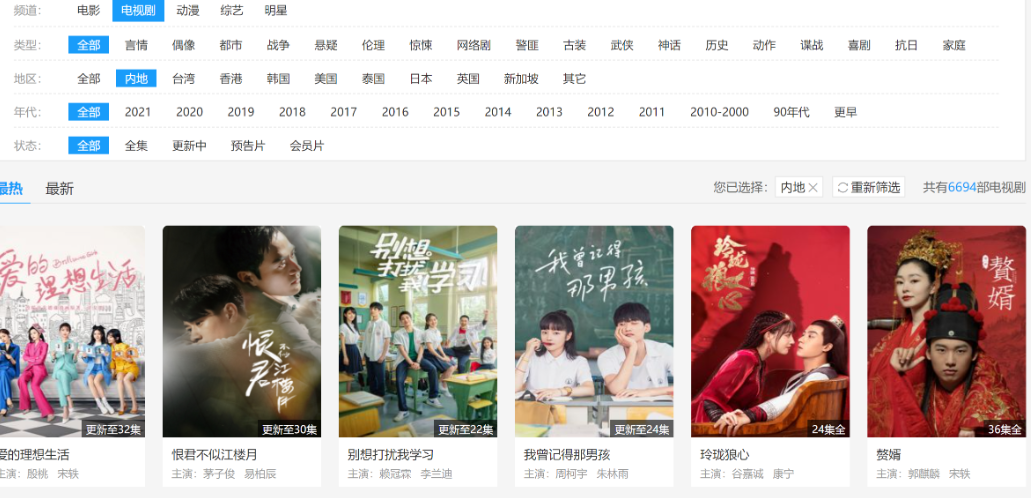
但我们希望能够整理出一个电视剧的表格,比如下面这样:
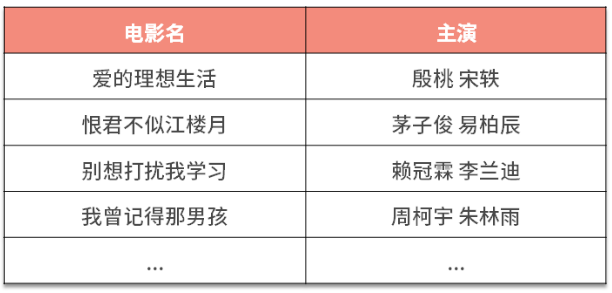
一种方法是,我们看着网页,把电视剧和主演一个一个抄到 Excel 里。但这样比较麻烦,而且电视剧有几十页,根本不可能抄得完。
另一种方式就是 Python 爬虫,我们使用爬虫将网页中我们想要的内容(电视剧名、演员名)提取出来存放在 Python 的列表中。因为整个过程是用代码实现的,所以不管最终有多少页,我们使用一个循环就可以轻而易举获得所有电视剧的信息,最后再把保存了结果的列表存为 Excel 或者CSV 格式即可。效率相比人肉抄写提升百倍。
那现在问题来了。爬虫这么逆天的工具,背后的原理和流程是怎么样的呢?
(2)爬虫的主要流程
本质上,爬虫的原理类似于我们拿来上网的浏览器,比如 Chrome、Edge 这些。我们首先来说一下浏览器的工作原理,以 Chrome 为例:
浏览器的流程大致分为四个步骤:
-
用户输入网址,告诉浏览器想看的网页;
-
浏览器根据网址,去找网址对应的服务器请求网页内容;
-
网址对应的服务器将网页内容返回给浏览器;
-
浏览器将收到的网页内容画在窗口中展示给用户。
了解了浏览器的工作内容,我们来看一下爬虫的工作流程:
爬虫的工作主要包括以下步骤:
-
用户在代码中指定要抓取的网页的网址;
-
请求网址对应的服务器;
-
服务器返回网页内容;
-
根据用户指定的规则提取感兴趣的内容(比如之前的例子,我们仅对电视剧名字和演员名感兴趣)。
从上面的例子可以看出,我们要实现一个爬虫程序,主要要实现三大模块。
-
数据请求:可以像浏览器一样,根据一个网址去下载对应的网页内容。
-
网页分析:根据规则,从网页繁多的文字、图片中筛选出感兴趣的内容。
-
数据保存:抓取到的感兴趣的内容保存到CSV、Excel 文件中,为后续的分析环节做好准备。
(3)爬虫的注意事项
爬虫的功能十分强大,如武侠小说写的那样,越是强大的武器越要讲究正确地使用,滥用往往会导致很多不好的事情发生。
爬虫也是一样,一方面,我们可以通过爬虫来直接抓取互联网上的网页信息来构建我们的数据集。但另一方面,网站数据的所有权毕竟还是网站自身。虽然爬虫本质和浏览器的角色一样,但爬虫可以做到短时间就爬取大量的网页和数据,所以在开发与使用爬虫技术的时候,我们一定要注意以下两点:
-
适当降低抓取网页的频率,以免给相关的网站服务器产生负担;
-
抓取到的数据仅作自己分析使用,切忌传播或销售,否则可能有违法的风险。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!