【Spark精讲】一文讲透SparkSQL物理执行计划
SparkSQL整体计划生成流程

大体分三步:
(1)由 SparkSqlParser 中的 AstBuilder执行节点访问,将语法树的各种Context节点转换成对应的 LogicalPlan 节点,从而成为一棵未解析的逻辑算子树(Unresolved LogicalPlan),此时的逻辑算子树是最初形态,不包含数据信息与列信息等。
(2)由 Analyzer将一系列的规则作用在 Unresolved LogicalPlan 上,对树上的节点绑定各种数据信息,生成解析后的逻辑算子树(Analyzed LogicalPlan)。
(3)由 SparkSQL中的优化器(Optimizer)将一系列优化规则作用到上一步生成的逻辑算子树中,在确保结果正确的前提下改写其中的低效结构,生成优化后的逻辑算子树(Optimized LogicalPlan) 。
SparkSQL物理计划生成流程

大体分三步:
(1)由 SparkPlanner 将各种物理计划策略( Strategy)作用于对应的 LogicalPlan 节点上,生成 SparkPlan列表(注: 一个 LogicalPlan可能产生多种 SparkPlan)。
(2)选取最佳的 SparkPlan,在 Spark2.1 版本中的实现较为简单,在候选列表中直接用 next() 方法获取第一个。
(3)提交前进行准备工作,进行一些分区排序方面的处理,确保 SparkPlan各节点能够正确执行,这一步通过 prepareForExecution()方法调用若干规则(Rule)进行转换。
SparkPlan
Spark SQL 最终将 SQL 语句经过逻辑算子树转换成物理算子树。 在物理算子树中,叶子类型的 SparkPlan节点负责呗无到有”地创建 RDD,每个非叶子类型的 SparkPlan节点等价于在 RDD 上进行一次 Transformation,即通过调用 execute()函数转换成新的 RDD,最终执行 collect() 操作触发计算,返回结果给用户 。
如下图所示, SparkPlan 在对 RDD 做 Transformation 的过程中除对数据进行操作外,还可能对 RDD 的分区做调整。 此外, SparkPlan 除实现 execute 方法外,还有一种情况是直接执行 executeBroadcast 方法,将数据广播到集群上 。

具体来看, SparkPlan 的主要功能可以划分为 3 大块 。 首先,每个 SparkPlan 节点必不可少地 会记录其元数据( Metadata)与指标( Metric)信息,这些信息以 Key-Value 的形式保存在 Map 数 据结构中,统称为 SparkPlan 的 Metadata与 Metric体系 。 其次,在对 RDD 进行 Transformation操 作时,会涉及数据分区( Partitioning)与排序( Ordering)的处理,称为 SparkPlan 的 Partitioning 与 Ordering体系;最后,SparkPlan作为物理计划,支持提交到 SparkCore去执行,即 SparkPlan 的执行操作部分,以 execute 和 executeBroadcast 方法为主。此外, SparkPlan 中还定义了 一 些辅 助函数,如创建新谓词的 newPredicate 等 ,这些细节本章不再专门讲解 。
在 Spark 2.1 版本中, Spark SQL 大约包含 65 种具体的 SparkPlan 实现,涉及数据源 RDD 的 创建和各种数据处理等。 根据 SparkPlan 的子节点数目,可以大致将其分为 4类。 如下图所示,分别为 LeafExecNode、 UnaryExecNode、 BinaryExecNode 和其他不属于这 3 种子节点的类型,下面分别对这几种类型进行简要介绍。
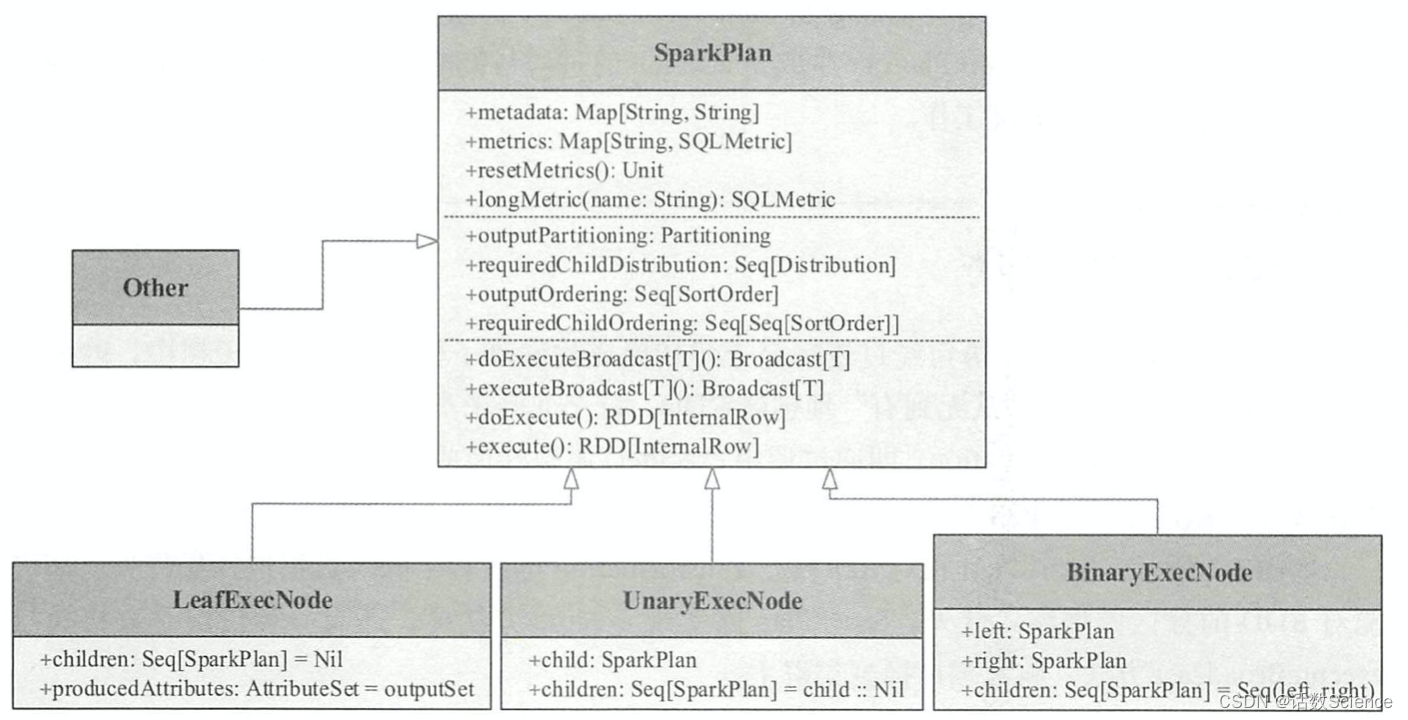
?
LeafExecNode类型
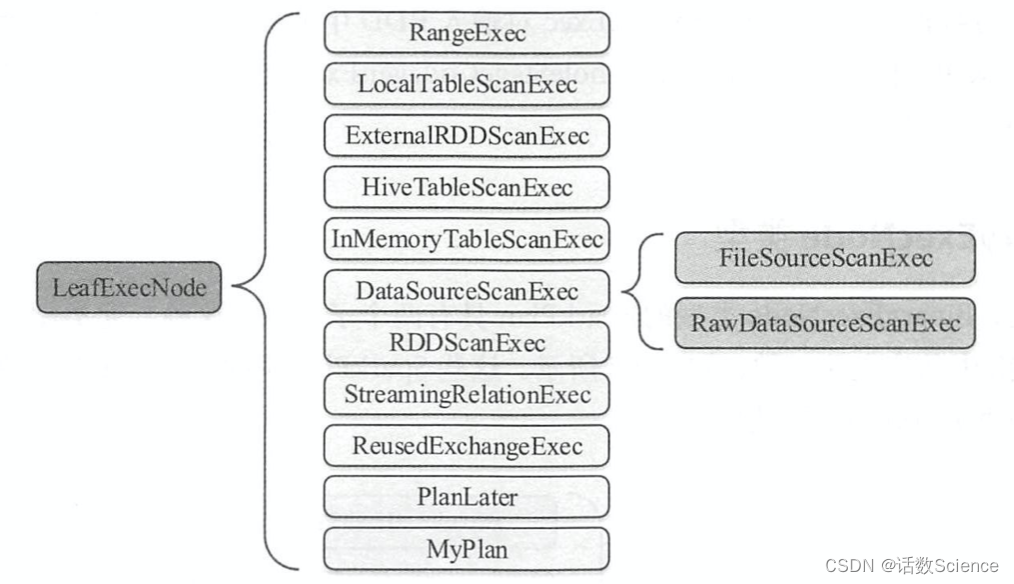
叶子节点类型的物理执行计划 不存在子节点。物理执行计划中与数据源相关的节点都属于该类型。 在 Spark SQL 中,叶子节点类型的物理执行计划共有13种,如下图所示 。 其中, DataSourceScanExec作为基类,具体的实现包括 FileSourceScanExec和 RawDataSourceScanExec 两种。
LeafExecNode 类型的 SparkPlan 负责对初始 RDD 的创建。 例如, RangeExec 会利用 Spark- Context 中的 parallelize方法生成给定范围内的 64位数据的 RDD, HiveTableScanExec会根据 Hive 数据表存储的 HDFS 信息直接生成 HadoopRDD, FileSourceScanExec 根据数据表所在的源文件 生成 FileScanRDD。
UnaryExecNode类型
UnaryExecNode 类型的物理执行计划的节点是一元的, 意味着只包含 1 个子节点 。 在 Spark2.1版本中, UnaryExecNode类型的物理执行计划共有37种,如下图所示。 实际上, UnaryExecNode 类型的物理计划也是数量最多的类型 。
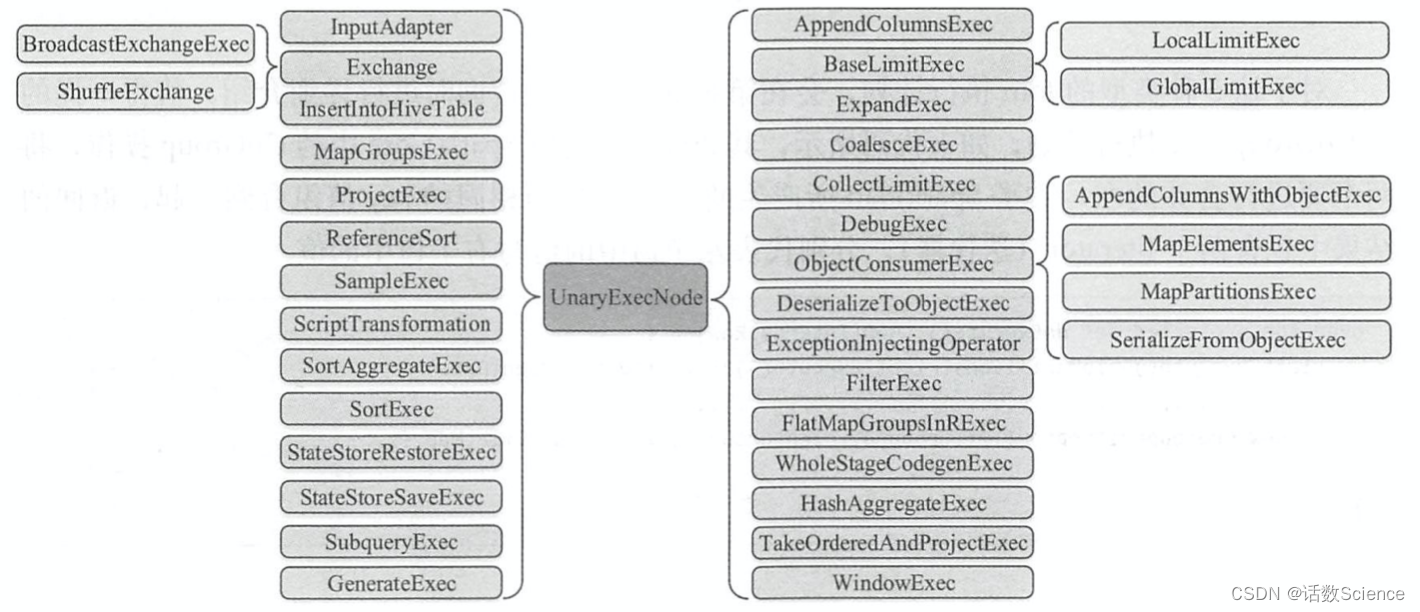
UnaryExecNode节点的作用主要是对 RDD进行转换操作。 例如,之前案例所生成的物理算子树中, ProjectExec 和 FilterExec 分别对子节点产生的 RDD 进行列剪裁与行过滤操作 。
Exchange负责对数据进行重分区, SampleExec对输入 RDD 中的数据进行采样, SortExec按照一 定条件对输入 RDD 中数据进行排序, WholeStageCodegenExec 类型的 SparkPlan 将生成的代码 整合成单个 Java 函数 。
BinaryExecNode类型
顾名思义, BinaryExecNode类型的 SparkPlan 具有两个子节点,这种二元类型的物理执行计划在 SparkSQL 中共定义了 6种,如下图所示。 这些 SparkPlan 中除 CoGroupExec外,其余的 5 种都是不同类型的 Join 执行计划 。
 ?对于这 5种类型的 Join执行计划,后面会在讲Join查询时进行详细介绍。 值得一提的是 CoGroupExec执行计划,如下代码所示,其处理逻辑类似 SparkCore 中的 CoGroup操作,将 两个要进行合并的左、右子 SparkPlan 所产生的 RDD,按照相同的 key值组合到一起,返回的结果中包含两个Iterator (迭代器),分别代表左子树中 的值与右子树中的值。
?对于这 5种类型的 Join执行计划,后面会在讲Join查询时进行详细介绍。 值得一提的是 CoGroupExec执行计划,如下代码所示,其处理逻辑类似 SparkCore 中的 CoGroup操作,将 两个要进行合并的左、右子 SparkPlan 所产生的 RDD,按照相同的 key值组合到一起,返回的结果中包含两个Iterator (迭代器),分别代表左子树中 的值与右子树中的值。

其他类型的SparkPlan
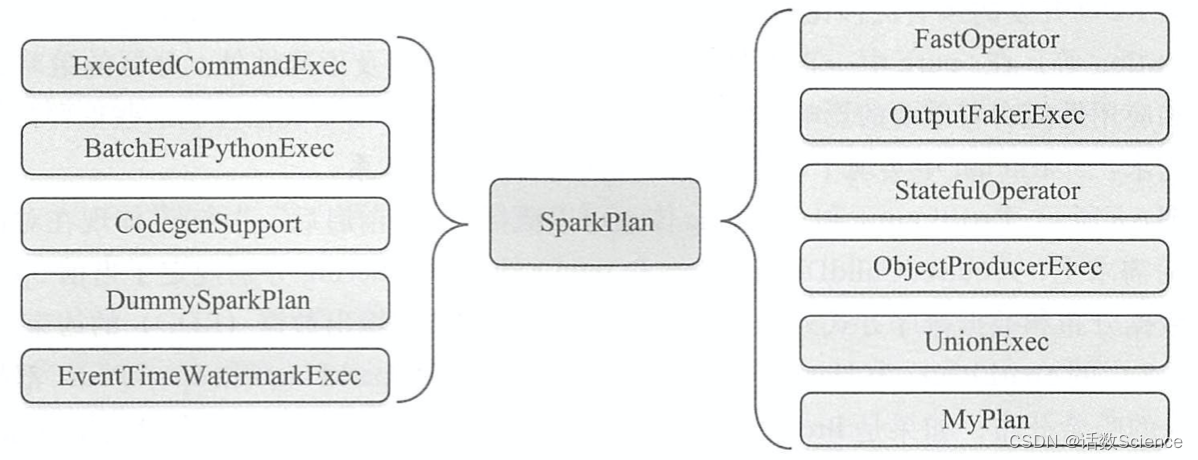
除上述 3种类型的 SparkPlan外, SparkSQL 中还有 11 个其他类型的物理执行计划 。 如下图所示,这 10种 SparkPlan 中除 CodeGenSupport和 UnionExec外,其他几种用到的场景并不多见。
例如, DummySparkPlan、 FastOperator和 MyPlan均出现在单元测试中,其中 DummySparkPlan对每个成员赋予默认值, MyPlan 则用于在 Driver端更新 Metric信息。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!