无魔搭+ 函数计算: 一键部署,缩短大模型选型到生产的距离
引言
面对魔搭 ModelScope 社区提供的海量模型,用户希望快速进行选型并生产使用起来,但在此之前,却一定会面临算力管理难、模型部署难等一系列问题,那么能否实现快速把选定的模型部署在云端功能强大的 GPU 上,由云端负责服务,扩展,保护和监控模型服务,同时免于运维和管理云上算力等基础设施呢?魔搭ModelScope +函数计算 FC 给了这样一种方案。
魔搭+函数计算,一键部署模型上云
魔搭 ModelScope 社区模型服务 SwingDeploy 支持将模型从魔搭社区的模型库一键部署至用户阿里云账号的云资源上,并根据模型资源要求为用户自动推荐最佳部署配置。让开发者可以将魔搭开源模型一键部署至阿里云函数计算,当选择模型并部署时,系统会选择对应的机器配置。按需使用可以在根据工作负载动态的减少资源,节约机器使用成本。5分钟完成从开源模型至模型推理 API 服务的生产转换。
得益于阿里云函数计算的产品能力,魔搭 SwingDeploy 后的模型推理 API 服务默认具备:极致弹性伸缩(缩零能力)、GPU 虚拟化(最小 1GB 显存粒度)、异步调用能力、按用付费、闲置计费等能力,这些能力帮助算法工程师大大加快了魔搭开源模型投入生产的生命周期。
以百川智能的大型语言模型为例
接下来,我们将演示如何利用魔搭 ModelScope 社区 的一键部署技术(SwingDeploy),选取百川智能的大语言模型(LLM)为案例,将其部署至函数计算平台并启用闲置计费。我们将提供一系列详尽的步骤指南:
准备工作
- 打开 ModelScope 官网,登录/注册账号

- 绑定阿里云账号后,可使用在线调试、训练及部署等能力
模型部署
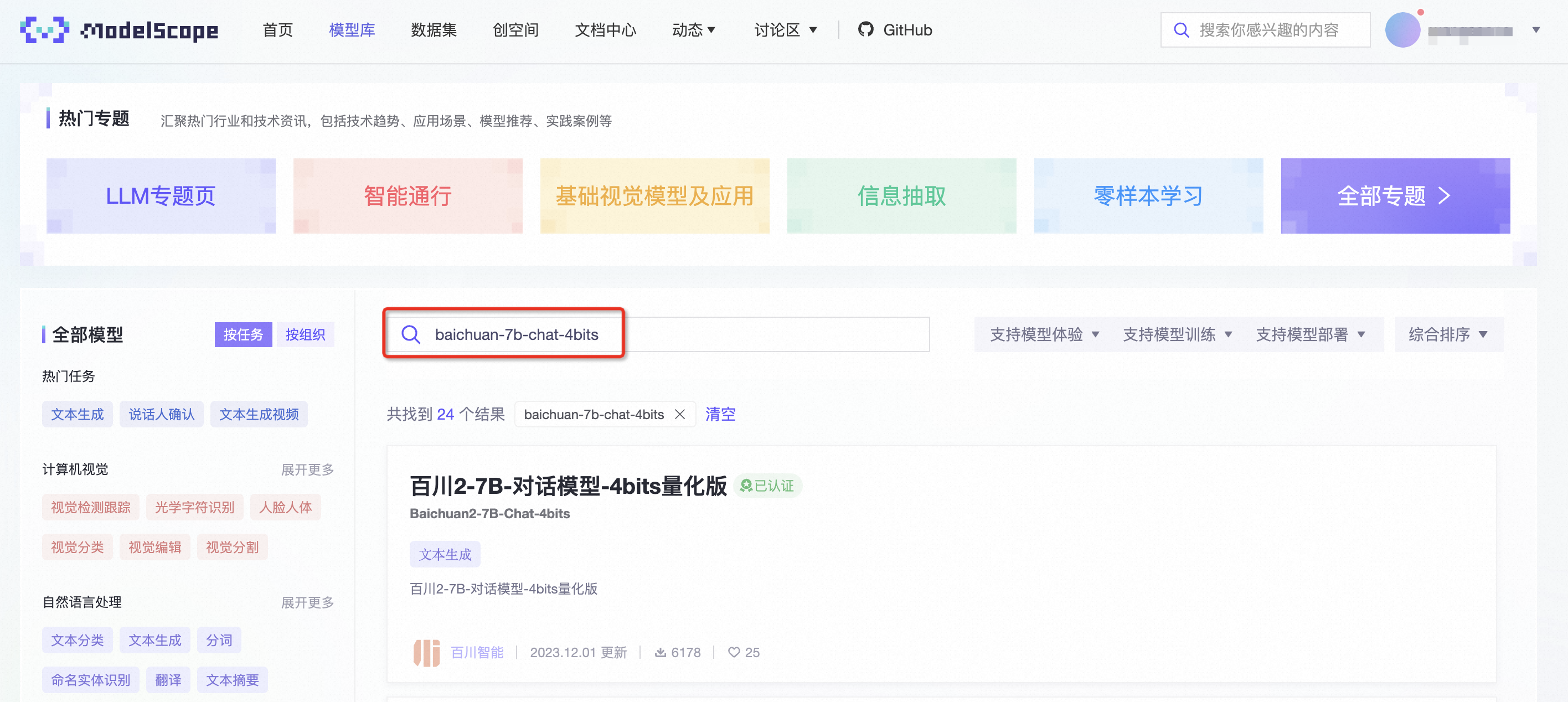
- 导航至模型卡片:请在魔搭 ModelScope 社区的模型库页面进行搜索,定位到"baichuan2-7b-chat-4bits",并点击进入该模型的详细页面。为了便捷,您还可以通过提供的URL直接访问该模型卡片。
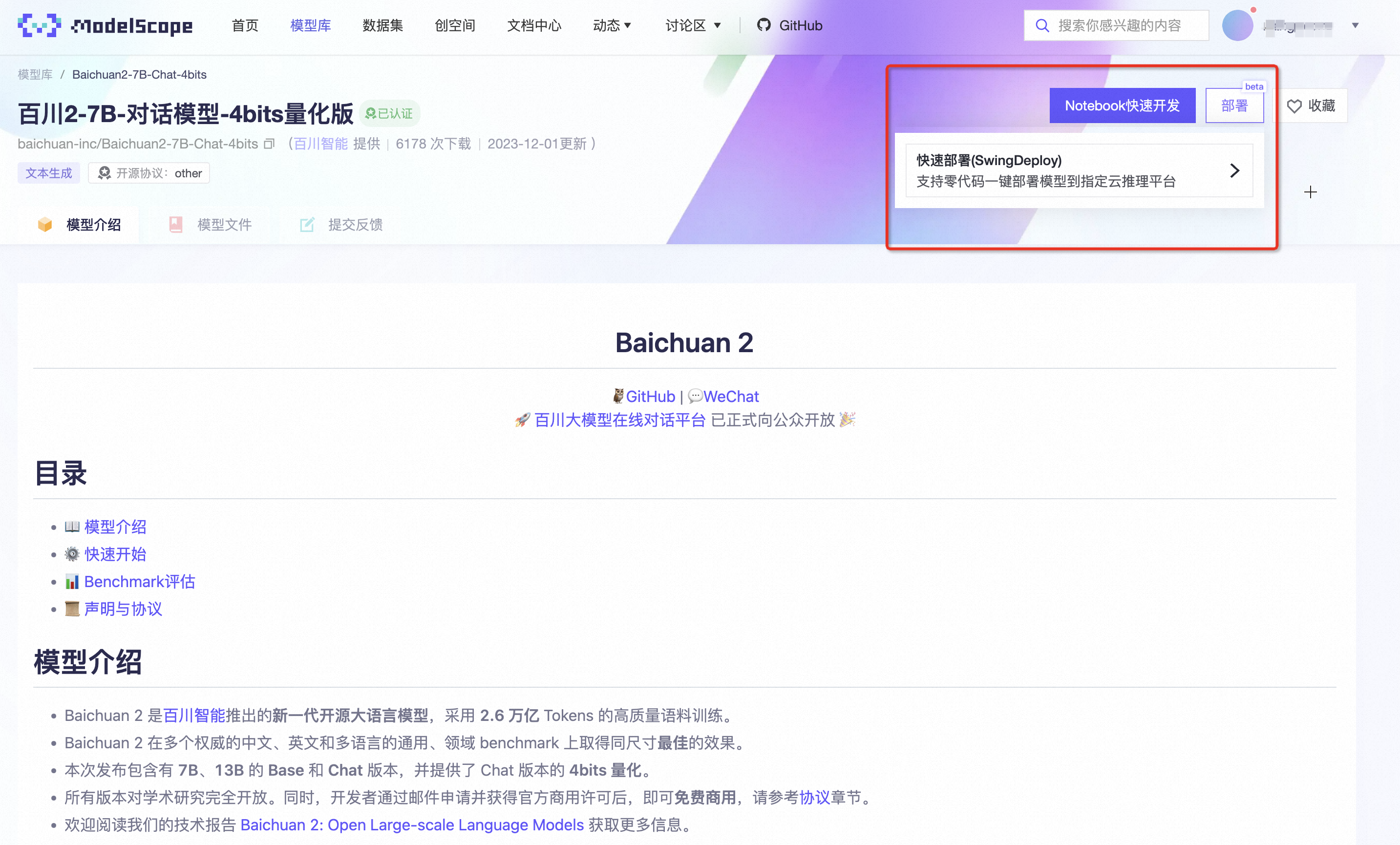
- 执行快速部署操作:请在模型卡片的右上角找到并点击“部署”按钮,并从下拉菜单中选择“快速部署(SwingDeploy)”,随后选择“函数计算(FC)”作为目标部署平台。
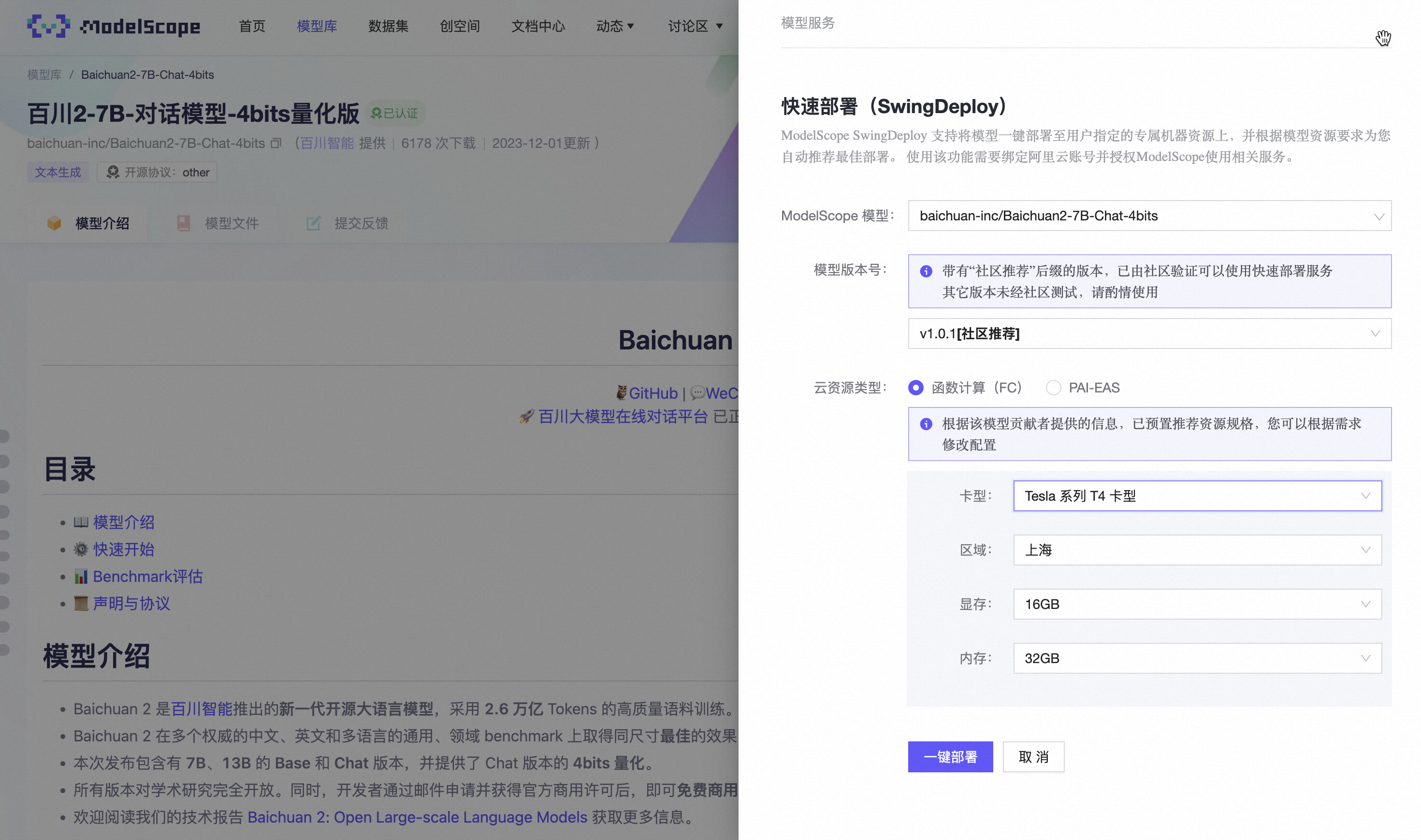
在随后出现的弹窗中,您将有机会对模型的部署参数进行详细配置,这包括选择适当的模型版本、部署的地理区域、显卡型号以及需要的显存容量等。完成这些必要设置后,请点击“一键部署”以初始化部署过程。
注意:目前函数计算 GPU 的闲置计费模式只适用于杭州和上海地区,并且仅限于整卡使用。因此,在配置部署选项时,请确保地域设置为杭州或上海,并选择相应的显存容量,即 16GB 对应于T4显卡型号,或 24GB 对应于A10 显卡型号。
- 确认部署成功:成功执行“一键部署”后,ModelScope 将开始将模型部署到函数计算云服务,此过程通常需要1至5分钟完成。部署完毕时,您可返回 ModelScope 主页,导航至“模型服务”下的“部署服务(SwingDeploy)”板块,以确认部署状态显示为“部署成功”。
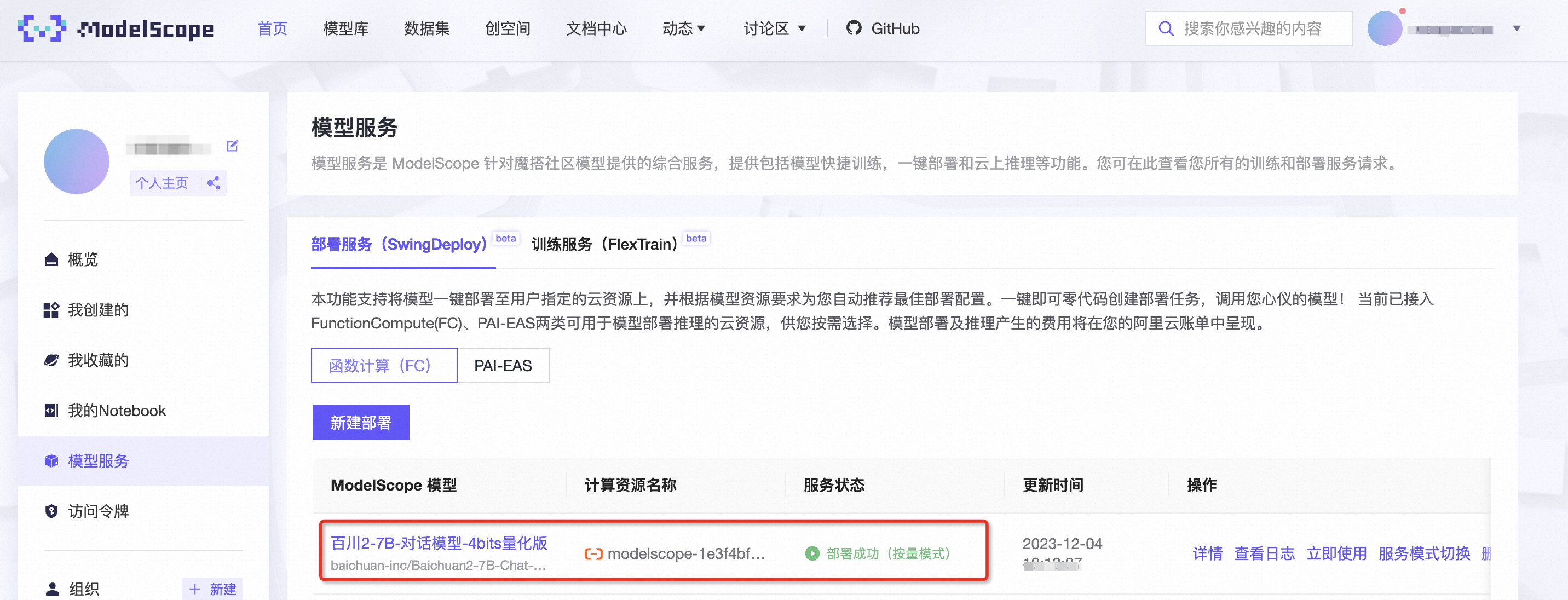
启用预留闲置模式
- 将模型服务配置为预留模式:您可能已经发现,ModelScope 会默认使用按量模式进行部署,为了优化成本和性能,您需要将模型服务配置为预留模式。这可以通过点击“服务模式切换”至“预留模式”来实现。
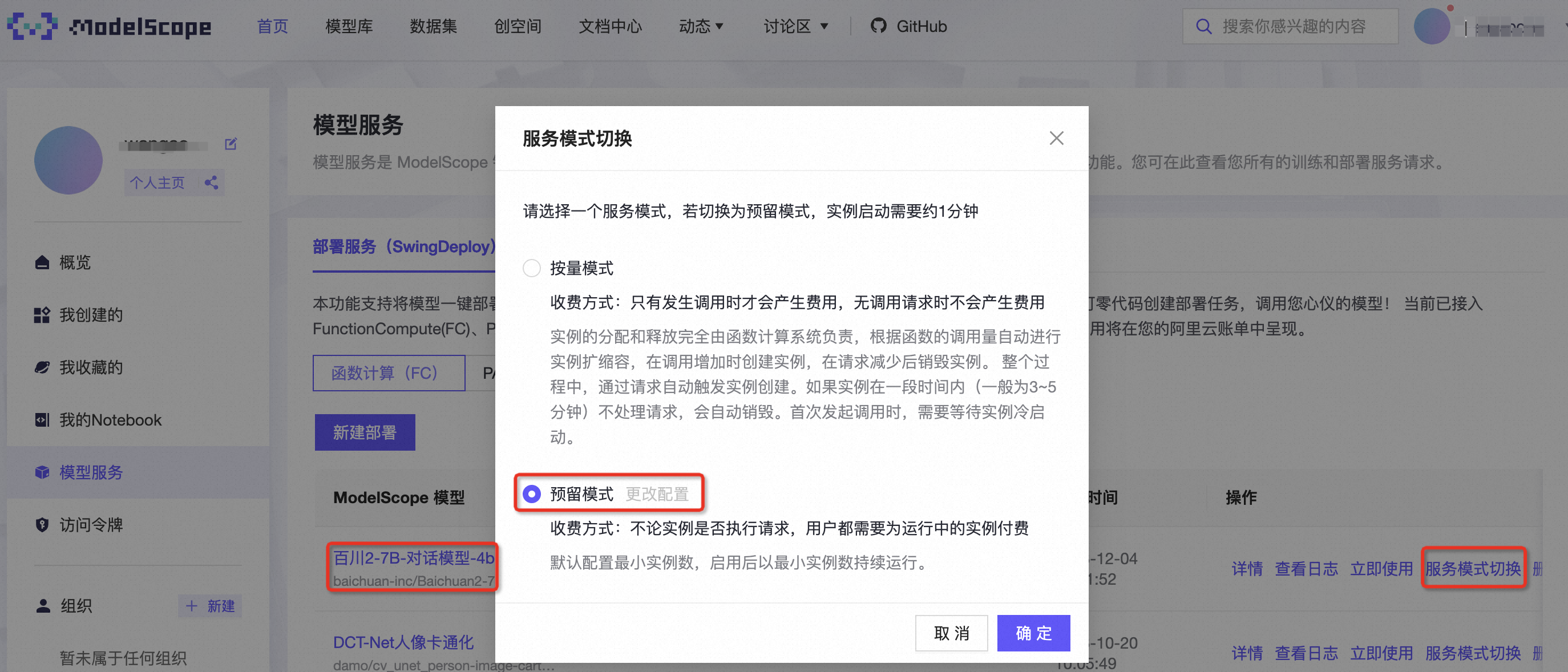
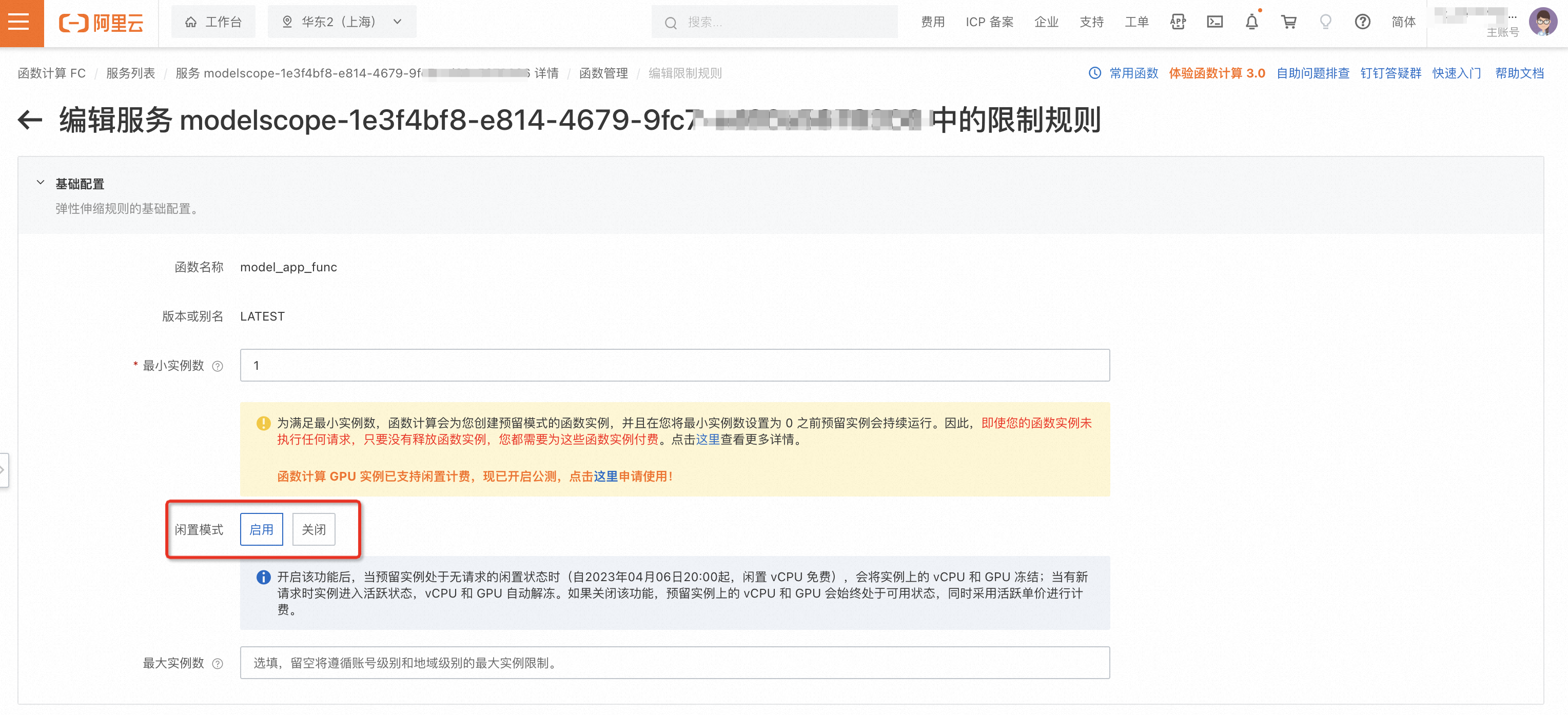
- 激活预留模式的闲置计费功能: 完成服务模式的切换至“预留模式”之后,您需要再次点击服务模式的切换按钮。随后,在弹出的窗口中选择“更改配置”,这将引导您跳转至函数计算控制台。在控制台的“函数弹性管理”页面,激活“闲置计费选项并保存设置,以启用函数计算 GPU 函数的闲置计费模式。这将有助于您在保留资源的同时优化成本效益。
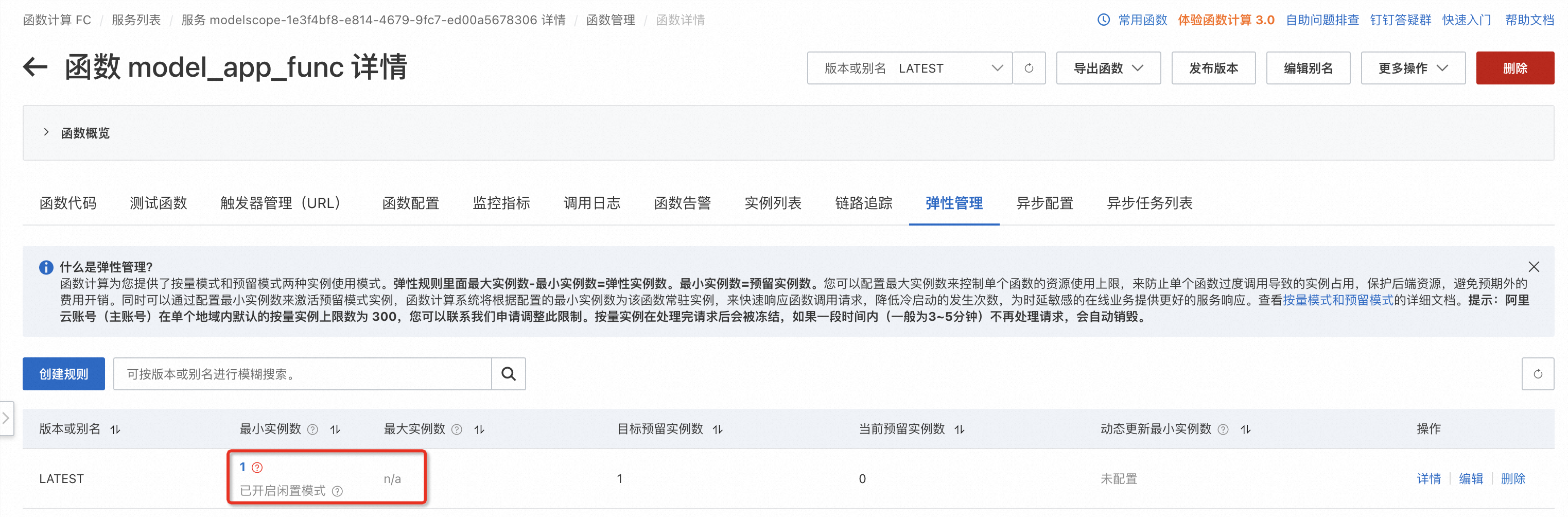
在成功激活闲置计费模式后,在函数的弹性管理界面中,您应该能够看到已明确标注“闲置计费模式已开启”。此时,当“当前实例数”与“目标预留实例数”一致时,表明所有的闲置实例均已成功启动并处于待命状态。
开始使用
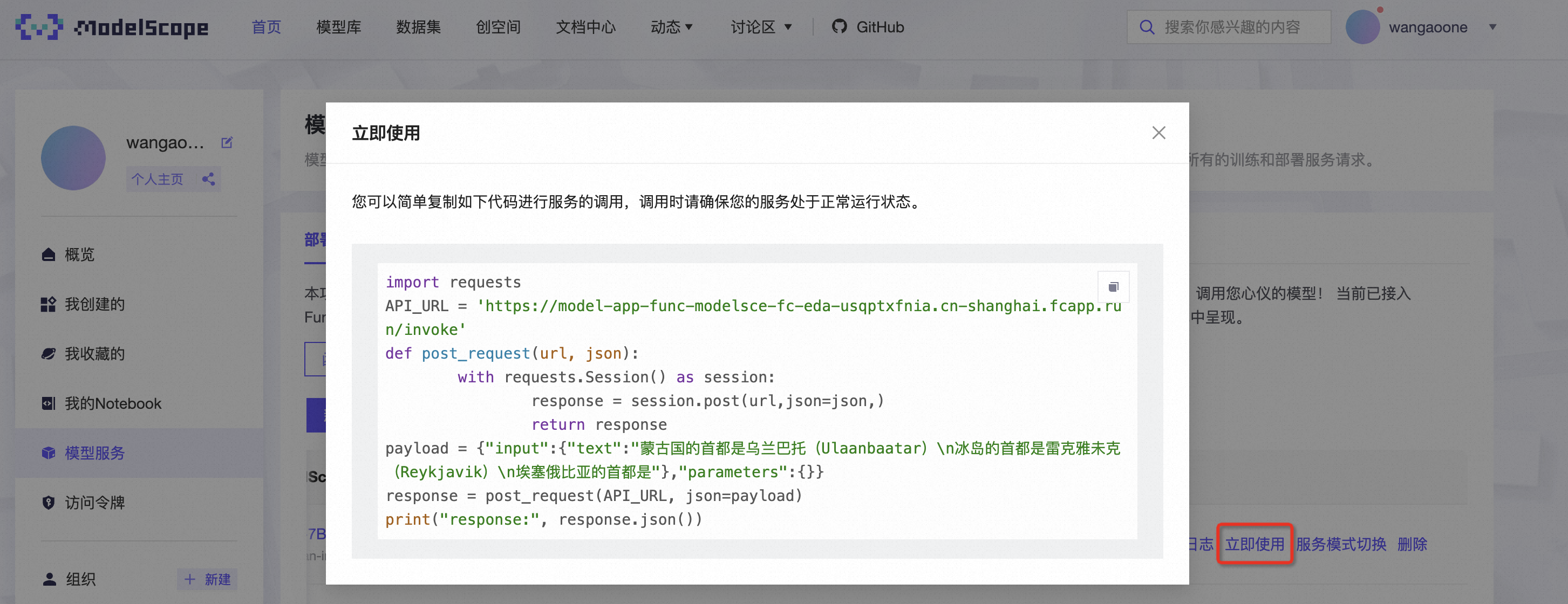
根据魔搭 ModelScope 模型服务里的立即使用说明,我们可以顺利调用到该次部署的 LLM 模型
LLM 一览表
由于当前社区以及多种层出不穷的大语言模型(LLM),本表格仅列举了当前热度较高的常用 LLM 基础模型,在其之上的微调模型同样是可以部署至函数计算平台,并开启闲置预留模式。
如果您有任何反馈或疑问,欢迎加入钉钉用户群(钉钉群号:11721331)与函数计算工程师即时沟通。
| 模型系列 | LLM模型 |
| 通义千问 | ● Qwen-14B ● Qwen-14B-Chat ● Qwen-14B-Chat-Int8 ● Qwen-14B-Chat-Int4 |
| ● Qwen-7B ● Qwen-7B-Chat ● Qwen-7B-Chat-Int8 ● Qwen-7B-Chat-Int4 | |
| ● Qwen-1.8B ● Qwen-1.8B-Chat ● Qwen-1.8B-Chat-Int4 | |
| 百川智能 | ● Baichuan2-13B-Base ● Baichuan2-13B-Chat ● Baichuan2-13B-Chat-4bits |
| ● Baichuan2-7B-Base ● Baichuan2-7B-Chat ● Baichuan2-7B-Chat-4bits | |
| ● Baichuan-13B-Chat | |
| ● Baichuan-7B | |
| 智谱.AI | ● ChatGLM3-6B |
| ● ChatGLM2-6B |
更多可支持的开源LLM模型请参考Modelscope
函数计算大幅降低用户 GPU 成本
随着 AGI 技术的迅速发展,各类型企业越来越多地依赖于 GPU 计算资源来推动他们的业务增长。对于正在使用或计划部署大型语言模型(LLM)等先进技术的客户来说,成本效率是一个重要的考虑因素。函数计算推出 GPU 闲置计费功能,在保障性能的前提下,可以帮助您大幅降低 GPU 的成本开销。
GPU 闲置计费 - 实时/准实时推理服务部署方式的革新
函数计算 GPU 闲置计费功能是一个行业领先的创新,它允许用户在不牺牲性能的前提下,以更低的成本使用 GPU 资源。这个新功能旨在解决传统 GPU 计费模式中的一个常见问题:即便 GPU 实例在没有服务请求时,用户仍然需要支付全部的资源消耗费用。现在,通过函数计算后台的显存管理,函数计算实例的 GPU 资源只有当请求到来时,才会被激活;当请求完成后,GPU 资源自动被函数计算平台冻结,用户无需为高昂的 GPU 使用费用买单。
部署 LLM 的成本效益分析
传统地部署大型语言模型(LLM)可能需要昂贵的 GPU 支持,尤其在需要大量计算资源时。但请求处理并不是每时每刻都处于活跃状态,势必存在流量的潮汐现象,后端的计算资源会出现空载导致成本的浪费。借助函数计算 GPU 闲置计费功能,用户的开销将会根据实际计算负载动态调整。
在函数计算的 GPU 闲置模式下,当实例活跃时 GPU 单价为0.000009元/GB * 秒;当实例进入闲置模式后,闲置 GPU 单价为0.00011/GB * 秒。闲置下的使用成本仅为活跃状态的1/10。
让我们以一个实际的例子来说明这种计费方式的成本效果:
某 AI 初创公司使用 LLM 微调模型提供客服机器人业务,客户需要确保客服机器人业务能够快速响应用户的请求,因此对于冷启动时间有较高的要求,所以无法选择按量付费模式,他们选择了预留实例模式来避免冷启动问题;但同时也发现,在一个小时内,GPU 资源并不是满载的,真正发生在 GPU 实例上的请求时长总计总计只有20分钟,进而他们选择了函数计算业内首创的闲置预留模式。
基于这样典型的场景,根据函数计算 GPU 的计费模式我们来算这样一笔账
- 仅使用 GPU 实例预留模式:
- 该客户会选择在业务高峰时期,预留10个16GB显存的实例为业务提供推理请求,GPU 实例使用单价,GPU 部分的资源开销约为6.34元/时/实例
- 使用 GPU 实例预留模式 + 闲置计费后
- 同样预留10个16GB显存的实例为业务提供推理请求,我们以40分钟闲置,20分钟活跃来进行计算,总GPU 部分资源成本约为2.45元/时/实例
以上面的例子进行成本的推演,我们可以看到闲置计费模式可以为节省60%的 GPU 资源成本。
开通函数计算获试用额度
函数计算为首次开通服务的用户提供免费试用额度,试用额度的有效期为3个月,自购买之日起,超出试用额度的部分均会计入按量付费。试用额度的详细信息如下。
- GPU试用额度:前100万GB*秒GPU资源使用免费。
- vCPU试用额度:前50万vCPU*秒vCPU资源使用免费。
- 内存试用额度:前200万GB*秒内存资源使用免费。
- 函数调用试用额度:前800万次函数调用免费。
除以上试用额度,2023年12月19日0时之后,函数计算还为首次开通服务的用户发放有效期3个月,每个月100 GB的CDT公网流量试用额度。
如何部署使用?
说明
【公测 - 申请使用】Serverless GPU 闲置计费当前为邀测功能,如需体验,请提交公测申请或联系客户经理申请。

您仅需登录至函数计算服务控制台,访问对应函数的弹性管理界面,并激活闲置计费功能。
相关链接汇总
- 魔搭 ModelScope 社区官网:https://modelscope.cn/home
- 函数计算产品官网:https://www.aliyun.com/product/fc
- 一键部署新手操作指南:https://developer.aliyun.com/article/1307460
- 通义千问模型系列:https://modelscope.cn/organization/qwen
- 智谱.AI系列:https://modelscope.cn/organization/ZhipuAI
- 百川模型:https://modelscope.cn/organization/baichuan-inc
- 函数计算闲置GPU实例公测申请:https://survey.aliyun.com/apps/zhiliao/dXfRVPEm-
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!