2023.12.25 关于 Redis 数据类型 Hash 常用命令、内部编码、应用场景
2023-12-26 21:38:18
目录
Hash 数据类型
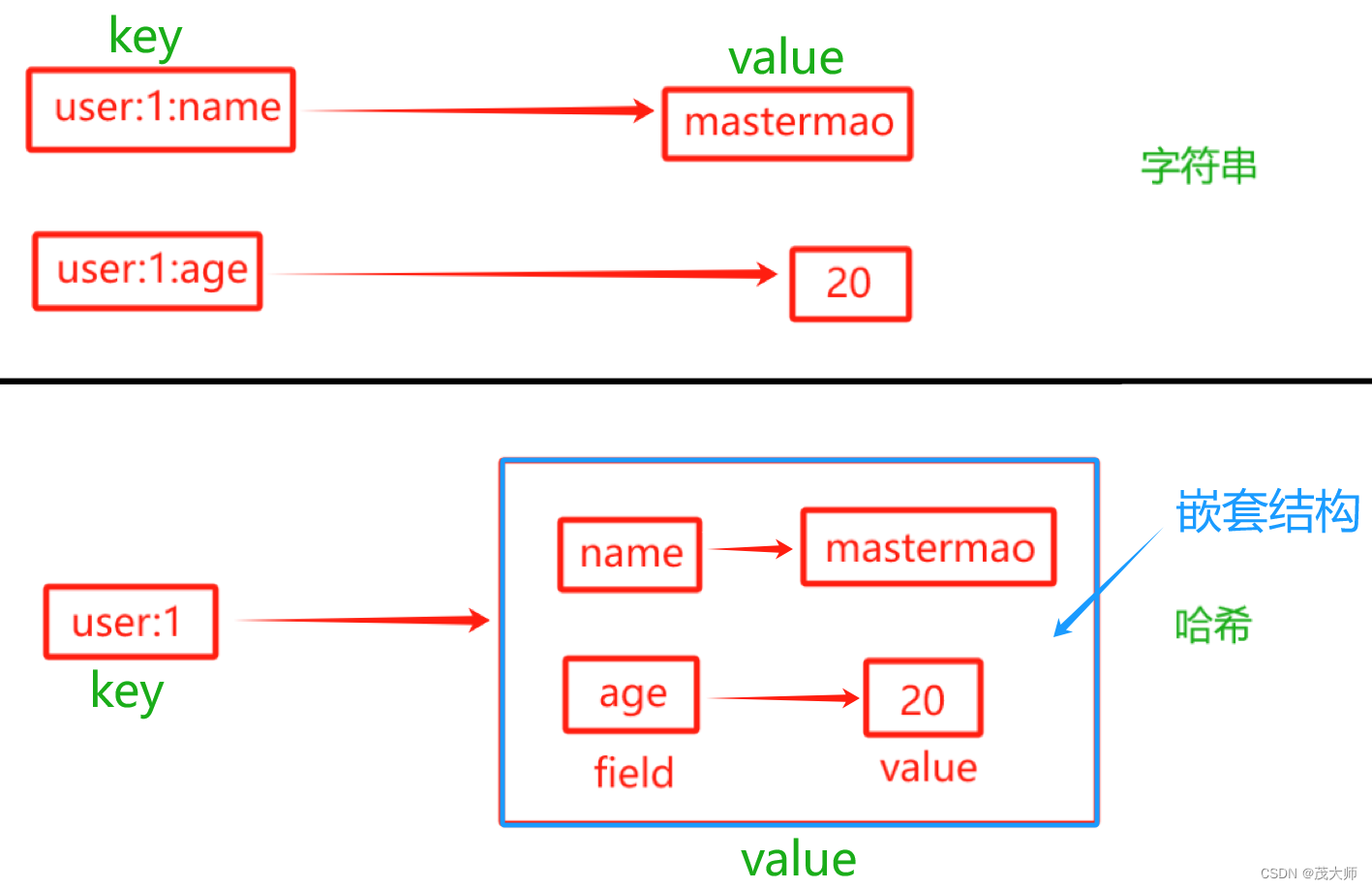
- 整体上来说 Redis 是键值对结构,其中 key 和 value 之间通过哈希方式组织的
- 该结构中 key 负责组织数据的结构,而 value 却可以为不同类型的数据,其中一种类型就是 哈希
- 这就相当于在 value 中又存储了一层键值对(field - value),相当于所谓的套娃
实例理解
- 存储一个 uid 为 1 的用户对象,姓名为 mastermao 年龄为 20
注意:
- 当我们谈到 key ,指的是整体?Redis 键值对(key - value)结构中的 key?
- 当我们谈到 field,指的是 Redis 中的键值对对应的值(value)中哈希表中的一个特定的键
- 该特定键用来进一步区分 和 访问哈希表中的各个数据项
Hash 操作命令
HSET
- 用来设置 hash 中指定的字段 field 和 value
- 此处的(field - value)中的?value 只能为字符串类型
语法:
hset key field value [field value ...]时间复杂度:
- O(1)
返回值:
- 返回值是设置成功的 键值对(field - value)的个数
?实例理解
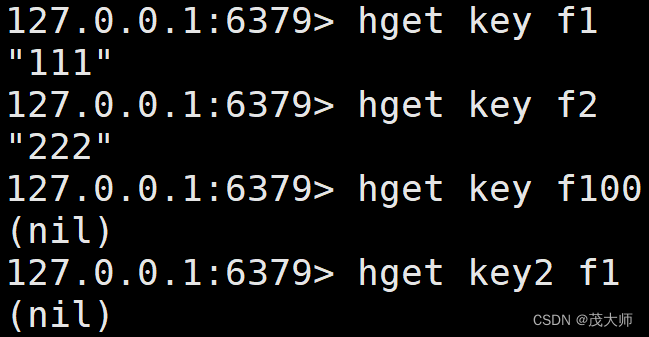
HGET
- 用来获取 hash 中指定字段 field 的 value 值
语法:
hget key field时间复杂度:
- O(1)
?实例理解
- 紧接着上述 hset 的实例进行测试
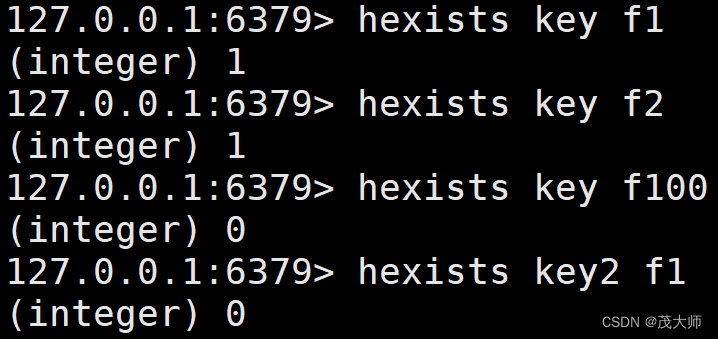
HEXISTS
- 用来检查 hash 中是否存在指定字段 field
语法:
hexists key field时间复杂度:
- O(1)
返回值:
- 返回 1 表示存在
- 返回 0 表示不存在
实例理解
- 紧接着上述 hset 的实例进行测试
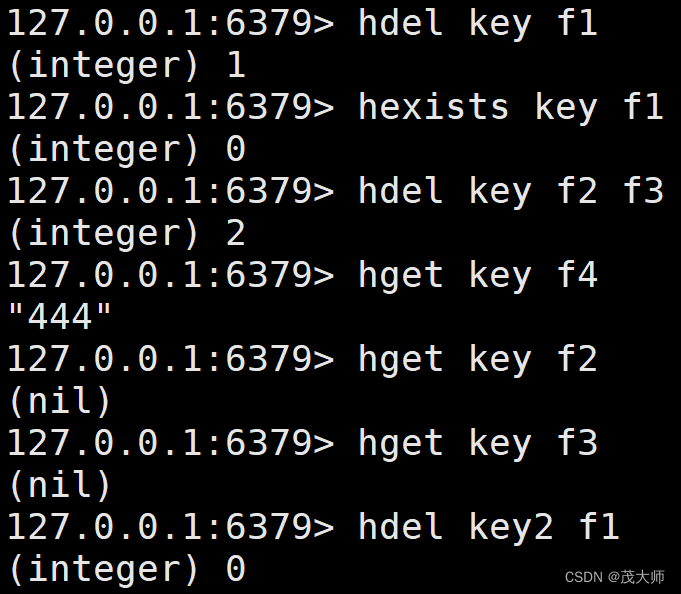
HDEL
- 用来删除 hash 中指定的字段 field
语法:
hdel key field [field ...]时间复杂度:
- O(N)
- 其中 N 代表删除的字段个数,一般不会很大,也可认为是 O(1)
返回值:
- 本次操作删除的字段个数
实例理解
- 紧接着上述 hset 的实例进行测试
注意:
- del 删除的是 key
- hdel 删除的是 field
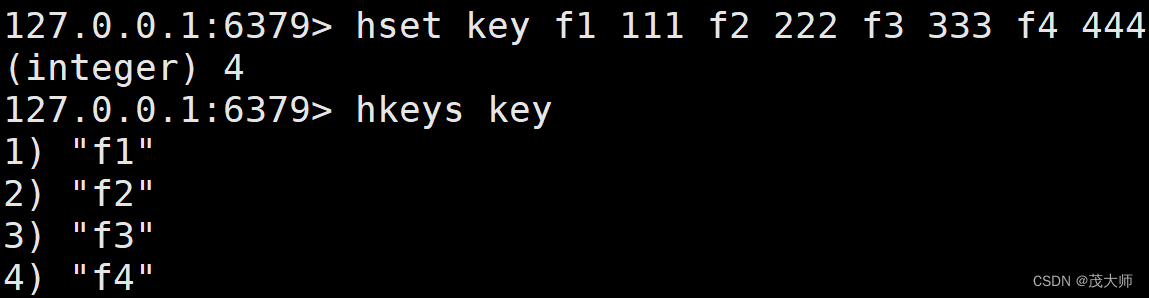
HKEYS
- 获取 hash 中的所有字段
- 该操作会现根据 key 找到对应的 hash,然后再遍历 hash
语法:
hkeys key时间复杂度:
- O(N)
- 其中 N 为 field 的个数
实例理解
- hkeys key 命令存在一定的风险,类似于?keys * 命令
- 主要因为我们并不知道某个 hash 中是否存在大量的 field,从而导致 Redis 被阻塞?
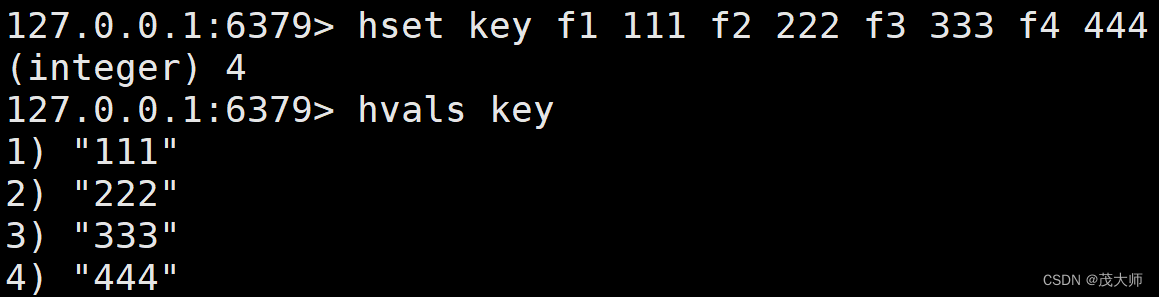
HVALS
- 和上面的 hkeys 相对应,用于获取?hash 中的所有 value?
?语法:
hvals key时间复杂度:
- O(N)
- 其中 N 为 field 的个数
?实例理解
注意:
- 使用 h 系列的命令操作 key 时,必须保证 key 对应的 value 得为?哈希 类型
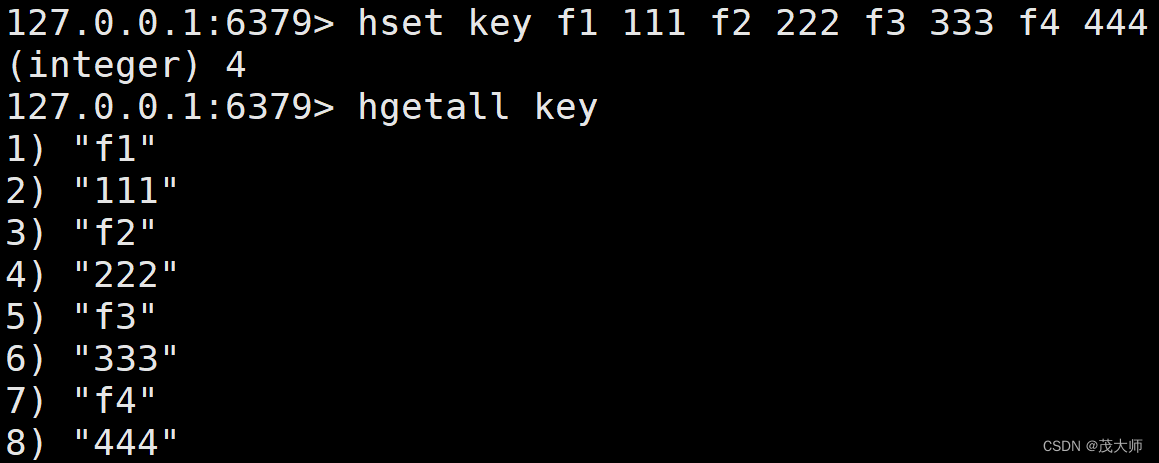
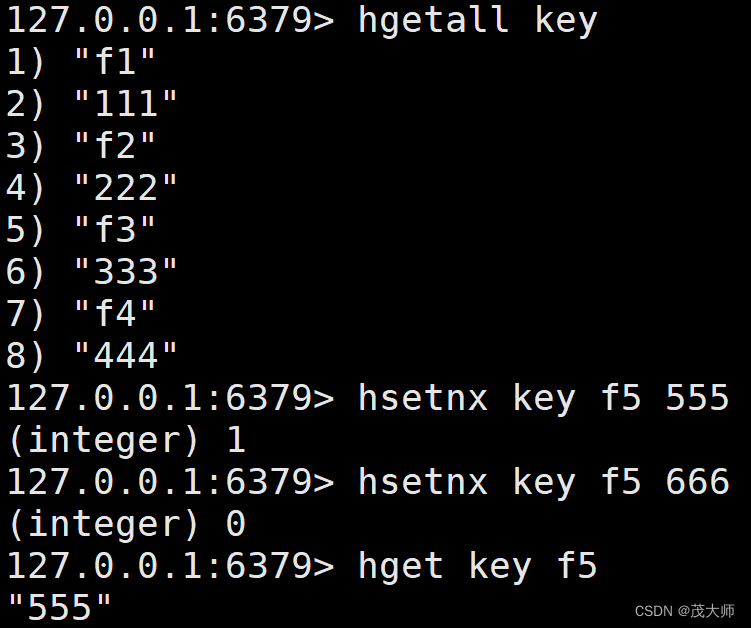
HGETALL
- 用于获取 hash 中的所有字段 field 以及对应的值 value
- 相当于 hkeys + hvals 命令的结合
语法:
hgetall key时间复杂度:
- O(N)
- 其中 N 为 field 的个数
?实例理解
- 观察此处的返回值
- 一个 field?一个 value 交替返回
注意:
- 上述操作风险比较大
- 因为多数情况下 不需要查询一个 key 中所有的 field 和 value 可能只查其中的几对
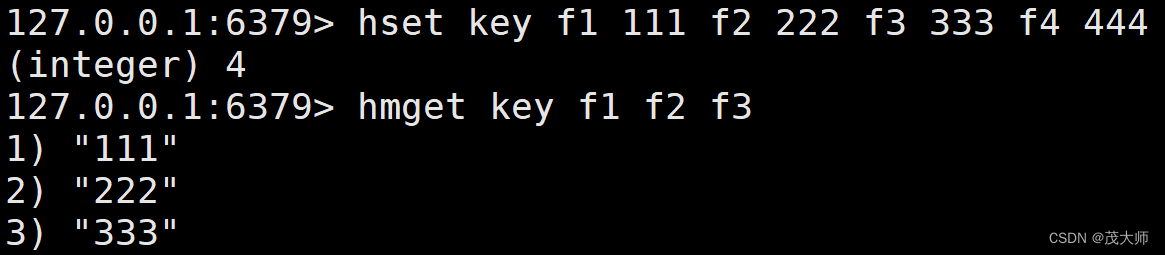
HMGET
- 用于获取 hash 中多个字段的值 value
- 类似于?mget 可以一次查询多个 key
?语法:
hmget key field [field ...]时间复杂度:
- O(N)
- 其中 N 代表查询的字段个数,一般不会很大,也可认为是 O(1)
实例理解
注意:
- 此处 hmget 命令返回的值 value,与查询时 输入字段 field 的顺序相匹配
问题:
- 有没有 hmset 一次可以设置多对(field -?value)呢?
回答:
- 有 hmset 命令
- 但是并不需要使用其命令,因为 hset 已经支持一次设置多对(field -?value)了
小总结:
- 上述的 hkeys、hvals、hgetall 命令均存在一定风险
- 如果 hash 的元素个数太多,则执行的耗时会比较长,从而阻塞掉 Redis?
补充:
- hscan 命令可以渐进式地遍历 Redis 的 hash
- 即敲一次命令,遍历一小部分,再敲一次命令,再遍历一小部分
- 此时的时间是可控的,连续执行多次便可完成整个的 hash?的遍历,也就是所谓的 "化整为零"
HLEN
- 用于获取 hash 中的所有键值对个数
语法:
???????
hlen key时间复杂度:
- O(1)
- 获取 hash 的元素个数不需要遍历
?实例理解
HSETNX
- 字段 field 不存在的情况下,设置 hash 中的字段 field 和 值 value
- 类似于 setnx????????
语法:
hsetnx key field value时间复杂度:
- O(1)
返回值:
- 返回 1 表示设置成功
- 返回 0 表示设置失败
实例理解
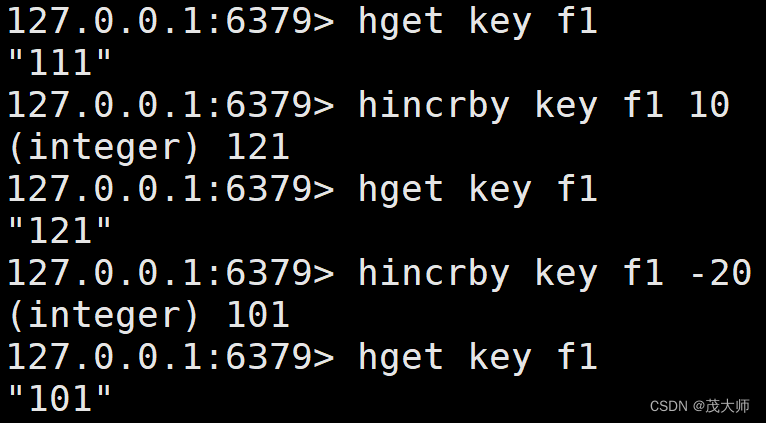
HINCRBY
- hash 这里的 value 也可以被当作数字来进行处理
- hincrby 命令用来对 value 进行加减整数
- 因为使用频率不是特别高,Redis 没有提供 hincr、hdecr 之类的命令
?语法:
hincrby key field increment时间复杂度:
- O(1)
返回值:
- value ± 之后的结果
实例理解
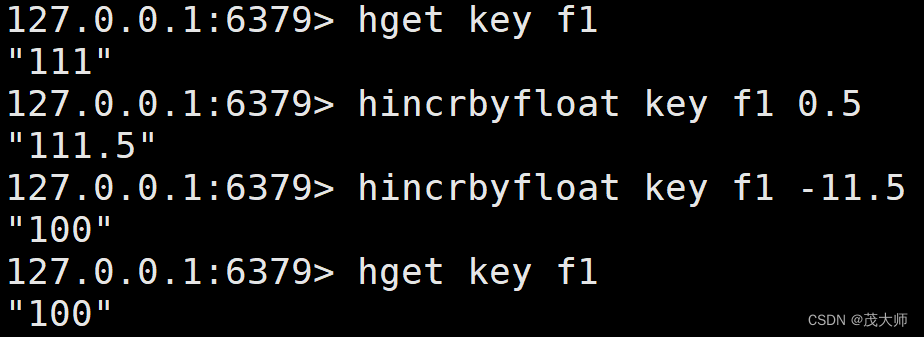
HINCRBYFLOAT
- hincybyfloat 命令用来对 value 进行加减小数
?语法:
hincrbyfloat key field increment时间复杂度:
- O(1)
返回值:
- value ± 之后的结果
实例理解
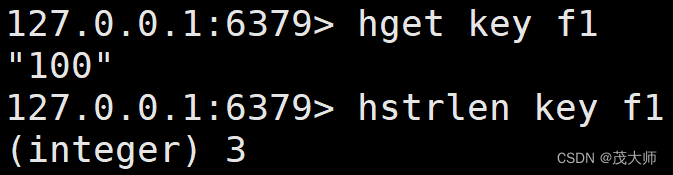
HSTRLEN
- 用于计算 hash 中的值 value 的字符串长度
?语法:
hstrlen key field?时间复杂度:
- O(1)
返回值:
- hash 中的值 value 的字符串长度,单位为字节
实例理解


Hash 编码方式
- 哈希的内部编码有 两种
- ziplist 压缩列表
- hashtable 哈希表
实例理解
- 我们通过 object encoding key 来查看编码方式
理解什么是压缩
- 压缩的本质,就是对数据进行重写编码
- 不同的数据有不同的特点
- 结合这些特点,进行精妙的设计,使其能够在重新编码之后,缩小体积
实例理解
- ' abbcccddddeeeee ' ———重新编码———> ' 1a2b3c4d5e '
- ' abcd0000000000000000000000000000000efgh ' ———重新编码———> 'abcd0[30]efgh??????? '
注意:
- 上述实例是比较粗糙的编码方式
- 实际上 一些常见的压缩算法都有着十分精妙的设计
ziplist 也是同理,其内部的数据结构也进行了?精心设计,其目的就是为了节省内存空间
ziplist 和 hashtable
- 如果上来就直接使用 hashtable,那该哈希表中可能有些位置上有元素,有些位置上没有元素,从而会造成一定程度上的空间浪费
- 所以当一开始元素个数比较少时,还是先使用 ziplist 进行编码,以达到节省空间的目的
- 而 ziplist 作为一种内部编码方式,虽然一定程度上 节省了内存空间,但读写元素时的速度较慢
- 这种慢 在元素较少时可能不太明显,但是当元素数量过多时,性能下降会更为明显
- 相比之下 hashtable 的内部结构更为灵活,它可以更高效地处理大量的元素
- 在 hashtable 中,每个元素都通过哈希函数映射到不同的位置,这样在读写元素时可以更快地定位到目标位置
结论:
- 哈希中的元素个数比较少,使用 ziplist 表示,元素个数比较多,使用 hashtable 来表示
- 每个 value 的值长度都比较短,使用 ziplist 表示,如果某个 value 的长度太长了,也会转换成 hashtable
- hash-max-ziplist-entries 配置 (默认 512 个)???????
- hash-max-ziplist-value 配置(默认 64 字节)
理解:
- 这两个配置项是均可以写到 redis.conf 文件中
- 且两个配置的阈值是可变的,所以不用刻意的去 记背数值
- 因此我们需在不同的业务场景中,通过测试等相关的手段,来调整上述配置的阈值,以便找到一个更加合适的数值
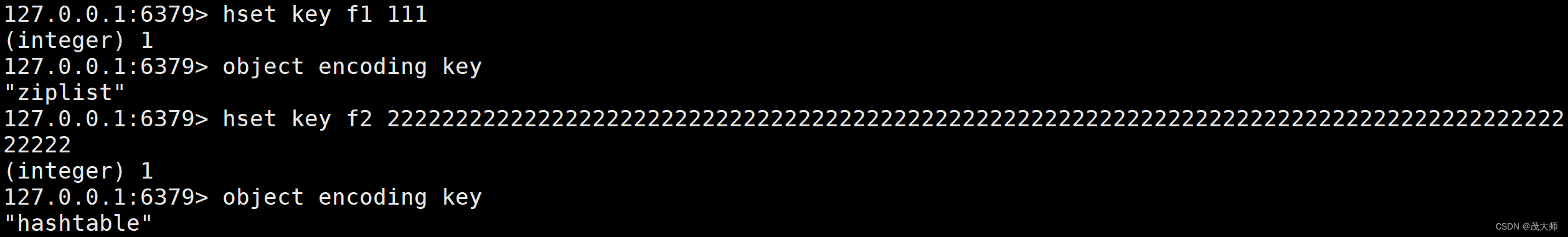
Hash 实际应用
Cache 缓存
- 首先 String 类型是可以用作缓存的
- 但对于 存储结构化的数据,即类似于数据库 表 这样的结构,使用 hash 类型更适合一些
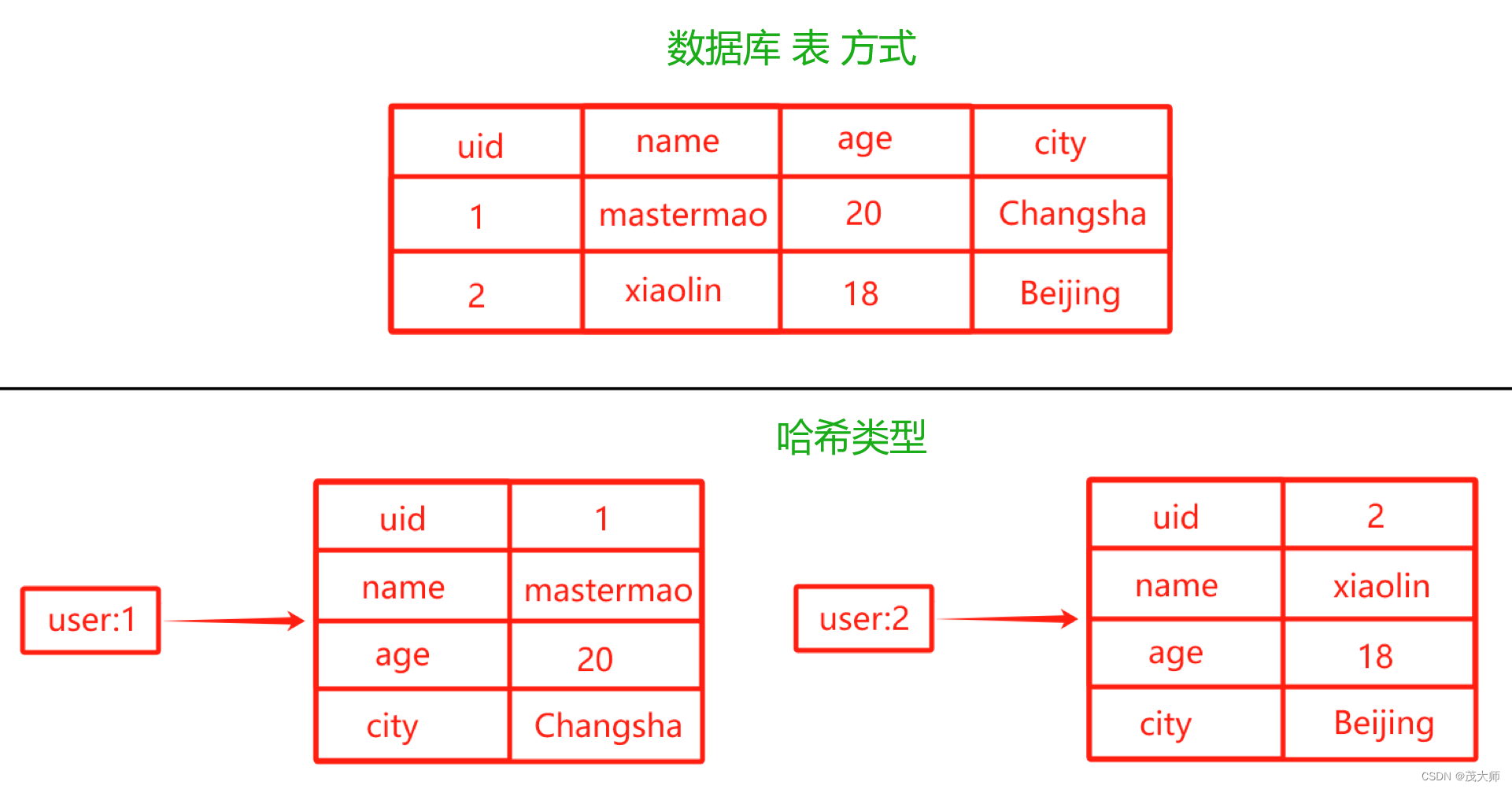
实例理解
- Redis 存储结构化的数据
方式一:
- 使用 hash 类型
注意:
- 此处的 key 中已经包含了 uid,那 hash 中?value?存储的 uid 是不是有点多此一举?
- 省去 hash 中?value 存储的 uid 是不是又可进一步节省存储空间?
- 首先如果确实不想在 hash 中?value 存储?uid 也可以省略掉
- 但是在工程实践中,通常会选择在哈希表的值 value 中再存储一份 uid
- 因为这样有助于简化代码逻辑,并使代码在后续开发中更为方便使用
方式二:
- 使用 string 类型?+ ?JSON 格式
set user:1 {"name": "mastermao", "age": 18, "city": "Changsha"}注意:
- 使用 string 类型?+? JSON?格式来表示 userinfo 时
- 只想获取或修改其中的某个字段,就需要将整个 JSON 字符串读取出来
- 再解析成对象,进行字段操作,然后再将其转换回 JSON 字符串,并写回 Redis?
- 这样一系列过程相对繁琐
- 相较之下使用 hash 的方式来表示 userinfo?
- 可以使用字段 field 来表示对象的每个属性,类似于数据库 表 中的每个列
- 这样可以更方便地修改或获取任何一个属性的值
- 虽然 hash 的方式在读写字段 field 上更为直观、高效,但付出的代价是更大的存储空间需求
- 此外需要控制 哈希表 在 ziplist 和 hashtable 两种内部编码的转换,可能会导致较大的内存消耗
- 相比之下,使用 string 类型?+? JSON?格式的的内存消耗相对较小
方式三:
- 原生 String 类型,一个属性对应一个键
- 该方式相当于将同一个对象的各个属性 给分散开表示(低内聚)
set user:1:name mastermao set user:1:age 18 set user:1:city Changsha
- ?????????????????????不建议使用该方式,该方式具有 低内聚性
理解高内聚低耦合
- 内聚就是将有关联的东西放到一起,最好能放到指定的地方,其优点为 好找
- 耦合就是两个模块 或 代码之间的关联关系,关联关系越大,越容易相互影响,则耦合也越大
- 我们追求低耦合,避免 "牵一发而动全身",这边出一个?bug 同时也影响到了其他的地方
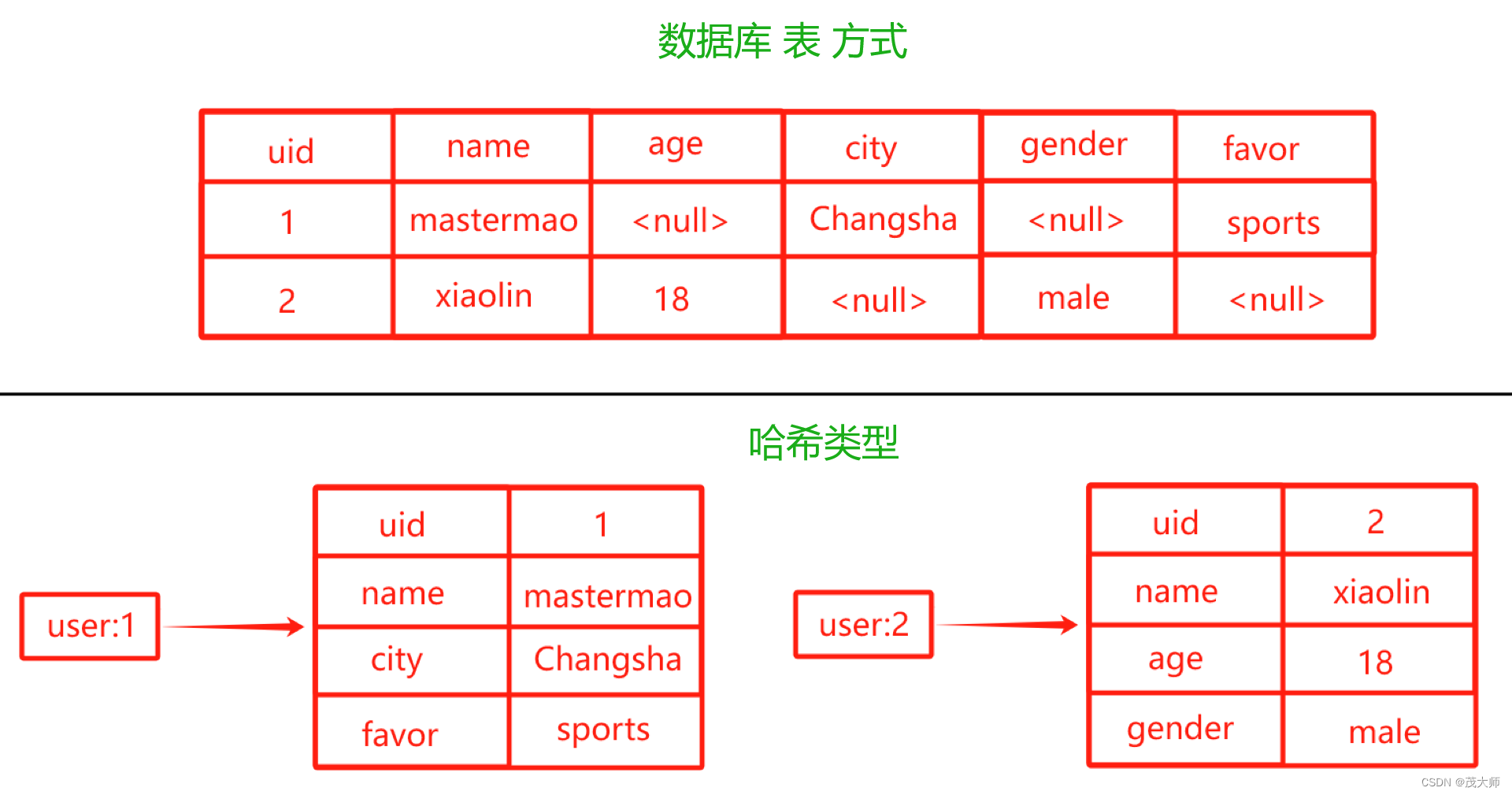
hash 类型 和 关系型数据库 的不同
- 哈希类型是稀疏的,而关系型数据库是完全结构化的
- ???????关系型数据库 可以做到复杂的查询,而 Redis 去模拟关系型复杂查询,例如联表查询、聚合查询等 基本不可能,维护成本高
实例理解
- 此处 哈希类型 每个键均有不同的字段?field
- 但关系型数据库 一旦添加新的列,其所有的行需为该列设置一个值,即便为 null???????
- 这就是为什么哈希类型是稀疏的,而关系型数据库是完全结构化的原因
文章来源:https://blog.csdn.net/weixin_63888301/article/details/135206690
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!