GO语言基础笔记(八):高级特性与性能优化
????????
目录
性能优化(Performance Optimization)
????????学习反射、并发模式和性能优化。 实践:优化已有代码,实践性能分析工具。
反射(Reflection)
- 反射是 Go 语言中一个强大且复杂的特性,它允许程序在运行时检查变量的类型和值,甚至修改它们。反射主要通过
reflect包来实现。 - 反射的使用场景包括:检查函数参数类型,实现泛型处理结构,或在不了解接口具体类型的情况下,动态调用其方法。
- 使用反射时需注意其对性能的影响,因为反射操作通常比直接的类型断言或类型检查要慢。
反射概念
反射是 Go 语言的一个高级特性,它允许程序在运行时动态地检查变量的类型(Type)和值(Value)。这在 Go 语言中通过 reflect 包实现。
反射的关键概念
- Type:反映了变量的类型。
- Value:反映了变量的值。
- Kind:表示基础类型,如
int、float、struct等。
反射的常见用途
- 检查函数参数的类型。
- 实现泛型处理结构。
- 在不知道接口具体类型的情况下,动态调用其方法。
代码示例
????????让我们通过一个简单的例子来理解反射的工作原理。假设我们有一个函数,它接收一个空接口类型的参数,并使用反射来检查该参数的类型和值。
package main
import (
"fmt"
"reflect"
)
func reflectTypeAndValue(x interface{}) {
t := reflect.TypeOf(x)
v := reflect.ValueOf(x)
fmt.Printf("Type: %v, Value: %v\n", t, v)
}
func main() {
var a int = 42
var b string = "GoLang"
reflectTypeAndValue(a)
reflectTypeAndValue(b)
}
1. 检查类型和值
????????反射可以用来动态地检查变量的类型和值。
package main
import (
"fmt"
"reflect"
)
func main() {
x := 3.4
fmt.Println("type:", reflect.TypeOf(x))
v := reflect.ValueOf(x)
fmt.Println("value:", v)
fmt.Println("type:", v.Type())
fmt.Println("kind:", v.Kind())
fmt.Println("value:", v.Float())
}
2. 修改变量值
????????使用反射,你可以修改变量的值,前提是这个值是可设置的(settable)
package main
import (
"fmt"
"reflect"
)
func main() {
x := 3.4
v := reflect.ValueOf(&x)
fmt.Println("settability of v:", v.CanSet())
v = v.Elem()
fmt.Println("The Elem of v is: ", v)
fmt.Println("settability of v:", v.CanSet())
v.SetFloat(7.1)
fmt.Println(v.Interface())
fmt.Println(x)
}
3. 调用函数
????????使用反射,你可以动态调用函数
package main
import (
"fmt"
"reflect"
)
func Add(a, b int) int {
return a + b
}
func main() {
funcValue := reflect.ValueOf(Add)
params := []reflect.Value{
reflect.ValueOf(10),
reflect.ValueOf(20),
}
results := funcValue.Call(params)
fmt.Println(results[0].Int()) // 输出结果: 30
}
4. 结构体反射
????????你可以通过反射来动态访问和修改结构体的字段。
package main
import (
"fmt"
"reflect"
)
type MyStruct struct {
Field1 int
Field2 string
}
func main() {
s := MyStruct{Field1: 10, Field2: "Hello"}
sValue := reflect.ValueOf(&s).Elem()
for i := 0; i < sValue.NumField(); i++ {
fmt.Println(sValue.Field(i))
}
// 修改字段的值
if sValue.Field(0).CanSet() {
sValue.Field(0).SetInt(20)
}
if sValue.Field(1).CanSet() {
sValue.Field(1).SetString("World")
}
fmt.Println("After modification:", s)
}
????????在这些示例中,我们演示了如何使用反射来检查类型和值、修改变量值、动态调用函数和处理结构体字段。反射是一个非常强大的工具,但它也可能使代码变得复杂且难以理解。因此,它应该在确有必要的情况下谨慎使用。
并发模式(Concurrency Patterns)
- Go 语言的并发是其核心特性之一。通过 Goroutines 和 Channels,Go 可以有效地实现并发编程。
- 掌握不同的并发模式,如 Worker Pool 模式、Pipeline 模式和 Fan-in/Fan-out 模式,对于构建高效且可靠的并发程序至关重要。
- 正确使用并发可以显著提高程序性能,但同时也要注意避免常见的并发问题,如死锁、竞态条件和资源竞争
1. Worker Pool 模式
????????在 Worker Pool 模式中,一组固定数量的工作协程(workers)被创建来处理任务队列中的任务。
package main
import (
"fmt"
"sync"
"time"
)
// worker 函数代表一个工作协程,它从 jobs 通道接收任务,并将处理结果发送到 results 通道。
func worker(id int, jobs <-chan int, results chan<- int) {
for j := range jobs {
fmt.Println("worker", id, "started job", j)
time.Sleep(time.Second) // 模拟耗时操作
fmt.Println("worker", id, "finished job", j)
results <- j * 2 // 发送处理结果到 results 通道
}
}
func main() {
const numJobs = 5
jobs := make(chan int, numJobs)
results := make(chan int, numJobs)
// 创建 3 个工作协程
for w := 1; w <= 3; w++ {
go worker(w, jobs, results)
}
// 分发任务到 jobs 通道
for j := 1; j <= numJobs; j++ {
jobs <- j
}
close(jobs) // 关闭 jobs 通道,表示不再有新的任务
// 收集所有工作协程的处理结果
for a := 1; a <= numJobs; a++ {
<-results
}
}
工作原理
- 任务分配:在 Worker Pool 模式中,创建一定数量的工作协程(workers)。这些协程通常从一个共享的任务队列中获取任务。任务队列是一个 Channel,用于存储待处理的工作。
- 任务处理:每个工作协程从任务队列(jobs Channel)中获取任务,并开始处理。处理完成后,可能会将结果发送到另一个结果队列(results Channel)。
- 同步机制:主协程通常等待所有工作协程完成任务。这可以通过关闭任务队列的 Channel 并使用
sync.WaitGroup或接收所有结果来实现。
在代码中的体现
jobsChannel 用于传递任务给工作协程。resultsChannel 用于收集工作结果。- 每个
worker函数在循环中从jobsChannel 接收任务,处理完成后将结果发送到resultsChannel。 - 主函数中,所有任务被发送到
jobsChannel,然后该 Channel 被关闭,表示没有更多的任务。 - 主函数等待从
resultsChannel 接收所有结果,确保所有任务都被处理。
2. Pipeline 模式
????????Pipeline 模式涉及将一系列处理步骤连接在一起,每个步骤由一个 Goroutine 处理,并通过 Channels 进行通信。
package main
import (
"fmt"
)
// gen 函数将一个整数列表转换为一个通道,用于发送这些整数。
func gen(nums ...int) <-chan int {
out := make(chan int)
go func() {
for _, n := range nums {
out <- n
}
close(out) // 发送完毕后关闭通道
}()
return out
}
// sq 函数对从输入通道接收到的每个整数求平方,并将结果发送到输出通道。
func sq(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n * n
}
close(out) // 处理完毕后关闭通道
}()
return out
}
func main() {
// 设置 pipeline:gen -> sq -> sq
// 第一个 sq 处理 gen 的输出,第二个 sq 处理第一个 sq 的输出
for n := range sq(sq(gen(2, 3))) {
fmt.Println(n) // 输出结果
}
}
工作原理
- 阶段性处理:Pipeline 模式将数据处理过程分为多个阶段,每个阶段由一个协程处理,并通过 Channel 连接。
- 连续传递:每个阶段的协程从输入 Channel 读取数据,进行处理,然后将结果写入输出 Channel。下一个阶段的协程将从这个输出 Channel 读取数据,如此循环。
- 数据流动:这种模式允许数据在多个处理步骤中连续流动,类似于工业生产中的流水线。
在代码中的体现
gen函数初始化数据流,将整数发送到输出 Channel。sq函数接收整数,计算其平方,然后将结果发送到另一个 Channel。- 主函数中,通过连续调用
sq函数形成 pipeline。每个sq函数都是 pipeline 的一个阶段。
3. Fan-in/Fan-out 模式
????????在 Fan-out 模式中,多个 Goroutines 从同一个 Channel 读取数据,分担工作负载。在 Fan-in 模式中,多个 Goroutines 写入同一个 Channel,汇集它们的结果。
package main
import (
"fmt"
"sync"
)
// produce 函数生产一系列整数,发送到通道 ch。
func produce(ch chan<- int, id int) {
for i := 0; i < 5; i++ {
ch <- i
fmt.Printf("Producer %d produced %d\n", id, i)
}
close(ch) // 生产完毕后关闭通道
}
// consume 函数从通道 ch 消费整数。
func consume(ch <-chan int, id int) {
for n := range ch {
fmt.Printf("Consumer %d consumed %d\n", id, n)
}
}
func main() {
ch := make(chan int)
// 启动单个生产者协程
go produce(ch, 1)
var wg sync.WaitGroup
const numConsumers = 3
wg.Add(numConsumers) // 设置 WaitGroup 的计数
// 启动多个消费者协程(Fan-out)
for i := 0; i < numConsumers; i++ {
go func(id int) {
defer wg.Done() // 协程完成时减少 WaitGroup 计数
consume(ch, id)
}(i + 1)
}
wg.Wait() // 等待所有消费者协程完成
}
工作原理
- Fan-out:多个协程从同一个输入 Channel 读取数据,分担工作负载。这种方式提高了数据处理的并行度。
- Fan-in:多个协程将结果写入同一个输出 Channel,将多个数据源的数据汇聚在一起。
在代码中的体现
- 在
produce函数中,生产者协程生成数据并发送到 Channel。 - 多个
consume函数(消费者协程)从同一个 Channel 接收数据并处理(Fan-out)。 - 使用
sync.WaitGroup确保所有消费者协程完成工作。
????????这些并发模式在 Go 语言中非常有用,它们可以帮助您构建高效且可靠的并发程序。每种模式都有其特定的使用场景和优势,选择合适的模式取决于您的具体需求和应用场景。
性能优化(Performance Optimization)
- 性能优化是提升 Go 程序效率的关键步骤。首先,应当通过合理的设计和算法选择来确保程序基础的高效性。
- 使用性能分析工具,如
pprof,可以帮助您找出程序中的性能瓶颈。pprof支持 CPU 分析、内存分析等,让您可以深入了解程序的运行细节。 - 除了标准的性能优化工具外,还应注意代码层面的优化,例如减少不必要的内存分配、优化循环和数据结构选择等。
1. 合理的设计和算法选择
????????优化的第一步是选择合适的算法和数据结构。高效的算法和数据结构可以减少不必要的计算和内存使用。
package main
import "fmt"
// 使用快速排序而非冒泡排序来提高排序效率
func quickSort(a []int) []int {
if len(a) < 2 {
return a
}
left, right := 0, len(a)-1
pivot := a[(left+right)/2]
a[(left+right)/2], a[right] = a[right], a[(left+right)/2]
for i := range a {
if a[i] < pivot {
a[left], a[i] = a[i], a[left]
left++
}
}
a[left], a[right] = a[right], a[left]
quickSort(a[:left])
quickSort(a[left+1:])
return a
}
func main() {
a := []int{3, 6, 8, 10, 1, 2, 1}
fmt.Println(quickSort(a))
}
2. 使用性能分析工具
??pprof 是 Go 语言中一个强大的性能分析工具,用于识别程序中的性能瓶颈。
package main
import (
"log"
"net/http"
"_net/http/pprof" // 添加 pprof
)
func main() {
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
// 此处为程序的主逻辑
}
?
实践:优化已有代码
- 选取一个实际的 Go 项目,运用以上知识对其进行优化。
- 首先运行性能分析,确定优化目标。然后,根据分析结果调整代码,可能涉及到重构数据结构、改进算法逻辑或调整并发模式。
- 优化后,再次进行性能测试,比较优化前后的差异,以确保所做更改有效果
????????假设我们有一个 Go 编写的简单 Web 服务,它处理一些计算密集型任务和数据处理任务。?
????????
package main
import (
"fmt"
"net/http"
"time"
)
func handler(w http.ResponseWriter, r *http.Request) {
start := time.Now()
result := heavyComputation() // 假设这是一个计算密集型操作
duration := time.Since(start)
fmt.Fprintf(w, "Result: %v, took: %v", result, duration)
}
func heavyComputation() int {
time.Sleep(100 * time.Millisecond) // 模拟重计算
return 42
}
func main() {
http.HandleFunc("/", handler)
http.ListenAndServe(":8080", nil)
}
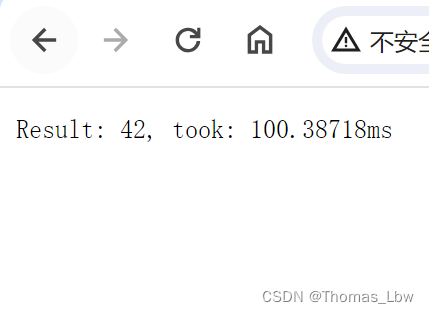
?
第一步:性能分析
- 使用
pprof对服务进行性能分析。 - 添加
pprof相关代码到项目中,并在运行时收集性能数据。
第二步:优化目标和策略
假设我们发现 heavyComputation 函数是性能瓶颈。 优化策略可能包括:
- 改进算法:如果可能,寻找更高效的算法来替代现有逻辑。
- 并发执行:如果该函数可以并行处理,考虑使用 Goroutines 来分配任务。
- 缓存结果:如果函数输出对于相同的输入是不变的,考虑使用缓存来避免重复计算。
优化后的代码
假设我们决定实现一个简单的缓存机制。
package main
import (
"fmt"
"net/http"
"sync"
"time"
)
var (
cache = make(map[int]int)
cacheMu sync.Mutex
)
func handler(w http.ResponseWriter, r *http.Request) {
start := time.Now()
result := cachedComputation(42) // 使用缓存
duration := time.Since(start)
fmt.Fprintf(w, "Result: %v, took: %v", result, duration)
}
func cachedComputation(input int) int {
cacheMu.Lock()
if val, ok := cache[input]; ok {
cacheMu.Unlock()
return val
}
cacheMu.Unlock()
val := heavyComputation() // 原始计算
cacheMu.Lock()
cache[input] = val
cacheMu.Unlock()
return val
}
func heavyComputation() int {
time.Sleep(100 * time.Millisecond) // 模拟重计算
return 42
}
func main() {
http.HandleFunc("/", handler)
http.ListenAndServe(":8080", nil)
}
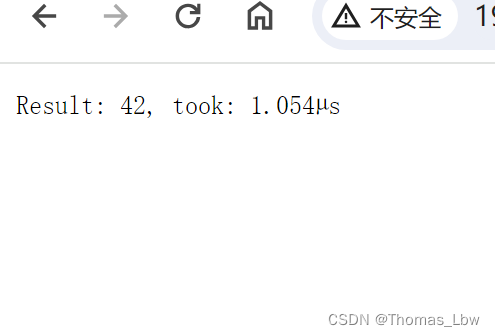
?
第三步:性能测试
- 再次运行
pprof性能分析,比较优化前后的性能。 - 检查响应时间是否有所改善,以及 CPU 和内存使用情况是否有所优化。
????????这个例子展示了基本的优化流程,但实际项目中的优化可能更复杂。它可能涉及到深入的算法分析,复杂的并发模式调整,或底层数据结构的重构。始终记住,优化应该基于性能分析的数据,而非随意猜测。同时,优化时应考虑代码的可读性和维护性。?
pprof
??pprof 是 Go 语言提供的性能分析工具,它能够帮助开发者分析程序的 CPU 使用情况和内存分配。以下是如何在 Go 程序中使用 pprof 的示例:
使用
步骤 1: 导入 pprof 包
????????首先,在你的 Go 程序中导入 net/http/pprof 包。这将自动注册 HTTP 服务器的多个 pprof 路由。
import (
"net/http"
_ "net/http/pprof" // 注意这里使用了空白导入语法
)
步骤 2: 启动 HTTP 服务器
????????启动一个 HTTP 服务器以便可以通过 HTTP 请求访问 pprof 数据。通常,这可以作为程序的一部分在一个新的 goroutine 中进行。
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()步骤 3: 收集性能数据
一旦你的程序开始运行,你可以通过访问特定的 URL 来收集性能数据。例如:
- 访问
http://localhost:6060/debug/pprof/可查看所有可用的 pprof 信息。 - 访问
http://localhost:6060/debug/pprof/heap可获取内存分配的情况。 - 访问
http://localhost:6060/debug/pprof/profile?seconds=30可进行 30 秒的 CPU 分析。
步骤 4: 使用 go tool pprof 分析数据
????????你可以使用 go tool pprof 命令来下载和分析这些数据。例如,要分析 CPU 使用情况,可以使用以下命令:
go tool pprof http://localhost:6060/debug/pprof/profile?seconds=30????????在 pprof 的交互模式下,你可以使用各种命令来查看和分析性能数据,如 top 查看消耗最多 CPU 的函数,或 web 生成函数调用图。
top: 这个命令显示消耗最多 CPU 时间的函数。它提供了一个函数列表,按照其在 CPU 使用上的占比排序。
示例:
scssCopy code
(pprof) topweb: 这个命令生成一个 SVG 格式的函数调用图,并在默认的网页浏览器中打开它。这个图表展示了函数之间的调用关系以及它们的 CPU 使用情况。
示例:
scssCopy code
(pprof) weblist: 这个命令用于显示指定函数的源代码,并标注每一行的 CPU 使用情况。这对于深入理解特定函数的性能特性非常有用。
示例:
scssCopy code
(pprof) list [函数名]tree: 这个命令以树状格式显示调用图,帮助你理解函数调用的层次结构。
示例:
scssCopy code
(pprof) treepeek: 这个命令用于查看与特定项相关的所有路径,帮助你理解特定函数或路径是如何贡献到总体资源使用的。
示例:
scssCopy code
(pprof) peek [函数名或路径]text: 以纯文本格式显示 top 命令类似的输出,但可以更容易地用于报告或进一步分析。
示例:
scssCopy code
(pprof) textexit 或 quit: 退出 pprof 的交互模式。
示例:
bashCopy code
(pprof) exit
例子
? ? ? ? 访问:
/debug/pprof/
Types of profiles available:
Count Profile
8 allocs
0 block
0 cmdline
6 goroutine
8 heap
0 mutex
0 profile
7 threadcreate
0 trace
full goroutine stack dump
Profile Descriptions:
allocs: A sampling of all past memory allocations
block: Stack traces that led to blocking on synchronization primitives
cmdline: The command line invocation of the current program
goroutine: Stack traces of all current goroutines
heap: A sampling of memory allocations of live objects. You can specify the gc GET parameter to run GC before taking the heap sample.
mutex: Stack traces of holders of contended mutexes
profile: CPU profile. You can specify the duration in the seconds GET parameter. After you get the profile file, use the go tool pprof command to investigate the profile.
threadcreate: Stack traces that led to the creation of new OS threads
trace: A trace of execution of the current program. You can specify the duration in the seconds GET parameter. After you get the trace file, use the go tool trace command to investigate the trace.????????Go 语言的 pprof 分析工具中,/debug/pprof/ 路径提供了访问多种性能分析数据的接口。每种类型的性能数据都提供了对程序运行的不同视角。下面是您列出的每种分析数据类型的解释:
-
allocs: 这个配置文件提供了所有过去内存分配的采样。它有助于理解内存分配的模式和频率。
-
block: 这个配置文件显示了导致同步原语上阻塞的堆栈跟踪,例如在通道操作或互斥锁等待上的阻塞。它对于理解并发性能问题非常有用。
-
cmdline: 这个配置文件显示了当前程序的命令行调用方式,即启动程序时使用的命令和参数。
-
goroutine: 提供了当前所有 goroutine 的堆栈跟踪。这对于理解程序的并发行为和寻找死锁等问题非常有价值。
-
heap: 提供了活跃对象的内存分配的采样。通过设置
gcGET 参数,可以在采样之前触发垃圾回收。这有助于分析内存使用情况和潜在的内存泄露。 -
mutex: 显示持有争用互斥锁的堆栈跟踪。它有助于识别可能导致性能问题的锁争用。
-
profile: 提供 CPU 的使用情况。您可以通过设置
secondsGET 参数来指定分析持续的时间。分析完成后,可以使用go tool pprof命令来分析 CPU 配置文件。 -
threadcreate: 显示导致创建新操作系统线程的堆栈跟踪。这可以帮助您了解线程创建的模式和原因。
-
trace: 提供了当前程序的执行追踪。可以通过设置
secondsGET 参数来指定追踪的持续时间。追踪完成后,可以使用go tool trace命令来分析追踪文件。
每个配置文件提供了程序性能和行为的不同视角,帮助开发者更全面地理解和优化其 Go 程序。通过使用这些工具,您可以诊断各种性能问题,比如内存泄露、CPU 瓶颈、锁争用等。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!