扫盲运动—字节序
1 大端、小端字节序
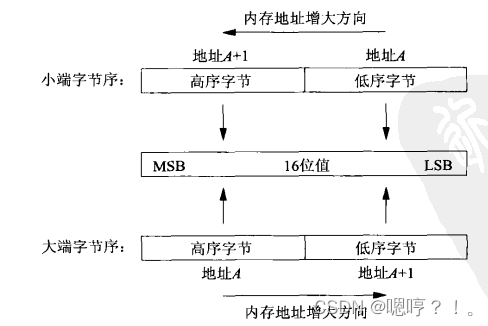
术语“大端”和“小端”表示多个字节值的哪一端(小端或大端)存储在该值的起始地址。
- 大端:将高序字节存储在起始地址,这称为大端(big-endian)字节序
- 小端:将低序字节存储在起始地址,这称为小端(little-endian)字节序
为什么要有大端、小端字节序,多麻烦!统一使用大端字节序,不是更方便吗?
计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。但是,人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
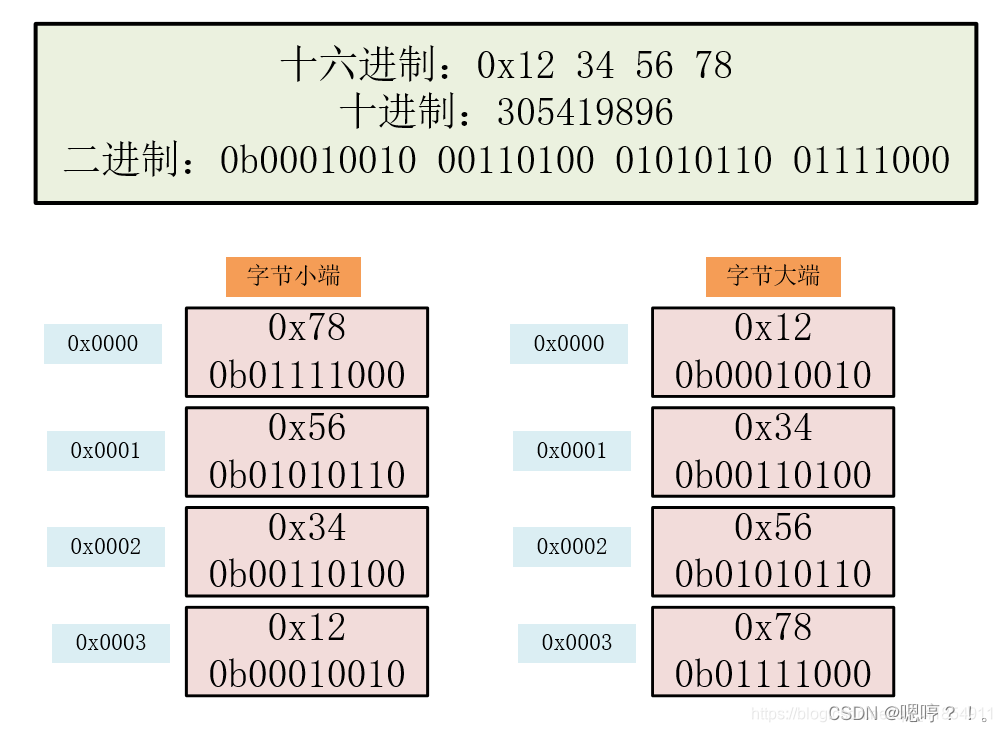
来个实例,要不然实在记不住。
操作系统的字节序一般是和处理器架构有关系的,具体来说:
- 小端序: x86、MOS Technology 6502、Z80、VAX、PDP-11等处理器;
- 大端序: Motorola 6800、Motorola 68000、PowerPC 970、System/370、SPARC(除V9外)等处理器;
- 另外 ARM、PowerPC(除PowerPC 970外)、DEC Alpha、SPARC V9、MIPS、PA-RISC及IA64的字节序是可配置的。
2 网络字节序、主机字节序
-
主机字节序:不同的机器主机字节序不相同,与CPU设计有关,数据的顺序是由cpu决定的,而与操作系统无关。我们把某个给定系统所用的字节序称为主机字节序(host byte order)。比如x86系列CPU都是little-endian的字节序。
正是由于这个原因不同体系结构的机器之间无法通信,所以要转换成一种约定的数序,也就是网络字节顺序。 -
网络字节序:网络字节序是TCP/IP中规定好的一种数据表示格式,它与具体的CPU类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释。网络字节序采用大端(big endian)排序方式。
3 网络字节序与主机字节序之间转换
3.1 C/C++
头文件<netinet/in.h>
转换函数:htons(), ntohs(), htons(),htonl()
htons和ntohs完成16位无符号数的相互转换,
htonl和ntohl完成32位无符号数的相互转换。
在使用little endian的系统中,这些函数会把字节序进行转换;
在使用big endian类型的系统中,这些函数会定义成空宏;
3.2 Java
首先声明,Java虚拟机(JVM)的规范并没有明确要求使用大端序或小端序来表示多字节数据类型。
然而,Java的DataInput和DataOutput接口确实规定了使用大端序(网络字节序)。具体原因我认为有如下几点:
-
一致性和跨平台兼容性
Java的设计原则之一是“一次编写,到处运行”。为了确保这一点,Java选择了一个确定的字节序,即大端序,使得Java程序的数据读取和写入在所有平台上都具有一致性。 -
网络字节序
在网络传输中,大端序通常被认为是网络字节序。因为Java最初是为网络应用设计的(想想Java的口号:“The network is the computer.”),所以选择网络字节序作为默认的字节序是合理的。 -
与大多数网络协议的兼容性
许多早期的网络协议(例如IP、TCP、UDP)都使用大端序。由于Java希望与这些协议兼容,因此采用大端序作为默认设置也是有道理的。 -
直观性
对于人类来说,大端序的表示方式更为直观。例如,数字 0x12345678 在大端序中的表示方式是 12 34 56 78,这与我们的阅读习惯相符。 作者:程序员_可乐 https://www.bilibili.com/read/cv25882429/ 出处:bilibili
Java设置大小端
public class HelloEndian {
public static void main(String[] args) {
ByteBuffer b = ByteBuffer.wrap(new byte[4]);
b.order(ByteOrder.BIG_ENDIAN);
b.putInt(0x01020304);
System.out.println("Big-Endian: " + Arrays.toString(b.array()));
b = ByteBuffer.wrap(new byte[4]);
b.order(ByteOrder.LITTLE_ENDIAN);
b.putInt(0x01020304);
System.out.println("Little-Endian: " + Arrays.toString(b.array()));
}
}
在用C/C++写通信程序时,在发送数据前务必用htonl和htons去把整型和短整型的数据进行从主机字节序到网络字节序的转换,而接收数据后对于整型和短整型数据则必须调用ntohl和ntohs实现从网络字节序到主机字节序的转换。
如果通信的一方是JAVA程序、一方是C/C++程序时,则需要在C/C++一侧使用以上几个方法进行字节序的转换,而JAVA一侧,则不需要做任何处理,因为JAVA字节序与网络字节序都是BIG-ENDIAN,只要C/C++一侧能正确进行转换即可(发送前从主机序到网络序,接收时反变换)。如果通信的双方都是JAVA,则根本不用考虑字节序的问题了。
转载链接
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!