【扩散模型】7、GLIDE | 文本指引的图像生成和编辑

论文:GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
代码:https://link.zhihu.com/?target=https%3A//github.com/openai/glide-text2im
出处:OpenAI
一、背景
在扩散模型经过了一系列发展之后,Openai 开始探索文本条件下的图像生成,并在这篇论文里对比了两种不同的 guidance 策略,分别是通过 CLIP 引导和 classifier-free 的引导。验证了 classifier-free 的方式生成的图片更真实,与提示的文本有更好的相关性。并且使用 classifier-free 的引导的 GLIDE 模型在 35 亿参数的情况下优于 120 亿参数的 DALL-E 模型

二、方法
作者训练的模型包括:
- 一个 35 亿参数量的 text-conditional 扩散模型,分辨率为 64*64
- 一个 15 亿参数量的 text-conditional 上采样扩散模型,将分辨率提升至 256x256
- 对于 CLIP guidance 模型,还额外训练了一个 64x64 noised ViT-L CLIP
2.1 Text-Conditional Diffusion Models
假设有一个加噪的图片 x t x_t xt?,以及一个对应的文本描述 c c c,这个模型预测的就是 p ( x t ? 1 ∣ x t , c ) p(x_{t-1}|x_t, c) p(xt?1?∣xt?,c)
为了让这个文本 condition 生效,首先要将文本编码成 K 个 tokens,然后输入 Transformer 模型,输出文本编码结果
训练过程和 DALLE 类似:
- 一个 35 亿参数量的 text-conditional 扩散模型,分辨率为 64*64
- 一个 15 亿参数量的 text-conditional 上采样扩散模型,将分辨率提升至 256x256
2.2 Fine-tuning for classifier-free guidance
初始训练完成后,还需要 finetune base model 来支持 unconditional 图像生成
和 text-conditional 的模型最大的不同是,20% 的 text token 被使用 empty sequence 代替了,这样一来,模型就能同时生成 text-conditional 的输出和无需 text 的输出
2.3 Image Inpainting
扩散模型进行图像修复的基本步骤如下:
-
初始化:首先,你需要一个扩散模型,这个模型是通过在大量图像数据上进行训练得到的。然后,你需要一个待修复的图片。
-
设置已知区域和未知区域:在图片中选择一部分作为已知区域(不需要修复的部分),剩余部分作为未知区域(需要修复的部分)。通常情况下,已知区域是完整无损害的图片内容,而未知区域可能是被遮挡或损坏了的图片内容。
-
采样和替换:接着,在每次采样步骤后, 用 q(xt|x0)(即从扩散过程中某一时刻t得到的概率密度函数)对应于原始图像 x0 的样本替换图像中已经被确定(或者说"固定")了值得那些位置。这个过程会持续多次迭代以逐渐生成最终结果。
-
微调模型:为了获得更好效果, 需要对该模型进行微调以优化其在此类任务上表现。这包括随机擦除训练示例中某些区域,并将剩余部分与额外条件信息一起输入到模型中。同时还会修改网络结构增加新频道,并将新频道对应输入权重初始化为零
-
提供低解析度和高解析度信息: 对于上采样(upsampling) 模型来说, 总是提供完整低解析度(low-resolution) 图像, 但只提供高解析度(high-resolution) 图片中未被掩盖(masked out) 的那些地方
-
生成结果: 经过以上步骤后, 模型就能够根据给定(也就是“固定”)了值得那些位置去推测出其他位置可能出现什么内容并进行填充(restore),从而实现图像修复(inpainting)
之前的很多工作将未经针对 inpainting 任务微调的扩散模型直接用于图像修复,实际上使用扩散模型进行图像修复时,采样流程不变,但需要将图像中的已知区域在每个 sample step 之后使用生成的 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt?∣x0?) 替换,这样做有一个问题,就是模型在采样的过程中无法看到全局的上下文(只能看到它的噪声版本),偶尔会在我们早期的实验中产生不希望出现的边缘伪影。
所以本文做了一些工作,本文的图像修复过程如下:
-
训练:首先,使用大量图像数据训练一个扩散模型。这个模型可以学习如何从一个随机噪声开始,逐渐生成出一张真实的图片。
-
微调:为了进行图像修复,需要对该模型进行微调以优化其在此类任务上表现。这包括随机擦除训练示例中某些区域,并将剩余部分与额外条件信息一起输入到模型中。同时还会修改网络结构增加新频道,并将新频道对应输入权重初始化为零。
-
设置已知区域和未知区域:在待修复的图片中选择一部分作为已知区域(不需要修复的部分),剩余部分作为未知区域(需要修复的部分)。通常情况下,已知区域是完整无损害的图片内容,而未知区域可能是被遮挡或损坏了的图片内容。
-
提供低分辨率和高分辨率信息: 对于上采样(upsampling) 模型来说, GLIDE 总是提供完整 (low-resolution) 图像, 但只提供 (high-resolution) 图片中未被掩盖(masked out) 的那些地方.
-
生成结果: 在每次采样步骤后, GLIDE用 q(xt|x0)(即从扩散过程中某一时刻t得到的概率密度函数)对应于原始图像 x0 的样本替换图像中已经被确定(或者说"固定")了值得那些位置。这个过程会持续多次迭代以逐渐生成最终结果。
2.4 Noised CLIP models
为了更好地对比 classifier guidance 技术,作者训练了一个噪声 CLIP 模型。这个模型使用一个图像编码器 f(xt, t),它接收带有噪声的图像 xt,并且用原始CLIP 模型相同的目标函数进行训练。
在 64×64 分辨率下使用与基础模型相同的噪声来训练这些模型。
三、效果
3.1 定性对比
这里对比了 CLIP guidance 和 classifier-free guidance 的效果
- classifier-free guidance 的结果看起来更真实,所以后面作者都使用了 classifier-free guidance

下图 1 展示了 GLIDE with classifier-free guidance 能根据很多 prompt 生成图片,且对光照和影子处理的很好,风格也很多变
图像修复:



不同引导方式的对比:

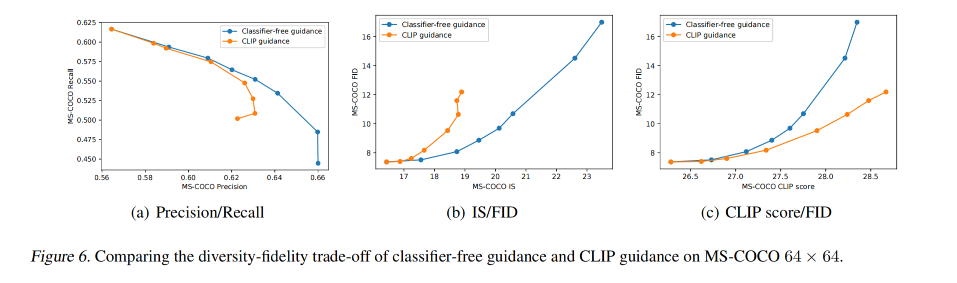
3.2 定量对比
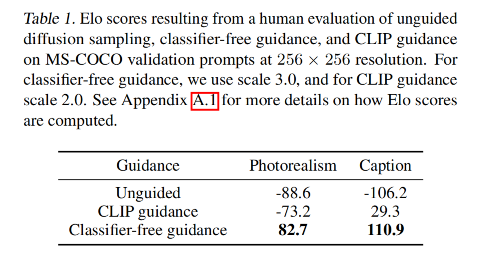
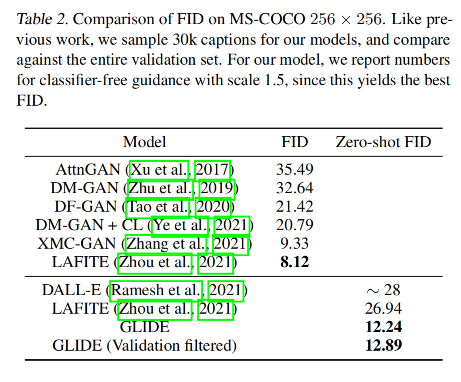

3.3 失败案例

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!