记录一次云原生线上服务数据迁移全过程
2023-12-14 10:34:33
文章目录
背景
校园 e 站,一群大学生在毕业前夕,为打破信息差而开发的一个校园论坛。一个从零到一全靠一群大学生的满腔热忱而打造的一个前后端分离以小程序为最终展示载体的一个微服务架构体系的 App。并发量的初始定位为 w 级,使用到多级缓存、数据分库等等前沿技术,当然这也是本次就是数据迁移的根本原因所在,架构过于庞大,用户较少,资源空等率高,所以决定将服务缩容,降低运营成本。
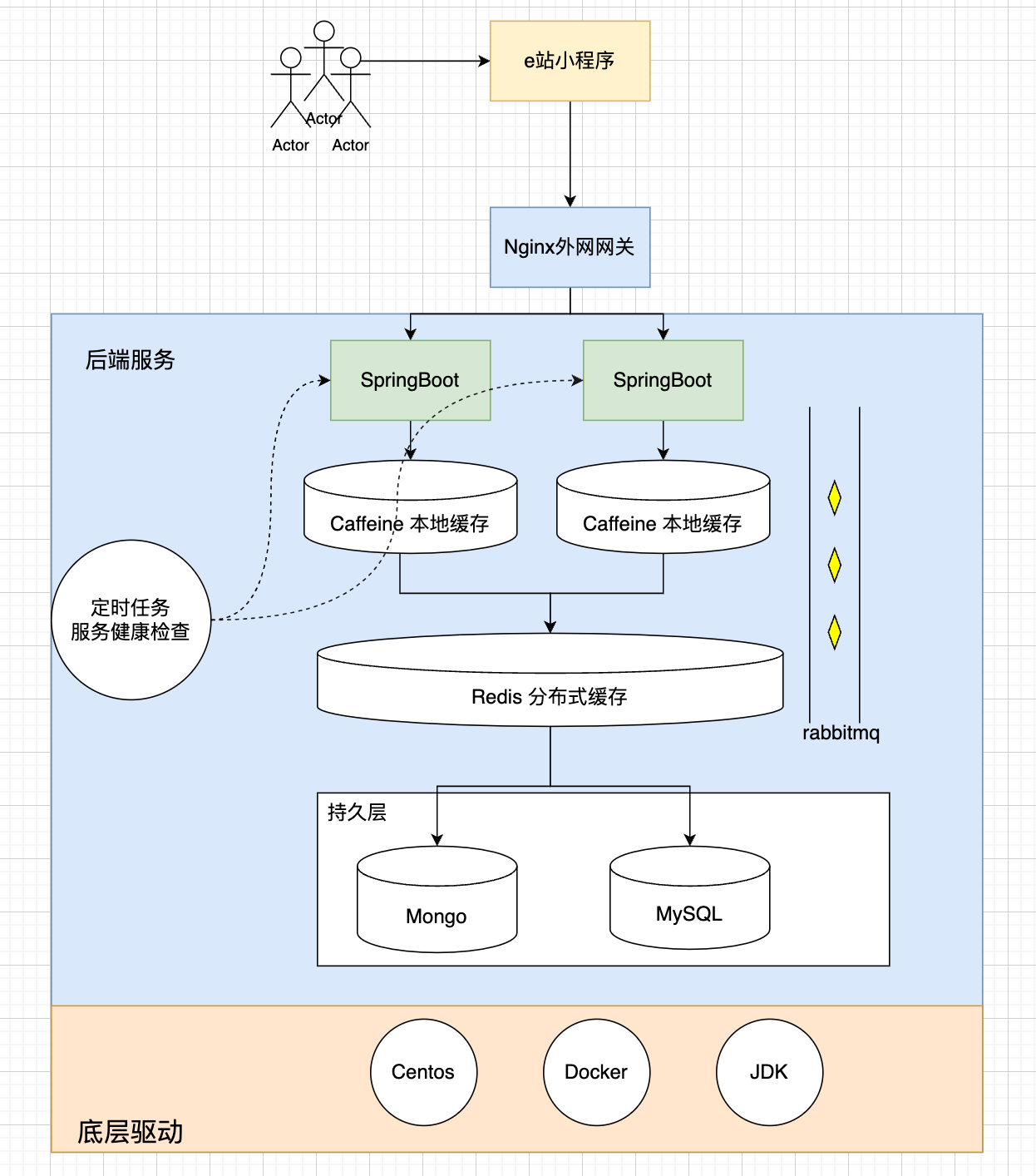
整体架构如上所示,本次需要迁移的数据重点为,Mongo 以及 MySQL 持久层数据。
迁移方案调研
因为持久层数据本身是通过 docker-compose进行容器编排加docker volume脚本启动,所以调研到的方案大体可分为以下几种:
- 在磁盘级别进行
volume迁移 - 以旧数据库为主库,新数据库为从库,进行主从同步
- 在应用层面使用应用本身的备份恢复功能进行数据迁移
三种方案的优缺点
| 方案 | 优点 | 缺点 |
|---|---|---|
| 磁盘 | 暂时想不到,可能是看起来很牛 | 技术要求高,容易出现兼容性问题 |
| 主从 | 停机时间短 | 需要改动两次服务启动脚本(主从搭建时,从库切主库) |
| 备份恢复 | 操作简单,风险低 | 停机时间较长 |
在综合考虑下,选择了方案三进行备份恢复。
原因也很简单,生产级别一般都是选择风险最低且操作简单的方式,因为不管你有多牛,也没办法保证迁移过程不会出现一点问题~
迁移过程
服务监控脚本定时任务暂停
本地副本服务启动,在线服务下线
MySQL 数据迁移
遇到的第一个问题是,导出的文件压缩前 38M zip 压缩后依然 3.9 M,远大于 phpmyadmin 允许上传的 2M ,此时有两个方案:一是调大数据导入的文件大小限制,二是减少数据量。按道理正常使用数据,不应该那么大,毕竟用户量不大,且主要数据存在 mongo 中,在查询了之后发现,有一个请求时间监控的表数据量达到 50W
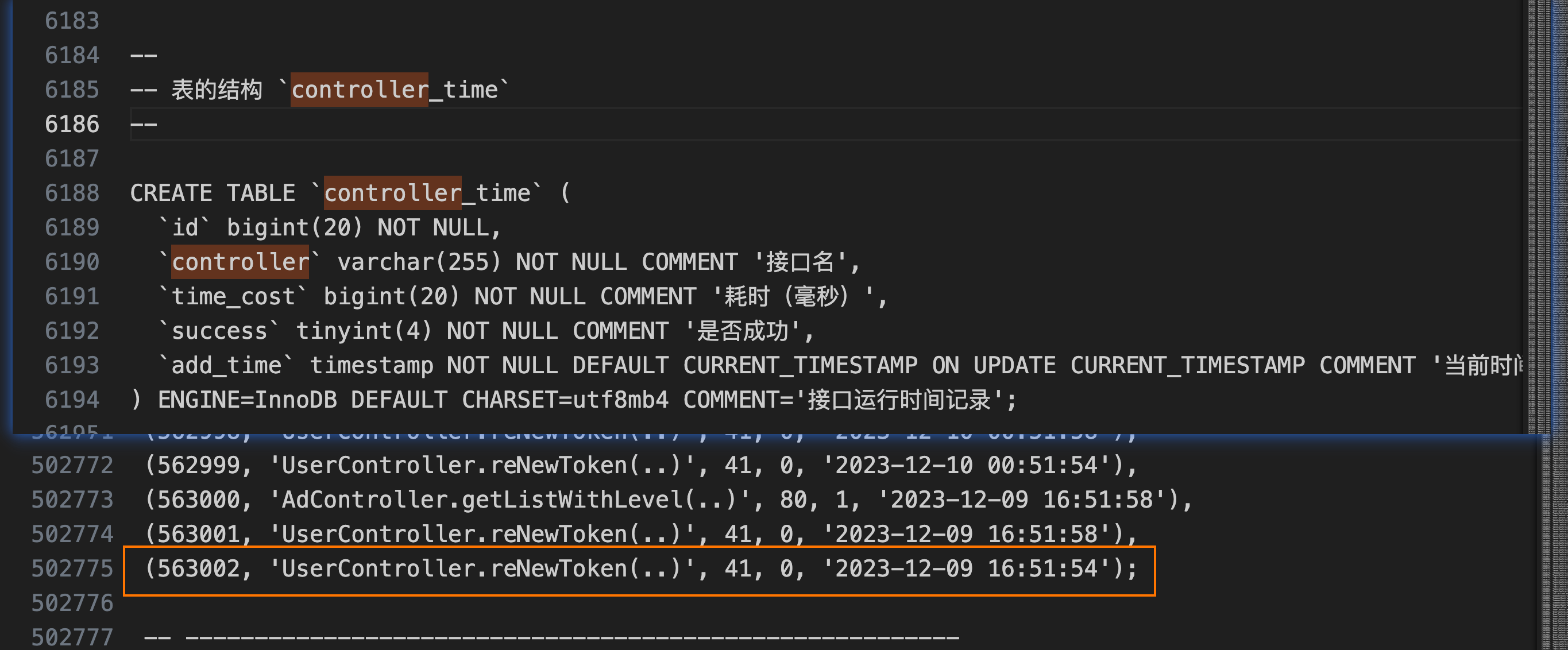
执行 sql 将数据压缩,
-- 数据平均
insert into controller_time(controller, time_cost, success)
SELECT controller, AVG(time_cost) as time_cost, success
FROM controller_time where id < 563003
GROUP BY controller, success
;
-- 删除旧数据
delete from controller_time where id < 563003;
controller_time 数据压缩后导出文件 4.5M 压缩后 359K,导入新数据库约十秒。
Mongo 数据迁移
进入 新机器 容器内,到 /usr/bin目录调用,容器已有的 mongo命令
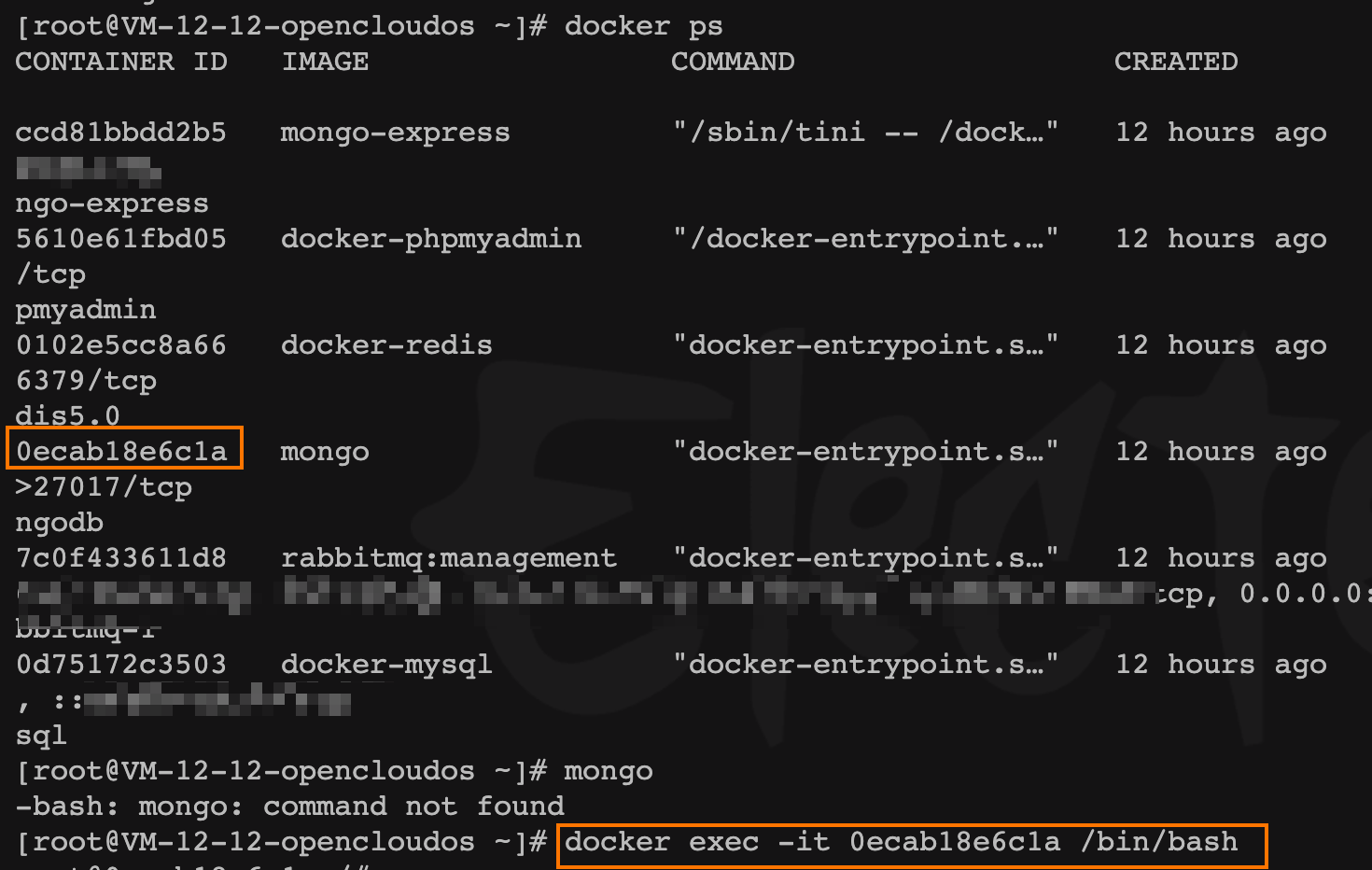
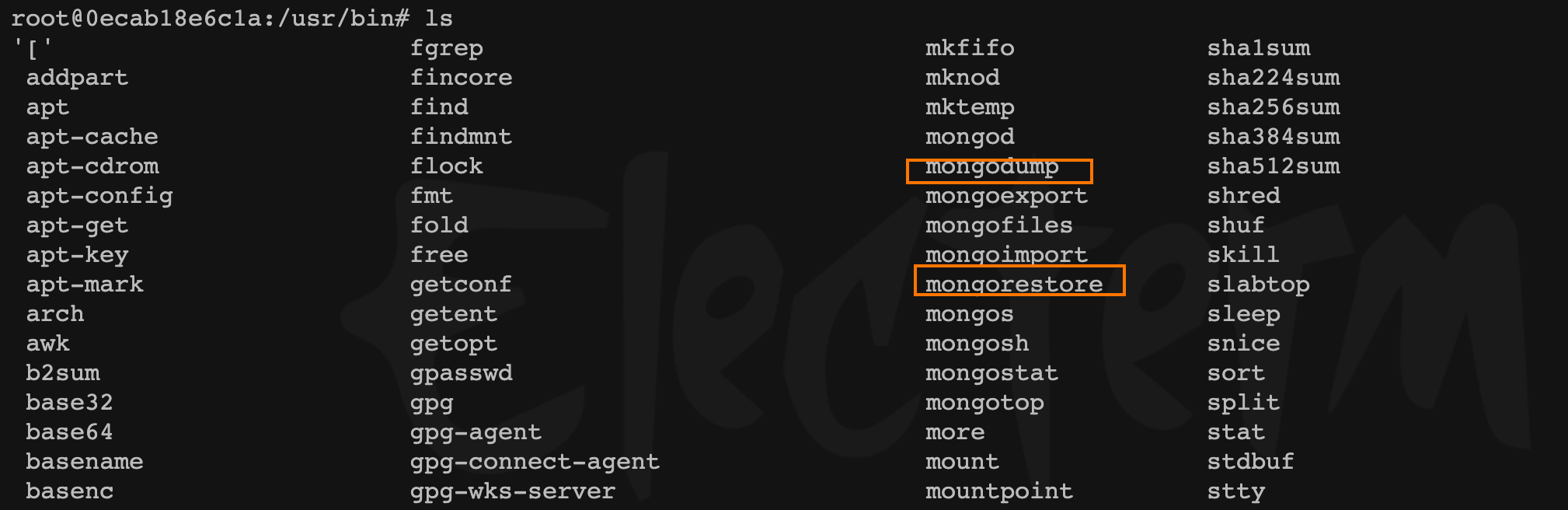
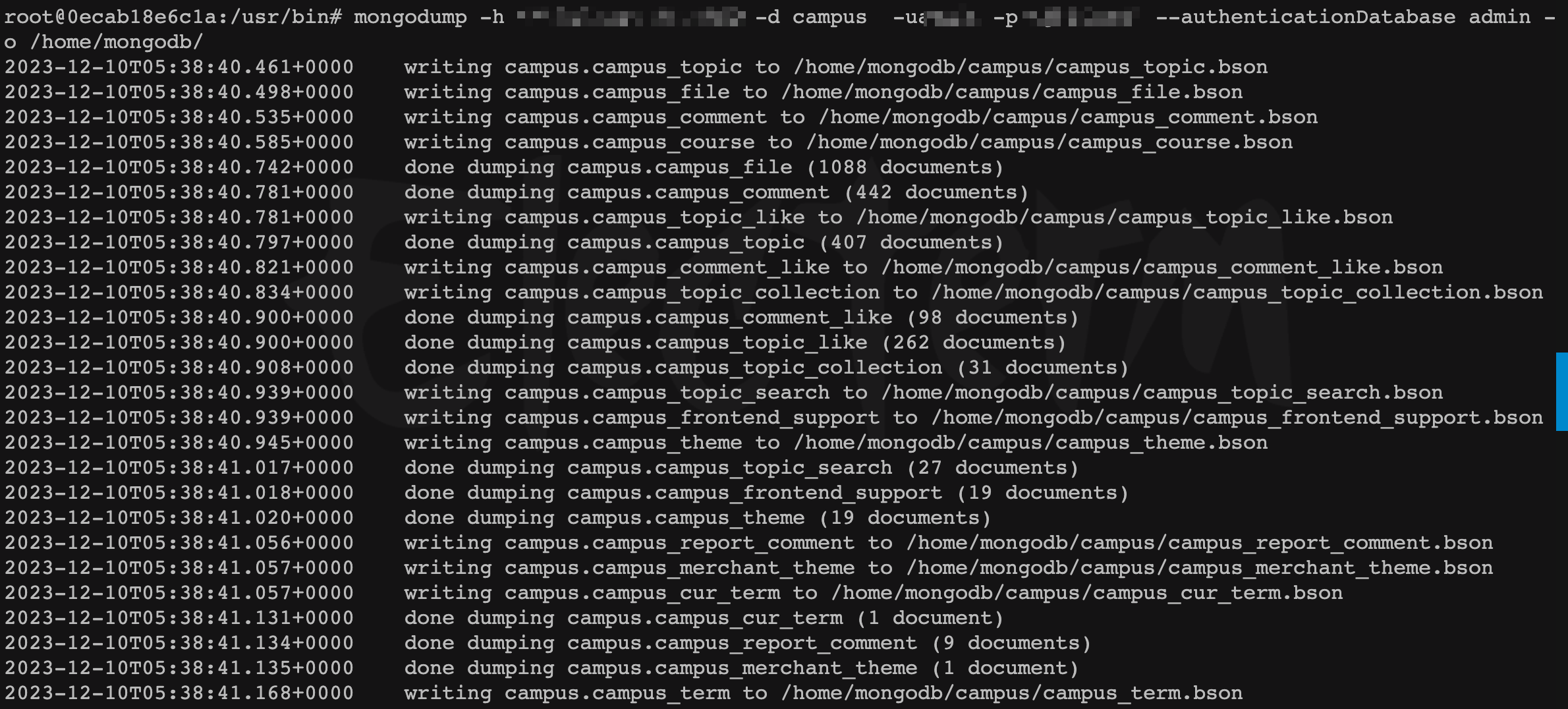
- 将远程
mongo(旧的数据库)数据备份到新机器容器内
mongodump -h <remote_ip>:<remote_port> -d <database> -u<user_name> -p<user_password> --authenticationDatabase admin -
o /home/mongodb/
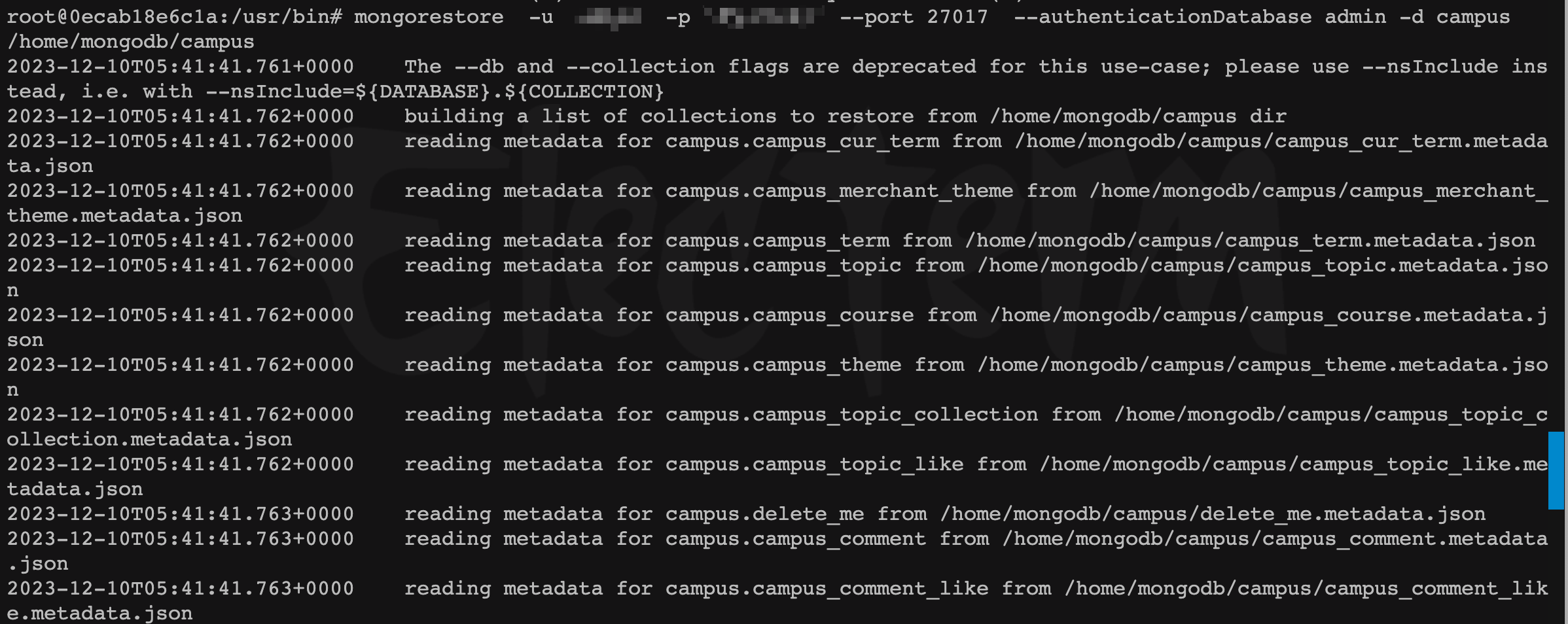
- 数据恢复到新
mongo
mongorestore -u <local_user_name> -p <user_password> --port 27017 --authenticationDatabase admin -d <database>
/home/mongodb/
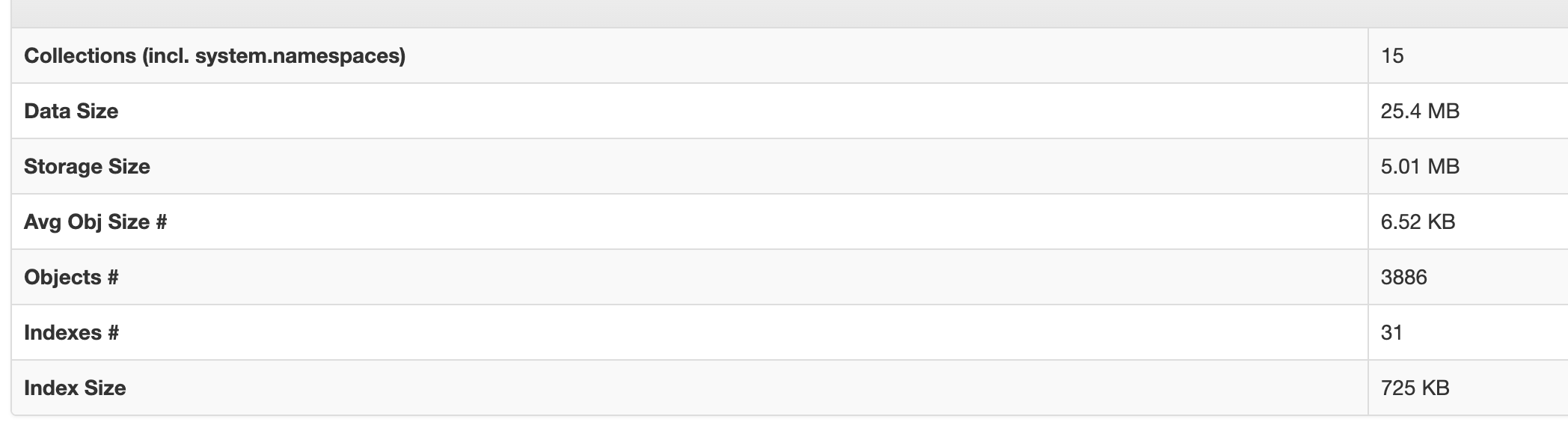
- 数据恢复结果
切换新数据库 ip 本地服务启动
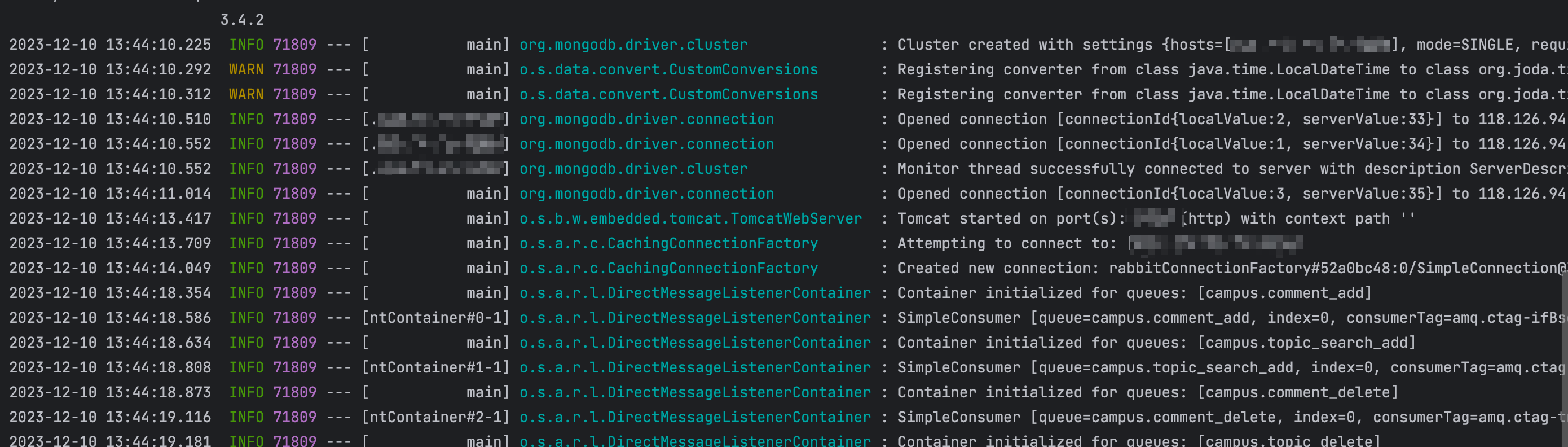
数据库连接验证
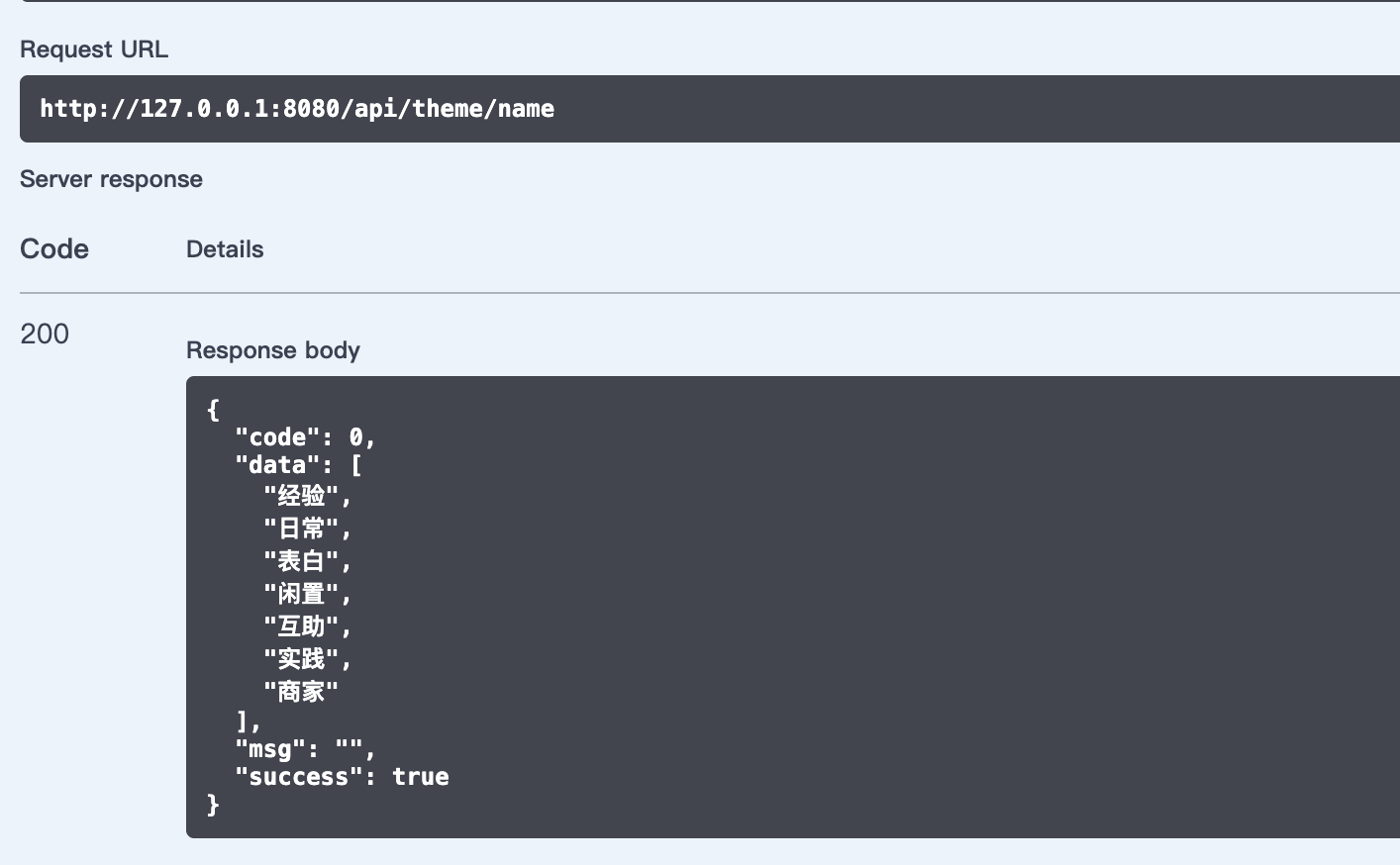
服务打包部署
mvn clean install package
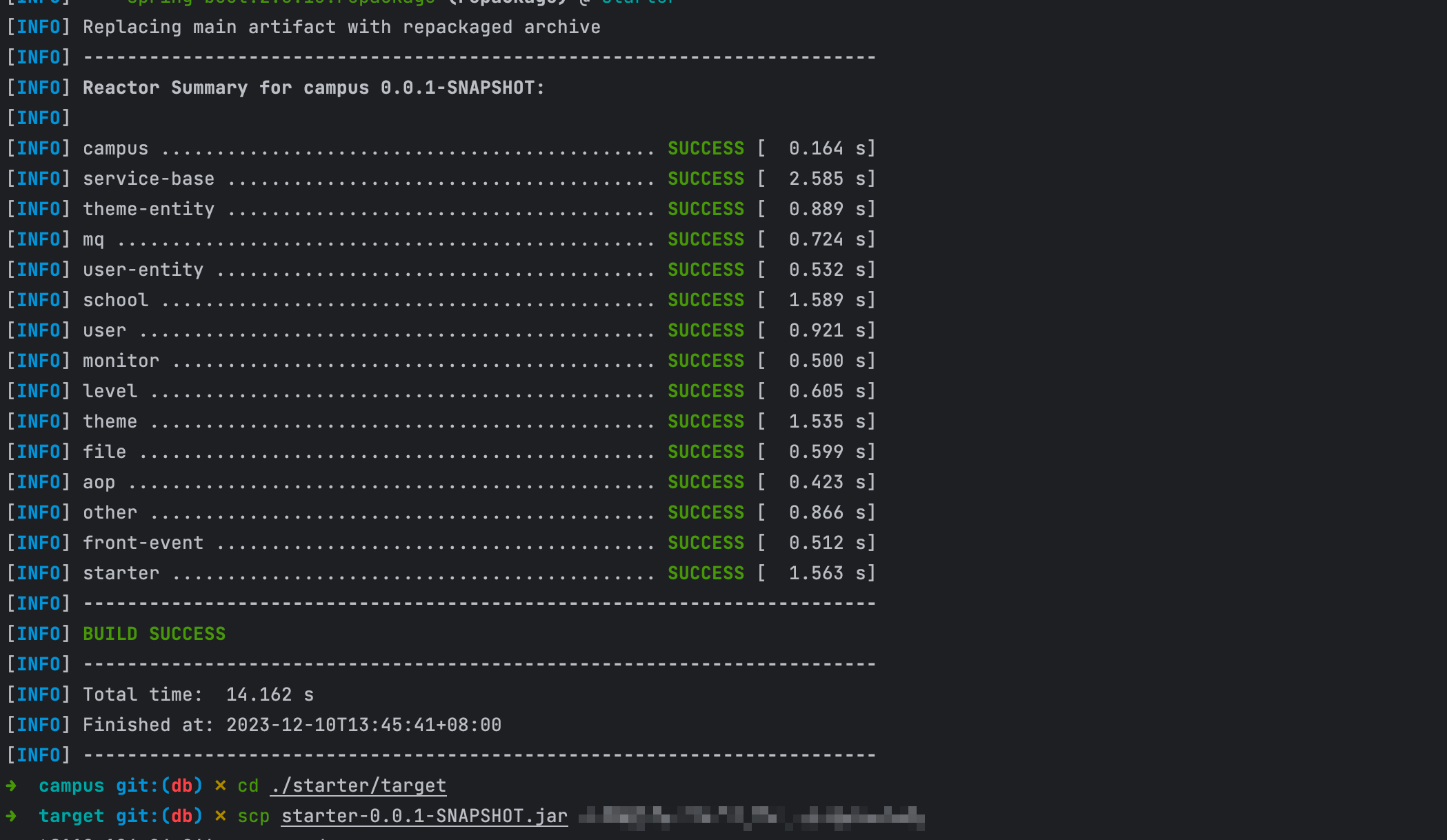
服务重启

前端恢复正常
监控脚本定时任务启动
旧服务器器容器关闭
迁移总结
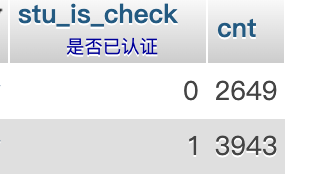
总涉及用户 6592 个用户,其中已通过校园认证的用户 3943 ,全部数据迁移完毕,服务恢复于 13:47 总耗时约 17 分钟。
文章来源:https://blog.csdn.net/qq_45704048/article/details/134910851
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!