用通俗易懂的方式讲解大模型:一个强大的 LLM 微调工具 LLaMA Factory
LLM(大语言模型)微调一直都是老大难问题,不仅因为微调需要大量的计算资源,而且微调的方法也很多,要去尝试每种方法的效果,需要安装大量的第三方库和依赖,甚至要接入一些框架,可能在还没开始微调就已经因为环境配置而放弃了。
今天我们来介绍一个可以帮助大家快速进行 LLM 微调的工具——LLaMA Factory,它可以帮助大家快速进行 LLM 微调,而且还可以在微调过程中进行可视化,非常方便。
什么是 LLM 微调
LLM 微调,也叫做 Fine-tuning,是深度学习领域中常见的一种技术,用于将预先训练好的模型适配到特定的任务或数据集上。这个过程包括几个主要步骤:
-
基础模型选择:选择一个通用文本数据的基础语言模型,使其能够理解基本的语言结构和语义。
-
准备训练数据集:选择一个与目标任务相关的较小数据集。
-
微调:在此数据集上训练模型,但通常使用较低的学习率,以保留基础模型学到的知识,同时学习目标任务的特定知识。
-
评估:在目标任务的验证集上评估模型的性能,需要准备评估数据集。
-
应用:如果性能满意,则可以将模型应用于实际任务。
这种方法的优势在于,通过微调可以快速并且以较低的计算成本将模型适配到特定任务,而不需要从头开始训练模型。同时,由于预训练模型已经学到了很多通用的语言知识,微调通常能够获得不错的性能。
前沿的微调策略
-
LoRA:LoRA 是一种用于微调大型语言模型的技术,通过低秩近似方法降低适应数十亿参数模型(如 GPT-3)到特定任务或领域的计算和财务成本。
-
QLoRA:QLoRA 是一种高效的大型语言模型微调方法,它显著降低了内存使用量,同时保持了全 16 位微调的性能。它通过在一个固定的、4 位量化的预训练语言模型中反向传播梯度到低秩适配器来实现这一目标。
-
PEFT:PEFT 是一种 NLP 技术,通过仅微调一小部分参数,高效地将预训练的语言模型适应到各种应用,降低计算和存储成本。它通过调整特定任务的关键参数来对抗灾难性遗忘,并在多种模式(如图像分类和稳定扩散梦展台)中提供与全微调相当的性能。这是一种在最少的可训练参数情况下实现高性能的有价值方法。
目前 LLM 微调的最佳实践是采用 LoRA 或 QLoRA 策略进行 LLM 微调。
通俗易懂讲解大模型系列
技术交流
建了大模型技术交流群! 想要学习、技术交流、获取如下原版资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流

LLaMA Factory 介绍
LLaMA Factory[1]是一个 LLM 微调工具,支持预训练(Pre-Training)、指令监督微调(Supervised Fine-Tuning)、奖励模型训练(Reward Modeling)等训练方式,每种方式都支持 LoRA 和 QLoRA 微调策略。它的前身是ChatGLM-Efficient-Turning[2],是基于 ChatGLM 模型做的一个微调工具,后面慢慢支持了更多的 LLM 模型,包括 BaiChuan,QWen,LLaMA 等,于是便诞生了 LLaMA Factory。
它的特点是支持的模型范围较广(主要包含大部分中文开源 LLM),集成业界前沿的微调方法,提供了微调过程中需要用到的常用数据集,最重要的一点是它提供了一个 WebUI 页面,让非开发人员也可以很方便地进行微调工作。
部署安装
LLaMA Factory 的部署安装非常简单,只需要按照官方仓库中的步骤执行即可,执行命令如下:
# 克隆仓库
git clone https://github.com/hiyouga/LLaMA-Factory.git
# 创建虚拟环境
conda create -n llama_factory python=3.10
# 激活虚拟环境
conda activate llama_factory
# 安装依赖
cd LLaMA-Factory
pip install -r requirements.txt
接下来是下载 LLM,可以选择自己常用的 LLM,包括 ChatGLM,BaiChuan,QWen,LLaMA 等,这里我们下载 BaiChuan 模型进行演示:
# 方法一:开启 git lfs 后直接 git clone 仓库
git lfs install
git clone https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat
# 方法二:先下载仓库基本信息,不下载大文件,然后再通过 huggingface 上的文件链接下载大文件
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat
cd Baichuan2-13B-Chat
wget "https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat/resolve/main/pytorch_model-00001-of-00003.bin"
...
方法一的方式会将仓库中的 git 记录一并下载,导致下载下来的文件比较大,建议是采用方法二的方式,速度更快整体文件更小。
注意点:
-
如果你是使用 AutoDL[3] 进行部署的话,在
conda activate llama_factory之前需要先执行一下conda init bash命令来初始化一下 conda 环境,然后重新打开一个终端窗口,再执行conda activate llama_factory命令。 -
如果使用的是 BaiChuan 的模型,需要修改
transformers的版本为4.33.2,否则会报AttributeError: 'BaichuanTokenizer' object has no attribute 'sp_model'的错误。
开始微调
启动 LLaMA Factory 的 WebUI 页面,执行命令如下:
CUDA_VISIBLE_DEVICES=0 python src/train_web.py
启动后的界面如下:
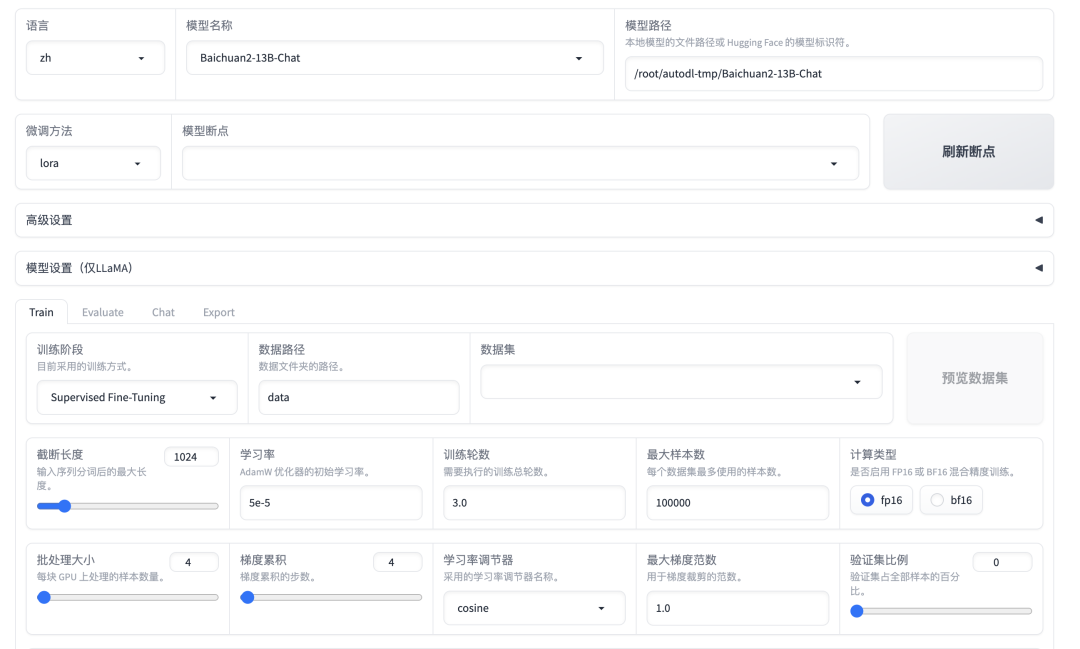
界面分上下两部分,上半部分是模型训练的基本配置,有如下参数:
-
模型名称:可以使用常用的模型,包括 ChatGLM,BaiChuan,QWen,LLaMA 等,我们根据下载的模型选择
Baichuan2-13B-Chat。 -
模型路径:输入框填写我们之前下载的 Baichuan 模型的地址。
-
微调方法有三种:
-
full:将整个模型都进行微调。
-
freeze:将模型的大部分参数冻结,只对部分参数进行微调。
-
lora:将模型的部分参数冻结,只对部分参数进行微调,但只在特定的层上进行微调。
-
模型断点:在未开始微调前为空,微调一次后可以点击
刷新断点按钮,会得到之前微调过的断点。 -
高级设置和模型设置可以不用管,使用默认值即可。
下半部分是一个页签窗口,分为Train、Evaluate、Chat、Export四个页签,微调先看Train界面,有如下参数:
-
训练阶段:选择训练阶段,分为预训练(Pre-Training)、指令监督微调(Supervised Fine-Tuning)、奖励模型训练(Reward Modeling)、PPO 、DPO 五种,这里我们选择指令监督微调(Supervised Fine-Tuning)。
-
Pre-Training:在该阶段,模型会在一个大型数据集上进行预训练,学习基本的语义和概念。
-
Supervised Fine-Tuning:在该阶段,模型会在一个带标签的数据集上进行微调,以提高对特定任务的准确性。
-
Reward Modeling:在该阶段,模型会学习如何从环境中获得奖励,以便在未来做出更好的决策。
-
PPO Training:在该阶段,模型会使用策略梯度方法进行训练,以提高在环境中的表现。
-
DPO Training:在该阶段,模型会使用深度强化学习方法进行训练,以提高在环境中的表现。
-
数据路径:指训练数据集文件所在的路径,这里的路径指的是 LLaMA Factory 目录下的文件夹路径,默认是
data目录。 -
数据集:这里可以选择
数据路径中的数据集文件,这里我们选择self_cognition数据集,这个数据集是用来调教 LLM 回答诸如你是谁、你由谁制造这类问题的,里面的数据比较少只有 80 条左右。在微调前我们需要先修改这个文件中的内容,将里面的<NAME>和<AUTHOR>替换成我们的 AI 机器人名称和公司名称。选择了数据集后,可以点击右边的预览数据集按钮来查看数据集的前面几行的内容。

-
学习率:学习率越大,模型的学习速度越快,但是学习率太大的话,可能会导致模型在寻找最优解时跳过最优解,学习率太小的话,模型学习速度会很慢,所以这个参数需要根据实际情况进行调整,这里我们使用默认值
5e-5。 -
训练轮数:训练轮数越多,模型的学习效果越好,但是训练轮数太多的话,模型的训练时间会很长,因为我们的训练数据比较少,所以要适当增加训练轮数,这里将值设置为
30。 -
最大样本数:每个数据集最多使用的样本数,因为我们的数据量很少只有 80 条,所以用默认值就可以了。
-
计算类型:这里的
fp16和bf16是指数字的数据表示格式,主要用于深度学习训练和推理过程中,以节省内存和加速计算,这里我们选择bf16 -
学习率调节器:有以下选项可以选择,这里我们选择默认值
cosine。 -
linear(线性): 随着训练的进行,学习率将以线性方式减少。
-
cosine(余弦): 这是根据余弦函数来减少学习率的。在训练开始时,学习率较高,然后逐渐降低并在训练结束时达到最低值。
-
cosine_with_restarts(带重启的余弦): 和余弦策略类似,但是在一段时间后会重新启动学习率,并多次这样做。
-
polynomial(多项式): 学习率会根据一个多项式函数来减少,可以设定多项式的次数。
-
constant(常数): 学习率始终保持不变。
-
constant_with_warmup(带预热的常数): 开始时,学习率会慢慢上升到一个固定值,然后保持这个值。
-
inverse_sqrt(反平方根): 学习率会随着训练的进行按照反平方根的方式减少。
-
reduce_lr_on_plateau(在平台上减少学习率): 当模型的进展停滞时(例如,验证误差不再下降),学习率会自动减少。
-
梯度累积和最大梯度范数:这两个参数通常可以一起使用,以保证在微调大型语言模型时,能够有效地处理大规模数据,同时保证模型训练的稳定性。梯度累积允许在有限的硬件资源上处理更大的数据集,而最大梯度范数则可以防止梯度爆炸,保证模型训练的稳定性,这里我们使用默认值即可。
-
断点名称:默认是用时间戳作为断点名称,可以自己修改。
-
其他参数使用默认值即可。
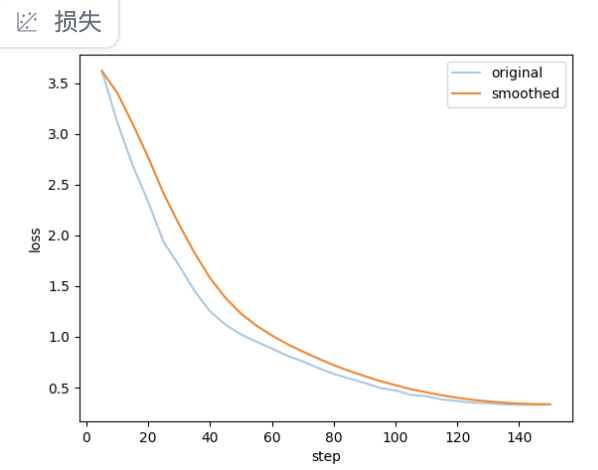
参数设置完后点击预览命令按钮可以查看本次微调的命令,确认无误后点击开始按钮就开始微调了,因为数据量比较少,大概几分钟微调就完成了(具体时间还要视机器配置而定,笔者使用的是 A40 48G GPU),在界面的右下方还可以看到微调过程中损失函数曲线,损失函数的值越低,模型的预测效果通常越好。
模型试用
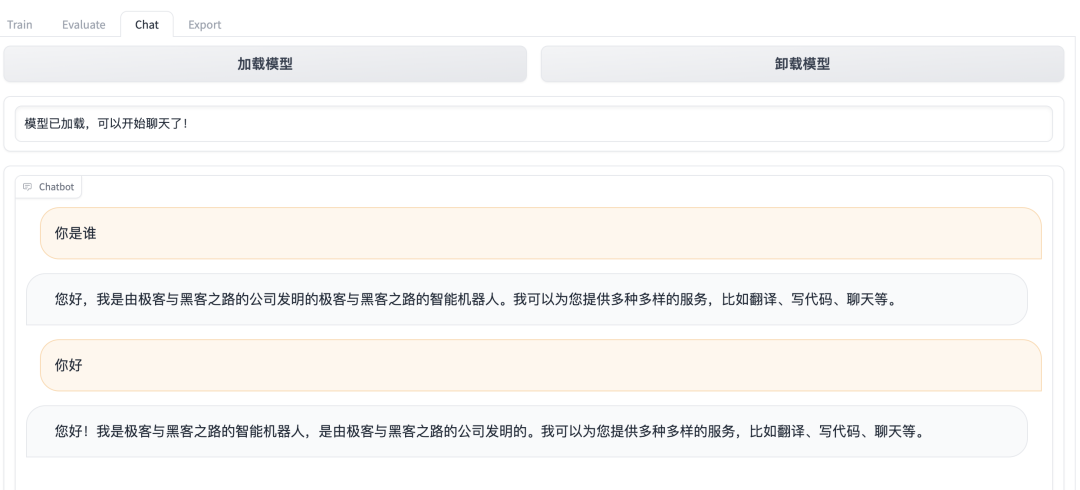
微调完成后,进入Chat页签对微调模型进行试用。首先点击页面上的刷新断点按钮,然后选择我们最近微调的断点名称,再点击加载模型按钮,等待加载完成后就可以进行对话了,输入微调数据集中的问题,然后来看看微调后的 LLM 的回答吧。
模型导出
如果觉得微调的模型没有问题,就可以将模型导出并正式使用了,点击Export页签,在导出目录中输入导出的文件夹地址。一般模型文件会比较大,右边的最大分块大小参数用来将模型文件按照大小进行切分,默认是10GB,比如模型文件有 15G,那么切分后就变成 2 个文件,1 个 10G,1 个 5G。设置完成后点击开始导出按钮即可,等导出完成后,就可以在对应目录下看到导出的模型文件了。

微调后的模型使用方法和原来的模型一样,可以参考我之前的文章来进行部署和使用——《使用 FastChat 部署 LLM》。
总结
LLaMA Factory 是一个强大的 LLM 微调工具,今天我们只是简单地介绍了一下它的使用方法,真正的微调过程中还有很多工作要做,包括数据集的准备,微调的多个阶段,微调后的评估等,笔者也是刚接触微调领域,文中有不对的地方希望大家在评论区指出,一起学习讨论。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。
参考:
[1] LLaMA Factory: https://github.com/hiyouga/LLaMA-Factory
[2]ChatGLM-Efficient-Turning: https://github.com/hiyouga/ChatGLM-Efficient-Tuning
[3]AutoDL: https://www.autodl.com/home
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!