早上好,我的leetcode【函数】(第一期)
写在前面:每天早上到实验室早上昏昏欲睡,那不如写一题吧~
文章目录
371. 两整数之和
两整数之和,梦开始的地方, 两整数之和。

一开始我直接a+b,按要求做并没有思路,于是看看题解,说要知道这个公式:a + b = a ^ b + (a & b) << 1
a ^ b是a异或b,异或这里可看做是相加但是不显现进位。
# 比如5 ^ 3
/*0 1 0 1
0 0 1 1
------------
0 1 1 0 */
如果看成传统的加法,不就是1+1=2,进1得0。但是这里没有显示进位出来,仅是相加。0+1或者是1+0都不用进位。
(a & b) << 1 相与为了让进位显现出来,比如5 & 3。
//相与为了让进位显现出来,比如5 & 3
/* 0 1 0 1
0 0 1 1
------------
0 0 0 1
上面的最低位1和1相与得1,而在二进制加法中,这里1+1也应该是要进位的,所以刚好吻合,但是这个进位1应该要再往前一位,所以左移一位。
经过上面这两步,如果进位不等于0,那么就是说还要把进位给加上去。用了尾递归,一直递归到进位是0。(一个函数在调用自身之后没有再执行其他操作,而是直接将返回值传递给函数调用的上级,这样的特性避免了新的调用栈帧的创建,使得函数调用只需要一个调用栈帧即可)
代码1.(1):
class Solution {
public:
int getSum(int a, int b) {
if(a == 0 || b == 0) return a ^ b;
return getSum(a^b, (a&b) << 1);
}
};
代码1.(2):
和代码1.(1)思路一致。
class Solution {
public:
int getSum(int a, int b) {
int sum = a ^ b;
int carry =(a & b) << 1;
return carry == 0? sum : getSum(sum, carry);
}
};
代码2 C语言限定:
直接把 a 的值作为指针值,再偏移 b 个单位,就是 a + b。
int getSum(int a, int b) {
return (int)(&((char*)a)[b]);
}
面试题08.05.递归乘法
递归乘法
首先先说我一开始的思路:先考虑简单情况,其实递归最主要的就是边界情况。然后再写出递推式子即可,有点像动态规划的思路(?),
首先a或者b为0,那肯定返回0,
如果a=1,那么结果就是b;如果b=1,那么结果就是a。
考虑复杂情况:
a×b可以写成两种递归的方式:
b如果是正数,则依次减1至1;b如果是负数,则依次加1至-1。
例子:
3×4,= 3 × 3 + 3 = 3 × 2 + 3 + 3 = 3 × 1 + 3 + 3 + 3
3×-4 = 3 × (-3) -3 = 3 × (-2) -3 -3 = 3 × (-1) -3 -3 -3
那么就可以写出如下递归代码:
class Solution {
public:
int multiply(int A, int B) {
int c;
if (A == 0 || B == 0){
return 0;
}
if (B > 1){
c = multiply(A, B-1) + A;
}
else if (B == 1){
c = A;
}
else if (B == -1){
c = -A;
}else if (B < -1){
c = multiply(A, B+1) - A;
}
return c;
}
};
然后看了眼评论区,要求只是两个正整数的相乘。正整数的话,就不用考虑0和负数了,B边界在1即可。
代码1:
class Solution {
public:
int multiply(int A, int B) {
int c;
if (B == 1) return A;
return A + multiply(A, --B);
}
};
代码2:
计算char[A][B]的大小(以字节为单位),通过使用sizeof运算符,我们可以获取数组所占用的内存大小。确实足够吝啬了
class Solution {
public:
int multiply(int A, int B) {
return sizeof(char[A][B]);
}
};
29.两数相除
两数相除

将两数相除,要求不使用 乘法、除法和取余运算
比较有意思的是数值范围,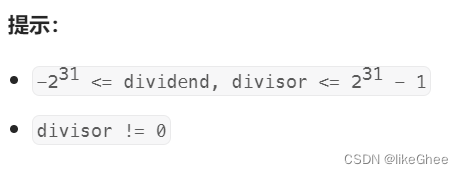
输入范围刚好是int32位的最大最小值,知道补码的话都知道,正数是刚好取不到2^31的,而负数可以取到-2^31。
结果要取到2^31,只有一种可能那就是:
dividend = -2147483648 divisor = -1 ,
预期结果 2147483647。
代码1,最朴素的除法思想,接收两个整型参数a和b。计算a除以b的商。
(这个时间复杂度为O(n)会超时)
首先,判断是否满足特殊情况:当a为最小整数值(INT_MIN)且b为-1时,返回最大整数值(INT_MAX)。
接着,判断两数的符号,如果它们的符号不同,则将结果的符号设为负数;否则设为正数。然后将a和b都取负数(因为补码表示负数范围更大),以便进行减法运算。
定义一个无符号整数变量res用于存储商的值,初始值为0。在while循环中,当a小于等于b时,将a减去b,并将商的值加1:
int divide(int a, int b) {
if (a == INT_MIN && b == -1) return INT_MAX;
int sign = (a > 0) ^ (b > 0) ? -1 : 1;
if (a > 0) a = -a;
if (b > 0) b = -b;
unsigned int res = 0;
while (a <= b) {
a -= b;
res++;
}
// 因为不能使用乘号,所以将乘号换成三目运算符
return sign == 1 ? res : -res;
}
代码2.(1):
我们需要改进这部分
while (a <= b) {
a -= b;
res++;
}
这是一次一次减除数,我们可以尝试减去除数的倍数。
15/3 => 15 - 3 => 15 - 3 * 2 => 15 - 3 * 4
整数除法的实现,接收两个整型参数a和b。计算a除以b的商。
首先判断特殊情况:当a等于最小整数值(INT_MIN)且b等于-1时,返回最大整数值(INT_MAX)。
然后判断两数的符号,如果它们的符号不同,则将结果的符号设为负数;否则设为正数。接着将a和b都取负数(因为补码表示负数范围更大),以便进行减法运算。
接下来进行循环计算,每次循环中,首先将b(除数)的值赋给value,然后初始化一个变量k(商值)为1。接下来,它会进行一个内部循环,条件是value大于等于0xc0000000且a小于等于value+value。在这个内部循环中,value会不断翻倍,同时k也会翻倍。如果k已经超过了INT_MAX的一半,那么函数会直接返回INT_MIN。最后,a(被除数)会减去value,res(结果返回的商值)会加上k。
循环结束后,根据之前判断的符号,返回相应的结果。
边界条件解释:
value = 0xc0000000(十六进制) = 11000000000000000000000000000000(补码表示) = -2^30
a = 11000000000000000000000000000000 + 11000000000000000000000000000000 = 0x80000000 = -2^31
这是value和a的边界,value不会比0xc0000000还要小,因为a不能小于-2^31
int divide(int a, int b) {
if (a == INT_MIN && b == -1) return INT_MAX;
int sign = (a > 0) ^ (b > 0) ? -1 : 1;
if (a > 0) a = -a;
if (b > 0) b = -b;
int res = 0;
while (a <= b) {
int value = b;
int k = 1;
// value >= 0xc0000000保证value + value不会越界
while (value >= 0xc0000000 && a <= value + value) {
value += value;
// 代码优化:如果 k 已经大于最大值的一半的话,那么直接返回最小值
// 因为这个时候 k += k 的话肯定会大于等于 2147483648 ,这个超过了题目给的范围
if (k > INT_MAX / 2) return INT_MIN;
k += k;
}
a -= value;
res += k;
}
// bug 修复:因为不能使用乘号,所以将乘号换成三目运算符
return sign == 1 ? res : -res;
}
代码2.(2):
递归版
简单思路:60/8 = (60-32)/8 + 4 = (60-32-16)/8 + 2 + 4 = 1 + 2 + 4 = 7
思路实现(这里用了long,所以仅供参考),使用递归实现的整数除法函数,函数名为div,接收两个长整型参数a和b。函数的主要功能是计算a除以b的商。
函数首先判断a是否小于b,如果是,则返回0,因为取正数直接就是0。接下来,定义一个变量count用于存储商的值,初始值为1。然后定义一个变量tb,将其初始化为b。
在while循环中,判断(tb+tb)<=a,如果满足条件,则将count的值翻倍,并将tb的值翻倍。循环结束后,调用div(a-tb, b)递归计算余数部分的商,并将其与当前的商相加,最后返回结果:
int div(long a, long b){
if(a<b) return 0;
long count = 1;
long tb = b;
while((tb+tb)<=a){
count = count + count;
tb = tb+tb;
}
return count + div(a-tb,b);
}
代码3:
位运算优化,乘以2可以用左移1位代替 <<1
value += value;
k += k;
代码4:
再次优化的思路
从31位左移开始,一直尝试到0
22 - (3 << 31) < 0
22 - (3 << 30) < 0
…
22 - (3 << 3) = 22 - 3 * 2 * 2 * 2 = -2 < 0
22 - (3 << 2) = 10 > 0
下面从10开始
10肯定是小于等于22的一半的,从左移1位开始就好
10 - (3 << 1) = 10 - 6 = 4 > 0
4肯定是小于10的一半,从0开始
4 - (3 << 0) = 1 > 0
1 < 3
结束
时间复杂度是O(1)
乘以容易越界,所以改成a右移。
就是原本b做乘法,变成a做除法。
如果x是最小值,int ux = abs(x); abs(x)仍然是最小值
a == INT_MIN,被除数先减去一个除数,避免abs(x)后还是负数的情况
b == INT_MIN,结果不是1就是0,和a判断一下就好
int divide(int a, int b) {
if (a == INT_MIN && b == -1) return INT_MAX;
int res = 0;
// 处理边界,防止转正数溢出
// 除数绝对值最大,结果必为 0 或 1
if (b == INT_MIN) {
return a == b? 1 : 0;
}
// 被除数先减去一个除数
if (a == INT_MIN) {
a -= -abs(b);
res += 1;
}
int sign = (a > 0) ^ (b > 0) ? -1 : 1;
int ua = abs(a);
int ub = abs(b);
for (int i = 31; i >= 0; i--) {
if ((ua >> i) >= ub) {
ua = ua - (ub << i);
// 代码优化:这里控制 ans 大于等于 INT_MAX
if (res > INT_MAX - (1 << i)) {
return INT_MIN;
}
res += 1 << i;
}
}
// bug 修复:因为不能使用乘号,所以将乘号换成三目运算符
return sign == 1 ? res : -res;
}
时间复杂度O(1)
50.Pow(x,n)
早上好我的朋友~
今天是第四天了。加油哦

题目要求实现pow,这道题让我们求x的n次方,如果只是简单的用个 for 循环让x乘以自己n次的话,未免也把 LeetCode 上的题想的太简单了
那么我的第一个想法就是折半n然后递归啦
2^5 => 2^2 * 2^2 * 2^1
2^2 => 2^1 * 2^1 * 2^0
代码1:
class Solution {
public:
double myPow(double x, int n) {
if (n == 0) return 1;
if (n == 1) return x;
if (n == -1) return 1/x;
return myPow(x, n / 2) * myPow(x, n / 2) * myPow(x, n % 2);
}
};
但是会超出时间限制,我们需要想办法优化

递归代码的一个坏处是,当递归深度较大时,会使用大量的栈空间,可能导致栈溢出的问题。递归函数的调用开销也比较高。
现令n为指数,x为底数,现有pow(2, 10)需要计算,i依次折半,底数依次平方,我们会发现2^10 = 2^2 * 2^8,n恰好都是奇数。
可以再举一个pow(2, 12)的例子, 2^12 = 2^4 * 2^8,n恰好也都是奇数。
那么我们可以进行归纳,使用折半计算,每次把n缩小一半,这样n最终会缩小到0,任何数的0次方都为1,这时候我们再往回乘,如果此时n是偶数,直接把上次递归得到的值算个平方返回即可,如果是奇数,则还需要乘上个x的值。
2^10
n: 10 => 5 => 2 => 1
x: 2 => 2^2 => 2^4 => 2^8
2^12
n: 12 => 6 => 3 => 1
x: 2 => 2^2 => 2^4 => 2^8
快速幂模板:
class Solution {
public:
double myPow(double x, int n) {
double res = 1.0;
for(int i = n; i != 0; i /= 2){
if(i % 2 == 1){ // 如果指数是奇数,将结果乘以底数
res *= x;
}
x *= x;
}
return n < 0 ? 1 / res : res;
}
};
还有一点需要引起注意的是n有可能为负数,对于n是负数的情况,我可以先用其绝对值计算出一个结果再取其倒数即可
快速幂原理:
计算a^n的关键就在于如何将n拆分成2的幂之和,
比如a^105的105就可以写成=1+8+32+64,
计算a^2的幂次方是一件很容易的事情,

那么如何将n拆分成2的幂之和呢,观察例子可以发现105=1+8+32+64,不就是二进制表示形式吗
105 = 1101001
1 = 0000001
8 = 0001000
32 = 0100000
64 = 1000000
我们只要将105二进制中的4个1拆开就刚好能得到其他4个数字,
通过这种方式我们就能将任意正整数分解成2的幂之和
下面是一个用于快速计算幂的py函数。
给定一个底数(base)和指数(exponent),该函数使用循环和位运算来计算其幂。该函数的实现使用了右移运算符(>>),它将指数按位右移,每次将其除以2。使用按位与运算符(&)来检查exponent是否为奇数,如果是,则将结果(result)乘以base。最后,base被重复平方,直到exponent等于0。
def quick_power(base, exponent):
result = 1
while exponent > 0:
if exponent & 1:
result *= base
base *= base
exponent >>= 1
return result
面试题 16.07. 最大数值

我命由我不由天! 琴猫猫今天就这么先过了!(开玩笑)
class Solution {
public:
int maximum(int a, int b) {
return a > b ? a : b;
}
};
让我们来看看解题思路(来自faterazer的优秀题解):
根据提示,
我们不能使用 if-else 或者比较运算符,所以我们需要构思如何去返回结果,这里不妨构造一个计算公式
class Solution {
public:
int maximum(int a, int b) {
return a * k + b * (k ^ 1);
}
};
这里 k 的值应该为 1 或 0,且我们应使其:
当 a < b 时,k = 0,则 k ^ 1 = 1。此时计算结果等于 b;
当 a > b 是,k = 1,则 k ^ 1 = 0。此时计算结果等于 a。
那么如何让 k 满足我们的要求的呢?这里可以用算术运算+位运算操作:判断 a - b 的最高位(符号位),即:
当 a - b < 0 时,a - b 的最高位为 1,此时,k 应该为 0;
当 a - b > 0 时,a - b 的最高位为 0,此时,k 应该为 1;
k 的值和 a - b 的最高位恰好相反,这里很自然的再引入异或运算,可以得到代码:
class Solution {
public:
int maximum(int a, int b) {
int bitlen = sizeof(a) * 8;
// C/C++ 中负数右移最高位会补 1,因此需要转成无符号类型后再右移
// 将 a-b 的符号位移动到最左边,再与 1 异或取反,得到 k 的值
int k = static_cast<unsigned>(a - b) >> (bitlen - 1) ^ 1;
return a * k + b * (k ^ 1);
}
};
这样我们就返回了正确结果。但是需要注意 a - b 可能会导致溢出问题,一种简单的解决方式是用更大的类型(例如 long long)保存中间结果,但如果入参已经是系统支持的最大类型,那这种解法就失效了,所以并不完美。因此,我们来思考一下如何在给定的类型范围内解决这个问题。这里,我们需要分情况考虑:
当 a 和 b 同号时,a - b 不会溢出,使用上面的代码即可;
当 a 和 b 异号时,a - b 可能溢出,需要额外处理;
我们可以使用 a 的符号位异或 b 的符号位,当结果为 1 时,说明异号;结果为 0 时,说明同号。
现在来考虑异号情况。
我们思考 a 和 b 异号的情况,那么符号位为正的肯定是大于负号的。返回符号位为正的那个数即可
所以当异号时,我们应该直接返回正数,避免 a - b 的运算。那么当两数异号时,我们如何确定 k 的值呢?
当 a 为负数时,a 的符号位为 1,此时 k 应该为 0;
当 a 为正数时,a 的符号位为 0,k 应该为 1。
总结规律可以发现,k 的值应该等于 a 的符号位异或 1。现在来实现第二种情况的代码
class Solution {
public:
int maximum(int a, int b) {
int bitlen = sizeof(a) * 8;
int asign = static_cast<unsigned>(a) >> (bitlen - 1);
int k = asign ^ 1;
return a * k + b * (k ^ 1);
}
};
现在我们已经实现了两种不同情况下的代码,针对两数同号或异号的场景分别处理,以避免溢出问题,最后我们只需要将其组合起来。由于不能使用 if-else 语句,需要我们用一点 trick,&&(与)trick见下:
class Solution {
public:
int maximum(int a, int b) {
// 计算 int 类型的位数,避免不同系统下长度不同
int bitlen = sizeof(a) * 8;
// 计算 a 的符号位,b 的符号位
// C/C++ 中负数右移最高位会补 1,因此需要转成无符号类型后再右移
int asign = static_cast<unsigned>(a) >> (bitlen - 1);
int bsign = static_cast<unsigned>(b) >> (bitlen - 1);
// 假设 a 与 b 异号,计算 k 的值
int k = asign ^ 1;
// 当 a 和 b 异号时,asign ^ bsign ^ 1 为 0,由于 逻辑与运算 的短路性,将不再计算后半行代码,避免溢出
// 当 a 和 b 同号时,asign ^ bsign ^ 1 为 1,此时会执行后半行代码,重新对 k 赋值
int temp_cond = (asign ^ bsign ^ 1) && (k = static_cast<unsigned>(a - b) >> (bitlen - 1) ^ 1);
return a * k + b * (k ^ 1);
}
};
2119. 反转两次的数字
第六天,心有余而力不足,做点简单的~

思考过程:
根据提示,先考虑边界情况:
如果num==0,那么反转还是0,返回True
如果num==10^6,那么反转是1,返回False
如果num是一位数,则num为1,2,3…,9,返回True
如果num是10,反转为1,False出现
考虑num是两位数,则num可以为11,12,…,20,只有20是反转后为False
出现3个False情况,通过个例进行进行不完全归纳,发现末尾为0都为False,则可以写出代码:
def isSameAfterReversals(self, num: int) -> bool:
return num%10!=0 or num==0
AC了,我们来看力扣官方题解
方法一:数学
提示 1
一个数字进行两次反转操作不变的充要条件为:在两次反转操作前后数字的位数均不变。
提示 1 解释
首先考虑充分性。如果操作前后位数不变,则反转操作等价于数字对应的十进制字符串的反转操作,而字符串反转两次一定等于本身,因此该数字反转两次也为本身。
其次考虑必要性。对于一个数进行反转操作,它的位数一定不会增加。因此进行两次反转操作后得到的数仍然等于原数,操作过程中必须保证数字位数不变。
思路与算法
根据 提示 1 以及取值范围,我们需要找出两次反转操作前后数字位数均不变的(正)整数。
对于 0,进行两次反转操作后仍然为 0。
考虑任意非零正整数,由于反转操作前后均不保留前导零,因此:
对于第一次反转操作,位数不变的充要条件即为该整数结尾不含 0;
对于第二次反转操作,由于第一次操作前的整数不含前导零,因此第二次操作前的整数结尾也不含 0,第二次操作前后位数不会改变。
综上,非负整数进行两次反转操作不变的充要条件即为:该整数为 0 或该整数结尾不含 0。而后者等价于该数模 10 的余数不为 0。我们按照该条件判断并相应返回结果即可。
class Solution {
public:
bool isSameAfterReversals(int num) {
return num == 0 || num % 10 != 0;
}
};
69. x 的平方根
x 的平方根

秒了
class Solution {
public:
int mySqrt(int x) {
return int(sqrt(x));
}
};
看看题解,噢噢噢噢~ 喵啊
思路1:
牛顿法题解参考
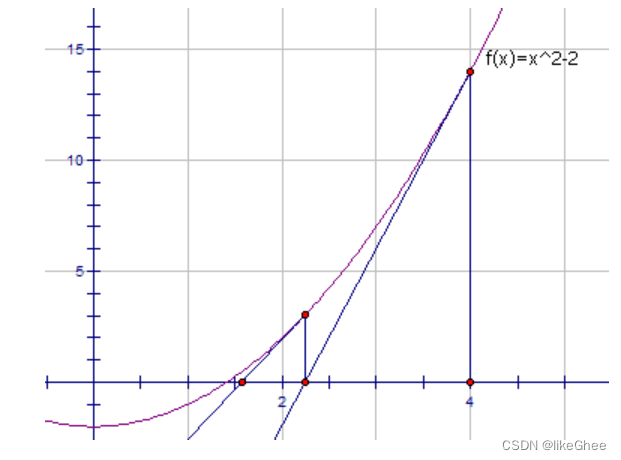
主要思路是使用牛顿迭代法来逐步逼近平方根的值。
令a是要开方的值,x是算数平方根。
我们仅仅是不断用(x, f(x))的切线来逼近方程x2 - a = 0的根。
对于方程 x2 - a = 0 中的根号 a,
首先选择一个初始近似值 x,可以是任意正实数。
根据函数 f(x) = x2 - a 的导数,即 f'(x) = 2x,计算在点 (x, f(x)) 处的切线斜率为 2x。
使用切线斜率来计算一个更接近真实根的近似值,通过以下公式得到新的近似值x := x - f(x)/(2x)。
使用新的近似值x进行迭代。
算法如下:
首先将输入的整数 a 赋值给 long 类型的变量 x,这是为了避免在计算过程中发生溢出。
进入一个循环,条件是 x * x > a,也就是当 x 的平方大于 a 时继续循环。
在循环体内部,每次更新 x 的值为 (x + a / x) / 2。这个更新公式是牛顿迭代法的核心部分,原理上面说过了。
当退出循环后,说明已经找到了一个满足条件的 x,其平方不大于 a。此时,将 x 转换为整数类型并返回作为结果。
public int mySqrt(int a) {
long x = a;
while (x * x > a) x = (x + a / x) / 2;
return (int)x;
}
思路2:
liweiwei1419的二分查找题解
如果这个整数的平方 恰好等于 输入整数,那么我们就找到了这个整数;
如果这个整数的平方 严格大于 输入整数,那么这个整数肯定不是我们要找的那个数;
如果这个整数的平方 严格小于 输入整数,那么这个整数 可能 是我们要找的那个数。
因此我们可以使用「二分查找」来查找这个整数,不断缩小范围去猜。
猜的数平方以后大了就往小了猜;
猜的数平方以后恰恰好等于输入的数就找到了;
猜的数平方以后小了,可能猜的数就是,也可能不是。
很容易知道,题目要我们返回的整数是有范围的,直觉上一个整数的平方根肯定不会超过它自己的一半,但是 0 和 1除外,因此我们可以在 1 到输入整数除以 2 这个范围里查找我们要找的平方根整数。0 单独判断一下就好。
public int mySqrt(int x) {
if (x == 0) {
return 0;
}
if (x <= 3) {
return 1;
}
int l = 1, r = x / 2;
while (l <= r) {
int mid = l + (r - l) / 2;
// 直接定位
if (mid <= x / mid && (mid + 1) > x / (mid + 1)) {
return mid;
} else if (mid > x / mid) {
r = mid - 1;
} else {
l = mid + 1;
}
}
// 不会走到这里的
return 0;
}
70.爬楼梯
简单题~

思考过程:当n=1时,返回1,当n=2时,返回2,当n=3时,返回3,那么当n=4时?
进行归纳:
当 n = 2 时,有两种爬法:一次爬 1 阶,两次爬 2 阶,返回 2。
当 n = 3 时,有三种爬法:1-1-1,1-2,2-1,返回 3。
接下来,我们假设当 n = k 时,有 f(k) 种爬法。
推导递推关系:
假设 n = k + 1,我们可以从 n = k 的情况推导出来:
从第 k 阶爬 1 阶到达第 k + 1 阶,有 f(k) 种爬法。
从第 k - 1 阶爬 2 阶到达第 k + 1 阶,有 f(k-1) 种爬法。
综合上述两种情况,到达第 k + 1 阶的总爬法为 f(k) + f(k-1)。
形成递推关系:
根据上述分析,我们得到递推关系:f(n) = f(n-1) + f(n-2)。
代码1:
dp矩阵
首先,在climbStairs函数中,通过调用dfs函数来计算爬到第 n 级楼梯的不同方法数。为了避免重复计算,使用了一个名为 memo 的数组,用于存储已经计算过的结果。
在dfs函数中,首先检查 i 是否小于等于 1,若满足条件则返回1作为递归边界。否则,声明一个引用类型的变量 res,用于保存记忆化结果。
接下来,检查 res 是否已经被计算过,如果已经计算过则直接返回 res 的值。如果没有计算过,则通过递归调用 dfs 函数计算 i-1 和 i-2 的结果,并将两者相加作为当前楼梯级数 i 的结果。然后将结果赋值给 res,并返回 res。
最后,在 climbStairs 函数中,将 memo 数组的长度设置为 n+1,以便能够存储下标为 n 的结果,并调用 dfs 函数返回最终的结果。
小贴士:int & 是引用类型。在 C++ 中,引用是指针的另一种表现形式,它提供了对已存在的对象的别名。通过引用,我们可以操作引用所指向的对象,就像在操作该对象本身一样。
在代码中,int &res = memo[i]; 表示将 memo[i] 的引用赋值给 res,使得 res 成为 memo[i] 的别名。这样做的目的在于通过修改 res 的值,同时也会修改 memo[i] 的值。引用类型的变量相当于已经存在的变量的别名,不存在空引用,必须初始化为已经存在的对象。
class Solution {
public:
vector<int> memo;
int dfs(int i) {
if (i <= 1) { // 递归边界
return 1;
}
int &res = memo[i]; // 注意这里是引用
if (res) { // 之前计算过
return res;
}
return res = dfs(i - 1) + dfs(i - 2); // 记忆化
}
int climbStairs(int n) {
memo.resize(n + 1); //修改长度
return dfs(n);
}
};
代码2:
滚动数组
声明了三个整数变量:left、right和res。left和right用于存储中间结果,
res初始化为1,表示爬1个台阶有1种方式。
一个for循环从i = 1迭代到i = n,在每次迭代中,更新left、right和res的值。
循环迭代地计算每一步爬楼梯的方式数量,逐步计算出n步的结果。
left被赋值为right的值,表示爬i-1步的方式数量。
right被赋值为res的值,表示爬i-2步的方式数量。
res更新为left和right的和,表示爬i步的总方式数量。
class Solution {
public:
int climbStairs(int n) {
int left = 0;
int right = 0;
int res = 1;
for (int i = 1; i <=n; i++){
left = right;
right = res;
res = left + right;
}
return res;
}
};
1631.最小体力消耗路径

我首先第一个想法应该是dfs,但是图用dfs应该不太行,肯定会超时,那么换个思路用dp
dp的话首先创建二维dp矩阵,一维矩阵是这么创建的 vector<int> dp(t, INT_MAX); ,二维dp矩阵创建:vector<vector<int>> (h, vector<int>(w, INT_MAX));
然后思考
首先是边界条件:rows, columns = 1, 直接返回0就好,rows, columns=100,就是一般情况。
那么我们需要从个例出发归纳dp公式,
dp[i][j] 应该等于什么,dp[i][j] 可以从4个方向(上下左右)来。
又因为,一条路径耗费的 体力值 是路径上相邻格子之间 高度差绝对值 的 最大值 决定的。
所以我们要比较dp[][] 和 height[i][j] - height[][],选max的那个
从上面一格来:dp[i-1][j] vs abs(height[i][j] - height[i-1][j])
从下面一格来:dp[i+1][j] vs abs(height[i][j] - height[i+1][j])
从左面一格来:dp[i][j-1] vs abs(height[i][j] - height[i][j-1])
从右面一格来:dp[i][j+1] vs abs(height[i][j] - height[i-1][j+1])
我们选择cost最小的那个
但是单纯的dp还有个问题,就是没有考虑到所有可能走的路径,因为for循环遍历是从上到下,从左到右遍历,一开始没有考虑到从下到上走的情况。
因此最外层我们还需要一个while(change) 循环,目的是在更新最小体力值的过程中进行迭代,直到不再发生进一步的更改。
这样的循环用于检查矩阵 dp 中的最小体力值是否可以进一步优化。循环会持续进行,直到在迭代过程中不再有更改,这表示矩阵已经达到了一个稳定状态,其中最小体力值已经正确计算,不再需要进一步更新。
每次循环迭代都对整个矩阵进行一次遍历,根据相邻的单元格更新最小体力值。循环会在经过完整的迭代后退出,如果在迭代过程中没有值在 dp 矩阵中发生更改,这意味着算法已经收敛,已确定了每个单元格中的最终最小体力值。
这种方法确保算法考虑了所有可能的路径,并在收敛到矩阵的最终最小体力值时进行必要的更新。
代码1,击败5.20%使用 C++ 的用户…属于是暴力解法了:
int minimumEffortPath(vector<vector<int>>& heights) {
int h = heights.size();
int w = heights[0].size();
if (h == 1 && w == 1) return 0;
vector<vector<int>> dp(h, vector<int>(w, INT_MAX));
bool change = true;
while (change) {
change = false;
for (int i = 0; i < h; i++) {
for (int j = 0; j < w; j++) {
if (i == 0 && j == 0) {
dp[i][j] = 0;
continue;
}
int tmp = dp[i][j];
int up = i - 1 >= 0 ? max(abs(heights[i][j] - heights[i - 1][j]), dp[i - 1][j]) : INT_MAX;
int down = i + 1 < h ? max(abs(heights[i][j] - heights[i + 1][j]), dp[i + 1][j]) : INT_MAX;
int left = j - 1 >= 0 ? max(abs(heights[i][j] - heights[i][j - 1]), dp[i][j - 1]) : INT_MAX;
int right = j + 1 < w ? max(abs(heights[i][j] - heights[i][j + 1]), dp[i][j + 1]) : INT_MAX;
dp[i][j] = min(up, down);
dp[i][j] = min(dp[i][j], left);
dp[i][j] = min(dp[i][j], right);
change = change || tmp != dp[i][j];
}
}
}
return dp[h - 1][w - 1];
}
来看官方题解
前言
我们可以将本题抽象成如下的一个图论模型:
我们将地图中的每一个格子看成图中的一个节点;
我么将两个相邻(左右相邻或者上下相邻)的两个格子对应的节点之间连接一条无向边,边的权值为这两个格子的高度差的绝对值;
我们需要找到一条从左上角到右下角的最短路径,其中一条路径的长度定义为其经过的所有边权的最大值。
由于地图是二维的,我们需要给每个格子对应的节点赋予一个唯一的节点编号。
方法一:二分查找
思路与算法
我们可以将这个问题转化成一个「判定性」问题,即:
是否存在一条从左上角到右下角的路径,其经过的所有边权的最大值不超过 x?
这个判定性问题解决起来并不复杂,我们只要从左上角开始进行深度优先搜索或者广度优先搜索,在搜索的过程中只允许经过边权不超过 x 的边,搜索结束后判断是否能到达右下角即可。
(令 x 是路过的最大值)
随着 x 的增大,原先可以经过的边仍然会被保留,因此如果当 x = x0 时,我们可以从左上角到达右下角,那么当 x > x0 时同样也可以可行的。
因此我们可以使用二分查找的方法,找出满足要求的最小的那个 x 值,记为 xans,那么:
当x < xans 我们无法从左上角到达右下角
当a >= xans,我们可以从左上角到达右下角
由于格子的高度 heights 范围为1,10^6,因此我们可以0,10^6 - 1 的范围内对 进行二分查找。在每一步查找的过程中,我们使用进行深度优先搜索或者广度优先搜索判断是否可以从左上角到达右下角并根据判定结果更新二分查找的左边界或右边界即可。
class Solution {
private:
static constexpr int dirs[4][2] = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
public:
int minimumEffortPath(vector<vector<int>>& heights) {
int m = heights.size();
int n = heights[0].size();
// Binary search for the minimum effort value
int left = 0, right = 999999, ans = 0;
while (left <= right) {
int mid = (left + right) / 2;
// BFS to check if there is a path with effort <= mid
queue<pair<int, int>> q;
q.emplace(0, 0);
vector<int> seen(m * n);
seen[0] = 1;
while (!q.empty()) {
auto [x, y] = q.front();
q.pop();
// Explore neighboring cells
for (int i = 0; i < 4; ++i) {
int nx = x + dirs[i][0];
int ny = y + dirs[i][1];
// Check if the neighboring cell is within bounds,
// has not been visited, and has effort <= mid
if (nx >= 0 && nx < m && ny >= 0 && ny < n &&
!seen[nx * n + ny] && abs(heights[x][y] - heights[nx][ny]) <= mid) {
q.emplace(nx, ny);
seen[nx * n + ny] = 1; // Mark the cell as visited
}
}
}
// If there is a path to the destination, update the answer
if (seen[m * n - 1]) {
ans = mid;
right = mid - 1; // Look for smaller effort values
} else {
left = mid + 1; // Look for larger effort values
}
}
return ans;
}
};
复杂度分析:
时间复杂度:O(mnlogC),其中m 和n 分别是地图的行数和列数,C是格子的最大高度,在本题中C不超过10^6。我们需要进行O(logC)次二分查找。
每一步查找的过程中需要使用广度优先搜索,在O(mn)的时间判断是否可以从左上角到达右下角,因此总时间复杂度为O(mn log C)。
空间复杂度:O(mn),即为广度优先搜索中使用的队列需要的空间。
记好一些模板, 这是常用头和表达式
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
static constexpr int dirs[4][2] = { {-1, 0} ,{1, 0} ,{0, -1} ,{0, 1} };
BFS模板,广度搜索一遍图
// 初始化队列和visited矩阵
queue <pair<int, int>> q;
vector<int> seen(m * n);
// 初始化第一个元素
q.emplace(0, 0);
seen[0] = 1;
// 直到队列为空
while (!q.empty()) {
// 获取并弹出第一个元素
pair<int, int>ele = q.front();
int x = ele.first;
int y = ele.second;
q.pop();
// 访问邻居,并将节点加入队列,更新visited矩阵
for (int i = 0; i < 4; ++i) {
int nx = x + dirs[i][0];
int ny = y + dirs[i][1];
// check if neighboring cell is within bounds,
// has not been visted, and has effort <= mid
if (nx >= 0 && nx < m && ny >= 0 && ny < n &&
!seen[nx * n + ny] && abs(heights[x][y] - heights[nx][ny]) <= mid){
q.emplace(nx, ny);
seen[nx * n + ny] = 1; // mark the cell as visted
}
}
}
二分查找框架
int left = 0, right = 999999, ans = 0;
// binary search
while (left <= right) {
int mid = (left + right) / 2;
// If there is a path to the destination, update the answer
if (seen[m * n - 1]) {
ans = mid;
right = mid - 1; // Look for smaller effort values
}
else {
left = mid + 1; // Look for larger effort values
}
}
代码3:
最短路思路
从算法「最短路径」得到启发,使得我们很容易想到求解最短路径的Dijkstra算法,然而本题中对于「最短路径」的定义不是其经过的所有边权的和,而是其经过的所有边权的最大值,那么我们还可以用Dijkstra算法进行求解吗?
答案是可以的。Dijkstra算法本质上是一种启发式搜索算法,它是A*算法在启发函数h=O时的特殊情况。
读者可以参考 A* search algorithm,Consistent heuristic,Admissible heuristic 深入了解 Dijkstra 算法的本质。下面给出Dijkstra算法的可行性证明,需要读者对A*算法以及其可行性条件有一定的掌握。
证明:
定义加法运算
a
⊕
b
=
max
?
(
a
,
b
)
a\oplus b=\max(a,b)
a⊕b=max(a,b) ,显然
⊕
\oplus
⊕ 满足交换律和结合律。那么如果一条路径上的边权分别为
e
0
,
e
1
,
?
?
,
e
k
e_0,e_1,\cdots,e_k
e0?,e1?,?,ek?,那么
e
0
⊕
e
1
⊕
?
⊕
e
k
e_0\oplus e_1\oplus\cdots\oplus e_k
e0?⊕e1?⊕?⊕ek? 即为这条路径的长度。
在 Dijkstra 算法中
h
≡
0
h\equiv0
h≡0 ,对于图中任意的无向边
x
?
y
x\mapsto y
x?y,由于
e
x
,
y
≥
0
e_{x,y}\geq0
ex,y?≥0 ,那么
h
(
x
)
=
0
≤
h(x)=0\leq
h(x)=0≤
e
x
,
y
⊕
h
(
y
)
e_{x,y}\oplus h(y)
ex,y?⊕h(y) 恒成立,其中
e
x
,
y
e_{x,y}
ex,y? 表示边权。因此启发函数
h
h
h 和加法运算
⊕
\oplus
⊕ 满足三角不等式,是consistent heuristic 的,可以使用 Dijkstra 算法求出最短路径。
A*(A-star)搜索算法是一种用于解决图或图形中路径规划问题的启发式搜索算法。它是一种通用算法,常用于人工智能和计算机科学领域,尤其是在游戏开发和机器人路径规划中。
A*算法结合了广度优先搜索和最佳优先搜索的特性,以有效地找到从起点到目标点的最短路径。该算法使用两个主要函数来评估每个可能的路径段的优劣:
-
启发函数(Heuristic Function): 用于估计从当前节点到目标节点的距离。这是A*算法的关键部分,因为它帮助算法在搜索中更有方向性,更快找到解决方案。
-
代价函数(Cost Function): 用于测量从起点到当前节点的代价。这通常是实际已经走过的路径长度。
A*算法使用这两个函数来计算一个估计值,即当前节点的总代价。该算法通过按总代价的递增顺序扩展节点,逐步搜索解空间直到找到解决方案为止。在搜索的过程中,A*会维护一个开放列表,其中包含待考虑的节点,并根据它们的总代价进行排序。
A*算法的优势在于它在启发式引导下,以一种高效的方式找到最短路径。然而,选择合适的启发式函数对算法性能至关重要。 A*算法的时间复杂度和空间复杂度在实践中通常表现得相当好。
A*算法补充说明:
启发式搜索(Heuristic Search)是一种搜索算法,它利用与问题相关的启发式信息以提高搜索效率和减少搜索次数。这些启发式信息通常通过定义一个估价函数(heuristic function)h(x) 来表示,该函数估计了当前状态 x 到目标状态的距离。
具体而言:
-
估价函数 h(x):
- h(x) 表示当前状态 x 到目标状态的估计距离。
- h(x) ≥ 0, h(x) 越小表示状态 x 越接近目标状态,当 h(x) = 0 时,说明已经达到目标状态。
-
启发式搜索的实现:
- 使用估价函数 h(x) 和实际代价函数 g(x)。在搜索过程中,通过计算 f(x) = g(x) + h(x) 来确定节点的优先级,其中 f(x) 越小表示优先级越高。
- 当 f(x) = g(x) 时,等价于等代价搜索,例如广度优先搜索。
- 当 f(x) = h(x) 时,类似贪婪优先搜索,每次选择最接近目标的节点。
- A*算法是启发式搜索的一种改进版本,通过综合考虑实际代价 g(x) 和启发式估计 h(x),以 f(x) = g(x) + h(x) 的方式选择节点(优先队列实现)进行搜索。
-
A*算法的特点:
- A*算法在估价函数满足一定条件时能找到最优解。
- 估价函数 h(x) 应满足 h(x) ≤ h*(x),其中 h*(x) 是从当前状态到目标状态的实际代价。
- 当 h(x) 较接近 h*(x) 时,A*算法能够在搜索中更有方向性,扩展的节点数量相对较少。
-
选择估价函数的重要性:
- 不同的估价函数可能对算法的效率产生重大影响。
- 合理选择 h(x) 能够提高搜索效率,但不同问题可能需要不同的估价函数。
- 例如,在八数码问题中,可以选择曼哈顿距离之和作为 h(x)。
通俗易懂来说,与BFS算法不同的是A*算法每一轮循环不会探索所有的边界方块,而会选择当前代价最低的方块进行探索。
代价可以分为,当前代价(f-cost),比如从起点出发一共走过多少个格子;另一部分代价就是预估代价(g-cost),表示当前方块到终点方块大概需要多少步。
最常用的预估代价有欧拉距离,更容易计算的曼哈顿距离(竖直和水平方向上的距离和)。
我们优先搜索总代价较低的方块进行探索。
参考资料:https://www.redblobgames.com/pathfinding/a-star/introduction.html
def a_star_search(graph, start, goal):
frontier = PriorityQueue() # 优先队列,用于存储待考虑的节点
frontier.put(start, 0) # 将起点放入队列,并设置优先级为0
came_from = {} # 记录节点的父节点,用于回溯路径
cost_so_far = {} # 记录从起点到当前节点的实际代价
came_from[start] = None # 起点没有父节点
cost_so_far[start] = 0 # 起点到起点的实际代价为0
while not frontier.empty():
current = frontier.get() # 从优先队列中取出优先级最高的节点
if current == goal:
break # 如果当前节点是目标节点,则停止搜索
for next_node in graph.neighbors(current):
new_cost = cost_so_far[current] + graph.cost(current, next_node)
if next_node not in cost_so_far or new_cost < cost_so_far[next_node]:
cost_so_far[next_node] = new_cost
priority = new_cost + heuristic(goal, next_node) # heuristic启发式函数,估计从当前节点到目标节点的代价
frontier.put(next_node, priority)
came_from[next_node] = current
return came_from, cost_so_far
代码3:
下面的 C++ 代码实现了在矩阵中寻找从左上角到右下角的最短路径,其中路径的代价是经过的所有边的权重的最大值。
-
Lambda 表达式
tupleCmp:- 这是一个用于比较元组的 Lambda 表达式,它接受两个元组参数,比较它们的第三个元素(
d1和d2),返回比较结果。 - 该 Lambda 表达式的目的是定义优先队列中元组的排序规则,按照元组中第三个元素
d的降序排列。
- 这是一个用于比较元组的 Lambda 表达式,它接受两个元组参数,比较它们的第三个元素(
-
优先队列
q:- 声明一个优先队列,元素类型为
tuple<int, int, int>,每个元组包含三个整数值。 - 底层容器选择
vector<tuple<int, int, int>>。 - 使用 Lambda 表达式
tupleCmp作为比较器,根据元组的第三个整数值降序排列。
- 声明一个优先队列,元素类型为
-
初始化队列:
- 将起点
(0, 0)插入队列,代价为0。
- 将起点
-
距离和已访问数组:
- 初始化一个数组
dist用于存储每个节点的到达代价,初始值为INT_MAX。 - 初始化一个数组
seen用于记录节点是否已被访问,初始值为0。
- 初始化一个数组
-
A*搜索主循环:
- 在主循环中,不断从优先队列中取出代价最小的节点。
- 对于当前节点
(x, y, d),更新到达当前节点的代价dist[x * n + y]。 - 标记当前节点为已访问,并遍历其四个相邻的节点。
- 如果相邻节点合法,且通过当前节点到达相邻节点的代价小于目前记录的代价,则更新代价,并将相邻节点加入队列。
-
返回结果:
- 当队列为空或者达到右下角节点时,返回起点到右下角节点的最大代价,即路径中边的最大权重。
#include <iostream>
#include <vector>
#include <queue>
#include <tuple>
using namespace std;
int minimumEffortPath(vector<vector<int>>& heights) {
static constexpr int dirs[4][2] = { {-1,0},{1,0},{0, -1},{0, 1} };
int m = heights.size();
int n = heights[0].size();
// 这是一个 Lambda 表达式,它定义了一个名为 `tupleCmp` 的自动推断函数对象。
// 该函数对象接受两个参数 `e1` 和 `e2`,这两个参数可以是任意类型。
// 在 Lambda 表达式的函数体内,使用了结构化绑定(structured binding)的方式
// 将参数 `e1` 和 `e2` 解构为各自的成员变量 `x1`, `y1`, `d1` 和 `x2`, `y2`, `d2`。
// 接下来,Lambda 表达式返回 `d1 > d2` 的比较结果。
// 这意味着,当 `d1` 大于 `d2` 时,返回 `true`,否则返回 `false`。
// 这个 Lambda 表达式的功能是根据元组中的第三个元素 `d` 进行降序排列
// Lambda 表达式可以在需要函数对象的地方使用,例如在排序算法或容器的比较函数中。
auto tupleCmp = [](const auto& e1, const auto& e2) {
auto&& [x1, y1, d1] = e1;
auto&& [x2, y2, d2] = e2;
return d1 > d2;
};
// 这是一个使用了自定义比较函数 `tupleCmp` 的优先队列(`priority_queue`)的示例。
// 首先,声明了一个优先队列 `q`,其元素类型为 `tuple<int, int, int > `。
// 优先队列中的元素是元组类型,每个元组包含三个整数值。
// 第二个模板参数 `vector<tuple<int, int, int >> ` 指定了底层容器的类型,
// 即存储队列元素的容器类型,这里使用了 `vector`。
// 第三个参数 `decltype(tupleCmp)` 指定了比较器类型,
// 它由 Lambda 表达式 `tupleCmp` 的类型推断而来。
// 该比较器用于定义优先队列中元素的排序规则。
// 最后,通过将比较器 `tupleCmp` 作为参数传递给优先队列的构造函数,
// 创建了一个基于 `tupleCmp` 的优先队列 `q`。
// 这个优先队列 `q` 根据元组中的第三个整数值进行比较,
// 并且在插入和弹出元素时保持队列的有序状态。
// 比较器 `tupleCmp` 定义了元素的排序规则,所以优先队列将按照 `d` 的降序进行排列。
priority_queue<tuple<int, int, int>, vector<tuple<int, int, int>>, decltype(tupleCmp)> q(tupleCmp);
q.emplace(0, 0, 0);
vector<int> dist(m * n, INT_MAX);
dist[0] = 0;
vector<int> seen(m * n);
while (!q.empty()) {
auto [x, y, d] = q.top();
q.pop();
int id = x * n + y;
if (seen[id]) continue;
if (x == m - 1 && y == n - 1) break;
seen[id] = 1;
for (int i = 0; i < 4; ++i) {
int nx = x + dirs[i][0];
int ny = y + dirs[i][1];
if (nx >= 0 &&
nx < m &&
ny >= 0 &&
ny < n &&
max(d, abs(heights[x][y] - heights[nx][ny])) < dist[nx * n + ny])
{
dist[nx * n + ny] = max(d, abs(heights[x][y] - heights[nx][ny]));
q.emplace(nx, ny, dist[nx * n + ny]);
}
}
}
return dist[m * n - 1];
}
auto tupleCmp = [](const auto& e1, const auto& e2) {
auto&& [x1, y1, d1] = e1;
auto&& [x2, y2, d2] = e2;
return d1 > d2;
};
这是一个 Lambda 表达式,它定义了一个名为 tupleCmp 的自动推断函数对象。
该函数对象接受两个参数 e1 和 e2,这两个参数可以是任意类型。
在 Lambda 表达式的函数体内,使用了结构化绑定(structured binding)的方式
将参数 e1 和 e2 解构为各自的成员变量 x1, y1, d1 和 x2, y2, d2。
接下来,Lambda 表达式返回 d1 > d2 的比较结果。
这意味着,当 d1 大于 d2 时,返回 true,否则返回 false。
这个 Lambda 表达式的功能是根据元组中的第三个元素 d 进行降序排列
Lambda 表达式可以在需要函数对象的地方使用,例如在排序算法或容器的比较函数中。
priority_queue<tuple<int, int, int>, vector<tuple<int, int, int>>, decltype(tupleCmp)> q(tupleCmp);
这是一个使用了自定义比较函数 tupleCmp 的优先队列(priority_queue)的示例。
首先,声明了一个优先队列 q,其元素类型为 tuple<int, int, int > 。
优先队列中的元素是元组类型,每个元组包含三个整数值。
第二个模板参数 vector<tuple<int, int, int >> 指定了底层容器的类型,
即存储队列元素的容器类型,这里使用了 vector。
第三个参数 decltype(tupleCmp) 指定了比较器类型,
它由 Lambda 表达式 tupleCmp 的类型推断而来。
该比较器用于定义优先队列中元素的排序规则。
最后,通过将比较器 tupleCmp 作为参数传递给优先队列的构造函数,
创建了一个基于 tupleCmp 的优先队列 q。
这个优先队列 q 根据元组中的第三个整数值进行比较,
并且在插入和弹出元素时保持队列的有序状态。
比较器 tupleCmp 定义了元素的排序规则,所以优先队列将按照 d 的降序进行排列。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!