[SpliceViT]Splicing ViT Features for Semantic Appearance Transfer
paper:https://arxiv.org/pdf/2201.00424v1.pdf
Abstract
goal:generate an image in which objects in a source structure image are “painted” with the visual appearance of their semantically related objects in a target appearance image.(生成一个图像,其中源结构图像中的对象被“绘制”为目标外观图像中与其语义相关的对象的视觉外观。)
method:train a generator
key idea:to leverage a pre-trained and fixed Vision Transformer(ViT) model which serves as an external semantic prior.(利用预先训练的固定视觉转换器(ViT)模型作为外部语义先验。)
Introduction
从 DINO-ViT 得出的结论:
(i) the global token (a.k.a [CLS] token) provides a powerful representation of visual appearance, which captures not only texture information but more global information such as object parts(CLS token 可以学习到①纹理信息;②全局信息)
(ii) the original image can be reconstructed from these features, yet they provide powerful semantic information at high spatial granularity.(源图像可以通过这些特征进行重建)
-->
使用 CLS token,表示外观信息;
使用 key之间的自相似性,表示结构信息;
(都是从最后一层提取出来的)
使用 structure/appearance image 来训练一个generator。
Method

structure:self-similarity of keys in the deepst attention module (Self-Sim)
appearance:[CLS] token in the deepst layer
键的自相似性:
在键的表示中存在某种重复或相似的结构。最深的注意力模块可能包含多个层次(深度),在这些不同深度的注意力模块中,键的表示可能呈现出某种相似的结构或模式。
包含两个 Loss:
Lapp,encourages the deep appearance of Io and It to match,
Lstructure,encourages the deep structure representation of Io and Is to match.
ViT-overview

the set of tokens pass through L Transformer layers
在每个自注意力模块,tokens都会:
![]()
在最后一层之后,[CLS] token 会再次经过一个 MLP(即上图左上角),输出一组标签的输出分布,这样他就可以用来进行图像分类等任务。
DINO-ViT,训练目标:同一图像的两个不同增强视图,产生相同的概率分布。这意味着模型被要求学会捕捉图像的共性特征,而不仅仅是单一视图的特定特征。
DINO-ViT的学习到的视觉表示被认为比有监督的ViT更为强大。所以使用 DINO-ViT
Structure & Appearance in ViT’s Feature Space
风格信息,[CLS] token
结构信息,(希望保持空间布局、形状、和对象的语义及周围)。使用从 DINO-ViT 提取出来的空间特征,用它们的 self-similarity 来作为结构信息。

cos-sim,是 keys 之间的余弦相似度。
自相似性描述符的维度就变成:![]()
公式描述了一个用于计算图像 I?中两个位置 i 和 j 的特征表示 k 的余弦相似度的过程
,矩阵S的元素,表示位置 i 和 j 处的相似度;
, 分别表示图像 I 位置 i 和 j 处的特征表示;
,表示向量a和向量b之间的余弦相似度;(余弦相似度是衡量两个向量方向相似程度的指标。-1~1,1代表完全相似,-1代表完全不相似)
整个公式的含义:
在第 L 层(可能是深度学习模型中的某一层),通过计算图像 I 中不同位置 i?和 j 处的特征表示的余弦相似度,来度量它们之间的相似性。这可以用于表征图像中不同位置之间的关系或相互影响。
Understanding and visualizing DINO-ViT’s features
采用“feature-inversion”方法:给定一张图片,提取目标特征,并对具有相同特征的图像进行优化。
![]()
,表示对参数 θ 进行优化,找到能够最小化目标函数的参数值;
,使用参数θ的卷积神经网络CNN 来处理输入 z,得到一个特征表示;
,图像 Image 的特征表示;
,Frobenius范数;
整个公式的含义:
通过调整卷积神经网络?
,使得它与目的特征?
一、首先考虑反演 [CLS] token:
![]()

发现:
从浅层->深层,较早的层主要捕获局部纹理信息,在较深的层,则可以捕获更多的全局信息;
二、反演从最后一层提取出的 spatial keys
![]()

发现:
可以从这些表示中重建图像。
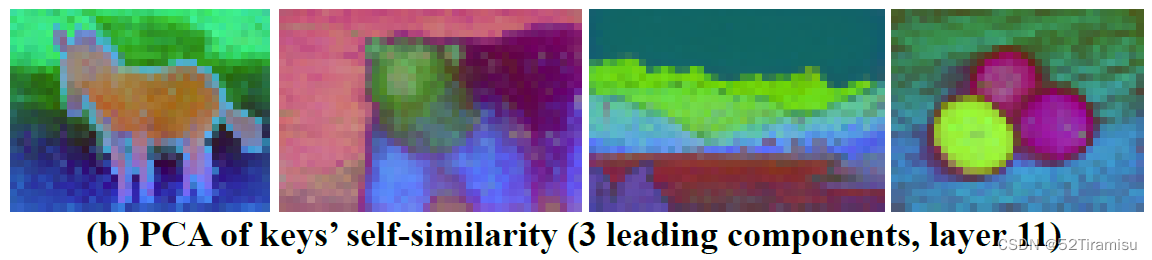
除掉外观信息之后,在 keys 的自相似性 PCA可视化发现,自相似性主要捕获对象的结构,以及它们不同的语义组成部分。
Splicing ViT features
总体Loss:
![]()
Appearance Loss:

Structure Loss:
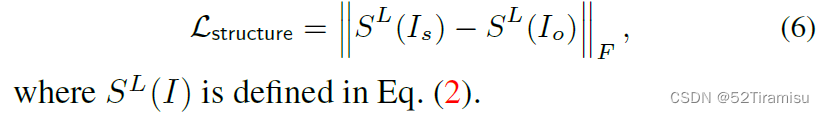
Identity Loss:

KL(It?) 表示输入图像 It?在某一层 L?的特征表示
公式含义:
最小化 风格图像在L层的特征,与 生成图像在L层的特征表示 的?Frobenius范数。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!