ML Design Patterns——Useful Overfitting


Model Training Patterns
There are several common training patterns in machine learning and deep learning models. Some of these include:
- Batch Training: In batch training, the model is trained on a fixed batch of data at a time. The parameters of the model are updated after evaluating the gradients for each batch. This approach is efficient when training large datasets.
- Mini-Batch Training: Mini-batch training is similar to batch training but uses a smaller batch size. Instead of considering the entire dataset, only a subset of data is used to estimate the gradients. This helps in reducing the memory requirement and speeds up the training process.
- Stochastic Training: In stochastic training, the model randomly selects a single data instance to compute the gradients and updates the parameters accordingly. This approach is useful when the dataset is large and computational resources are limited. However, due to the random selection of data, it may result in noisy gradients.
- Online Training: Online training involves updating the model parameters after every individual data instance. This pattern is useful when the dataset is continuously growing or changing. It allows the model to adapt to new data in real-time.
- Transfer Learning: Transfer learning is a training pattern where a pre-trained model is used as a starting point for a new task. The pre-trained model is then fine-tuned using a smaller dataset specific to the new task. This approach helps in leveraging the knowledge learned from a related task and saves time and computational resources.
- Reinforcement Learning (RL): RL involves training a model through trial and error in an interactive environment. The model learns through exploration and receives feedback in the form of rewards or penalties. Reinforcement learning patterns include Q-Learning, Deep Q-Networks (DQN), and Proximal Policy Optimization (PPO), among others.
These training patterns can be combined and customized based on the specific requirements of the problem and the available resources. The choice of training pattern can have a significant impact on the model’s performance, convergence speed, and generalization capabilities.
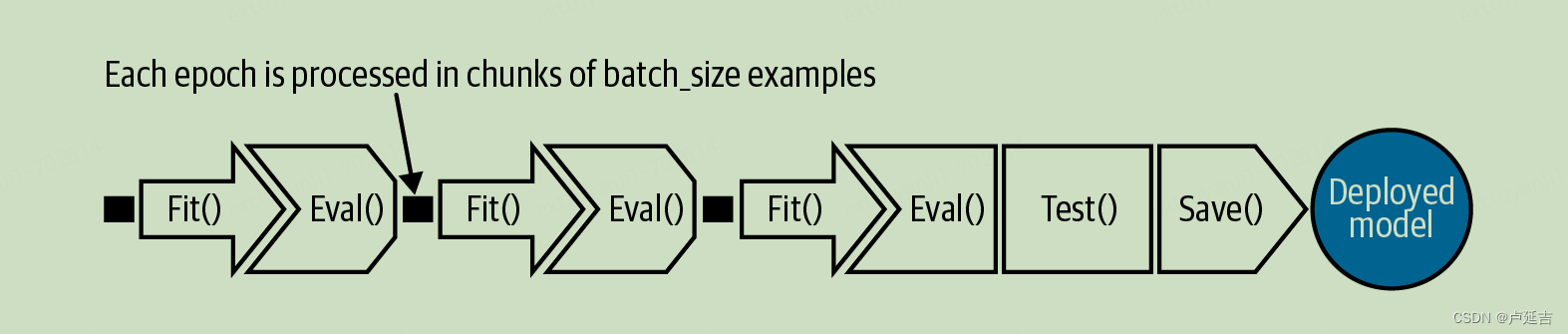
Typical Training Loop
The typical training loop in a machine learning (ML) task involves the following steps:
- Data collection: Acquire a labeled dataset that contains examples of input data paired with the desired output or target values. This dataset will be used to train the ML model.
- Data preprocessing: Clean and preprocess the dataset by removing noise, handling missing values, scaling features, and transforming the data into a suitable format for training the ML model.
- Model selection: Choose an appropriate ML model or algorithm depending on the nature of the task. There are various types of ML models such as linear regression, decision trees, neural networks, support vector machines, etc.
- Model initialization: Initialize the model with random or pre-defined weights and biases.
- Training the model: In this step, the ML model is trained on the preprocessed data to learn the underlying patterns and relationships. The model iteratively adjusts its internal parameters to minimize the difference between its predicted output and the actual target values.
- Evaluation: After the model is trained, evaluate its performance on a separate validation or test dataset. Compute metrics such as accuracy, precision, recall, F1 score, or mean squared error to assess how well the model performs on unseen data.
- Hyperparameter tuning: Optimize the hyperparameters of the ML model to improve its performance. Hyperparameters include parameters that are not learned from the data but affect the model’s behavior, such as learning rate, batch size, number of epochs, regularization constants, etc.
- Testing: Once the model is trained and tuned, it is ready for deployment. Use the trained model to make predictions on new, unseen data and evaluate its performance. This step helps determine if the model is able to generalize well to new data.
- Iteration: Iterate on the previous steps as needed, refining the model architecture, adjusting hyperparameters, or collecting more data, to improve the model’s performance and achieve the desired accuracy or predictive power.
- Deployment: After the model has been fully trained and tested, it can be deployed to make predictions on new, real-world data. This involves integrating the model into an application or system where it can receive input, process it, and provide the desired output.
The typical training loop in a machine learning (ML) task involves the following steps:
- Data collection: Acquire a labeled dataset that contains examples of input data paired with the desired output or target values. This dataset will be used to train the ML model.
- Data preprocessing: Clean and preprocess the dataset by removing noise, handling missing values, scaling features, and transforming the data into a suitable format for training the ML model.
- Model selection: Choose an appropriate ML model or algorithm depending on the nature of the task. There are various types of ML models such as linear regression, decision trees, neural networks, support vector machines, etc.
- Model initialization: Initialize the model with random or pre-defined weights and biases.
- Training the model: In this step, the ML model is trained on the preprocessed data to learn the underlying patterns and relationships. The model iteratively adjusts its internal parameters to minimize the difference between its predicted output and the actual target values.
- Evaluation: After the model is trained, evaluate its performance on a separate validation or test dataset. Compute metrics such as accuracy, precision, recall, F1 score, or mean squared error to assess how well the model performs on unseen data.
- Hyperparameter tuning: Optimize the hyperparameters of the ML model to improve its performance. Hyperparameters include parameters that are not learned from the data but affect the model’s behavior, such as learning rate, batch size, number of epochs, regularization constants, etc.
- Testing: Once the model is trained and tuned, it is ready for deployment. Use the trained model to make predictions on new, unseen data and evaluate its performance. This step helps determine if the model is able to generalize well to new data.
- Iteration: Iterate on the previous steps as needed, refining the model architecture, adjusting hyperparameters, or collecting more data, to improve the model’s performance and achieve the desired accuracy or predictive power.
- Deployment: After the model has been fully trained and tested, it can be deployed to make predictions on new, real-world data. This involves integrating the model into an application or system where it can receive input, process it, and provide the desired output.
Useful Overfitting
Introduction: In machine learning (ML), it is critical to strike a balance between capturing intricate patterns in data and avoiding overfitting. Overfitting occurs when a model learns to perform exceptionally well on training data but fails to generalize to unseen data. While overfitting is generally perceived as a drawback, there are scenarios where overfitting can be surprisingly useful.
Understanding Overfitting: Overfitting refers to a situation in which a machine learning model becomes too complex and starts to learn the idiosyncrasies and noise of the training data, rather than the underlying patterns. As a result, the model’s performance on the training data tends to be exceptional, but it performs poorly on new, unseen data.
Drawbacks of Overfitting: Overfitting is generally considered undesirable because it compromises the model’s ability to generalize to real-world scenarios. In practice, overfitting can lead to poor performance, inaccurate predictions, and unreliable results. To combat overfitting, various techniques such as regularization, cross-validation, and early stopping are commonly employed.
Useful Overfitting: Although overfitting is often seen as a problem, there are instances where overfitting can be usefully leveraged. Let’s explore two scenarios where overfitting can provide valuable insights and solutions.
- Feature Engineering and Hypothesis Generation: Overfitting can serve as a powerful tool for exploring and generating hypotheses in feature engineering. By intentionally overfitting a model, we can observe which features or transformations yield the best results. This allows us to identify potentially significant variables or data manipulations that might not have been initially considered. Once these features are identified, the model can be refined and regularized to reduce overfitting and improve generalization.
- Anomaly Detection: Overfitting can play a crucial role in detecting anomalies, which are usually rare events or outliers in the data. By allowing the model to overfit, it can learn and identify subtle patterns or irregularities that may indicate an anomaly. Once these patterns are discovered, the model can be tuned and retrained with regularization techniques to avoid overfitting while retaining the ability to catch anomalies effectively.
Best Practices for Leveraging Overfitting: While there are cases where overfitting can be useful, it is crucial to exercise caution and follow best practices. Here are a few tips:
- Clearly define the objective: Ensure that the overfitting is purposeful and aligned with the specific goal or hypothesis you are trying to investigate.
- Use validation sets: Separate a portion of your dataset as a validation set to evaluate the overfitting’s usefulness. Test the model on unseen data to assess its generalization ability.
- Regularization techniques: Once the insights are obtained through overfitting, apply appropriate regularization techniques to reduce overfitting and improve generalization.
Conclusion: Overfitting is generally seen as a drawback in machine learning, but it can be a powerful tool when used deliberately and with caution. By intentionally allowing a model to overfit, we can gain valuable insights, explore potential features that were overlooked, and improve anomaly detection capabilities. However, it is vital to exercise caution, validate the results on unseen data, and employ regularization techniques to strike a balance between capturing patterns and avoiding overfitting.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!