用通俗易懂的方式讲解大模型:在 CPU 服务器上部署 ChatGLM3-6B 模型
大语言模型(LLM)的量化技术可以大大降低 LLM 部署所需的计算资源,模型量化后可以将 LLM 的显存使用量降低数倍,甚至可以将 LLM 转换为完全无需显存的模型,这对于 LLM 的推广使用来说是非常有吸引力的。
本文将介绍如何量化 ChatGLM3-6B 模型的 GGML 版本,并介绍如何在 Colab 的 CPU 服务器上部署量化后的模型,让大家在了解如何量化模型的同时也熟悉 Colab 的操作。
通俗易懂讲解大模型系列
技术交流
建了大模型技术交流群! 想要学习、技术交流、获取如下原版资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流

术语介绍
在开始实际操作之前,我们需要了解这次操作中涉及到的工具和术语的含义,这样才能更好的理解后面的内容。
Colab
Colab[1] 是由 Google 提供的一种免费的云端 Jupyter 笔记本服务。它允许用户在云端运行和共享 Python 代码,而无需进行任何设置或配置。它的一个最大的优势是可以免费试用 Google 的服务器,免费用户可以使用 CPU 服务器和 T4 GPU 服务器,而付费用户可以使用 TPU 服务器和 A100、V100 等 GPU 服务器。
ChatGLM3-6B
ChatGLM3-6B 是智源研究院(智谱 AI)和清华大学知识工程实验室联合开发的最新一代对话预训练模型。这个模型在保留了前两代模型的流畅对话和低部署门槛等优秀特性的基础上,引入了工具调用、代码解释器等新功能。更多细节可以参考我之前的文章 ChatGLM3-6B 部署指南、ChatGLM3-6B 功能原理解析。
GGML
GGML[4] 是一个 LLM 量化的工具库,也是量化文件的一种格式,量化的 LLM 不仅在容量上大幅降低(ChatGLM3-6B 从 12G 降低到 3.5G),而且可以直接在纯 CPU 的服务器上运行。
chatglm.cpp 介绍
我们将使用chatglm.cpp[6]这个工具来进行模型量化,它是基于GGML[4]库实现的量化工具,除了可以量化 ChatGLM 系列的 LLM 外,还支持其他比如 BaiChuan、CodeGeeX、InternLM 等 LLM 的量化。
chatglm.cpp 除了提供量化功能外,还提供了多种运行量化模型的方式,包括源码编译运行、Python 代码运行、 Web 服务和 API 服务等,这些运行方式可以让我们在不同的场景下使用量化后的模型。
量化 ChatGLM3-6B 模型
首先我们在 Colab 上新建一个 Jupyter 笔记本,然后将笔记本连接上一个运行时服务器,量化时因为需要用到比较大的内存(大概 15G),而 Colab 给免费用户提供的服务器内存只有 12G,所以我们需要使用付费用户的服务器。所幸 Colab 的付费价格并不高,可以选择 9.99 美元 100 个计算单元的计费模式,也可以选择每月 9.99 美元的 Pro 模式。升级为付费模式后,我们就选择大内存服务器了。这里我们选择大内存的 CPU 服务器,本文的所有操作都只需在 CPU 服务器上运行,所以选择 CPU 服务器即可。
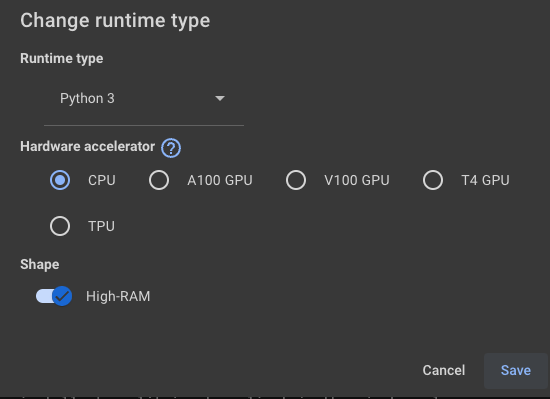
然后就可以在 Jupyter 笔记本中编写代码了,我们先下载 ChatGLM3-6B 的模型,在 Colab 上下载 Huggingface 的资源非常快,基本几分钟就可以下载完成。
git clone https://huggingface.co/THUDM/chatglm3-6b
下载后的模型会保存在/content这个路径下,然后再下载 chatglm.cpp 项目的代码,在使用git clone命令时需要加上--recursive参数来保证下载的代码中包含子模块。
git clone --recursive https://github.com/li-plus/chatglm.cpp.git
下载后的 chatglm.cpp 同样会保存在/content路径下,接着我们需要安装一些项目所需的依赖,这里我们使用pip来安装。
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece
然后就可以执行我们的量化命令了,这里我们使用covert.py脚本来进行量化,执行命令如下:
python3 chatglm.cpp/chatglm_cpp/convert.py -i /content/chatglm3-6b -t q4_0 -o chatglm-ggml.bin
这里我们使用q4_0这个量化类型来进行量化,其他的量化类型可以参考 chatglm.cpp 的文档,量化完成后会在/content路径下生成一个chatglm-ggml.bin文件,这个文件就是量化后的模型文件。
可以看到量化后的模型文件大小为 3.5G,而原来的模型文件大小为 12G,因为我们是q4_0的量化方式,因此量化后的模型大小约为原模型大小的 1/4,大大降低了模型的容量。
保存量化模型到 Google Drive
我们可以将量化模型保存到 Google Drive,这样以后如果重启服务器就无需再执行以上步骤,直接从 Google Drive 读取量化模型即可。
首先我们需要在笔记本中挂载 Google Drive,命令如下:
from google.colab import drive
drive.mount('/content/gdrive')
执行命令后会弹出 Google Drive 的授权页面,选择允许即可,挂载成功后,我们就可以看到 Google Drive 的挂载目录/content/gdrive/MyDrive,然后将量化后的模型文件保存到 Google Drive 中,命令如下:
cp chatglm-ggml.bin /content/gdrive/MyDrive/chatglm-ggml.bin
以后如果重启服务器,我们只要挂载 Google Drive,然后就可以直接引用其中的模型文件了。
上传量化模型到 Huggingface
我们也可以将量化模型上传到 Huggingface,这样可以方便在其他服务器上进行部署。上传文件到 Huggingface 需要新建一个模型仓库,然后通过以下代码进行文件上传:
from huggingface_hub import login, HfApi
login()
api = HfApi()
api.upload_file(
path_or_fileobj="/content/chatglm-ggml.bin",
path_in_repo="chatglm-ggml.bin",
repo_id="username/chatglm3-6b-ggml",
repo_type="model",
)
-
path_or_fileobj参数是量化模型的本地路径 -
path_in_repo参数是上传到 Huggingface 仓库中的路径 -
repo_id参数是 Huggingface 仓库的 ID,格式为username/repo-name -
repo_type参数是 Huggingface 仓库的类型,这里是model
注意在代码执行过程中需要我们输入 Huggingface 账户的 Access Token,这个 Token 需要是有写入权限的 Token,不能是只读的 Token。
GGUF
了解过 GGML 量化的朋友可能会问,chatglm.cpp 支持 GGUF 格式吗?因为据 GGML 的官方介绍,以后的量化格式会慢慢从 GGML 过渡为 GGUF 格式,因为 GGUF 格式能更保存模型更多的额外信息,但 chatglm.cpp 因为 ChatGLM 模型架构的关系,目前还不支持 GGUF 格式[8]。
源码编译运行量化模型
我们得到量化的模型后,可以运行模型来验证一下模型是否正常,chatglm.cpp 提供了多种运行模型的方式,这里我们先介绍源码编译运行的方式。
首先编译 chatglm.cpp 的运行命令:
cd chatglm.cpp && cmake -B build && cmake --build build -j --config Release
编译完成后在 chatglm.cpp 目录下会生成一个build目录,编译完成后的命令就放在这个目录下,然后我们就可以运行模型了,运行命令如下:
chatglm.cpp/build/bin/main -m chatglm-ggml.bin -p "你好"
# 结果显示
你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。
上面的命令中,-m参数带上量化模型的地址,-p参数是输入的提示词,然后我们可以看到 LLM 的输出结果,跟运行原模型的结果是一样的。我们还可以通过-i参数来发起交互式对话,命令如下:
./build/bin/main -m chatglm-ggml.bin -i
# 结果显示
Welcome to ChatGLM.cpp! Ask whatever you want. Type 'clear' to clear context. Type 'stop' to exit.
Prompt > 你好
ChatGLM3 > 你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。
使用 Python 包
chatglm.cpp 还提供了 Python 包,使用该工具包我们也可以运行量化后的模型,首先安装 Python 依赖包,命令如下:
pip install -U chatglm-cpp
代码执行
安装完 Python 包,我们就可以使用 Python 代码来运行量化模型了:
import chatglm_cpp
pipeline = chatglm_cpp.Pipeline("../chatglm-ggml.bin")
pipeline.chat([chatglm_cpp.ChatMessage(role="user", content="你好")])
# 结果显示
ChatMessage(role="assistant", content="你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。", tool_calls=[])
可以看到跟源码编译运行的结果是一样的。
命令行执行
也可以使用 Python 脚本运行量化模型,脚本文件在 chatglm.cpp 项目下的 examples 目录中,命令如下:
python examples/cli_demo.py -m chatglm-ggml.bin -p 你好
# 结果显示
你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。
部署 Web 服务
我们可以将量化后的模型部署为 Web 服务,这样就可以在浏览器中来调用模型,这里我们使用 chatglm.cpp 提供的 Web 服务脚本来部署模型。
Gradio
首先安装 Gradio 依赖,命令如下:
python3 -m pip install gradio
再修改 Web 服务脚本 examples/web_demo.py,将Share属性改为True,这样可以在服务器外访问 Web 服务,然后再启动 Web 服务,命令如下:
python3 chatglm.cpp/examples/web_demo.py -m chatglm-ggml.bin
# 结果显示
Running on local URL: http://127.0.0.1:7860
Running on public URL: https://41db812a8754cd8ab3.gradio.live
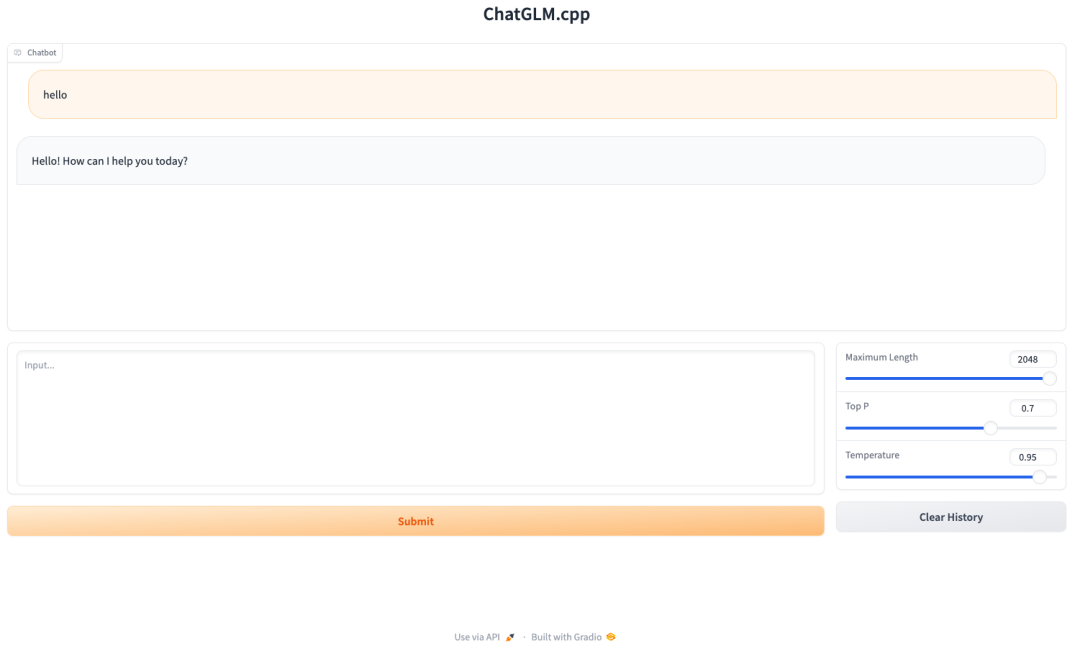
浏览器访问public URL的显示结果:
Streamlit
ChatGLM3-6B 除了提供 Gradio 的 Web 服务外,还提供了一个综合各种工具的 Streamlit Web 服务,我们再来部署该服务。首先安装 Streamlit 依赖,命令如下:
python3 -m pip install streamlit jupyter_client ipython ipykernel
ipython kernel install --name chatglm3-demo --user
再修改综合服务的脚本 examples/chatglm3_demo.py,将模型的地址改为量化模型的地址,改动如下:
-MODEL_PATH = Path(__file__).resolve().parent.parent / "chatglm3-ggml.bin"
+MODEL_PATH = "/content/chatglm-ggml.bin"
我们还需要将 Colab 服务器中的 Web 服务代理到公网,需要安装 CloudFlare 的反向代理,这样我们才可以在服务器外访问该 Web 服务,命令如下:
wget https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64
chmod +x cloudflared-linux-amd64
最后启动 Streamlit Web 服务和代理服务,命令如下:
# 启动 Stratmlit Web 服务
streamlit run chatglm.cpp/examples/chatglm3_demo.py &>/content/logs.txt &
# 启动代理服务
grep -o 'https://.*\.trycloudflare.com' nohup.out | head -n 1 | xargs -I {} echo "Your tunnel url {}"
nohup /content/cloudflared-linux-amd64 tunnel --url http://localhost:8501 &
# 结果显示
Your tunnel url https://incorporated-attend-totally-humidity.trycloudflare.com
nohup: appending output to 'nohup.out'
浏览器访问tunnel url的显示结果:
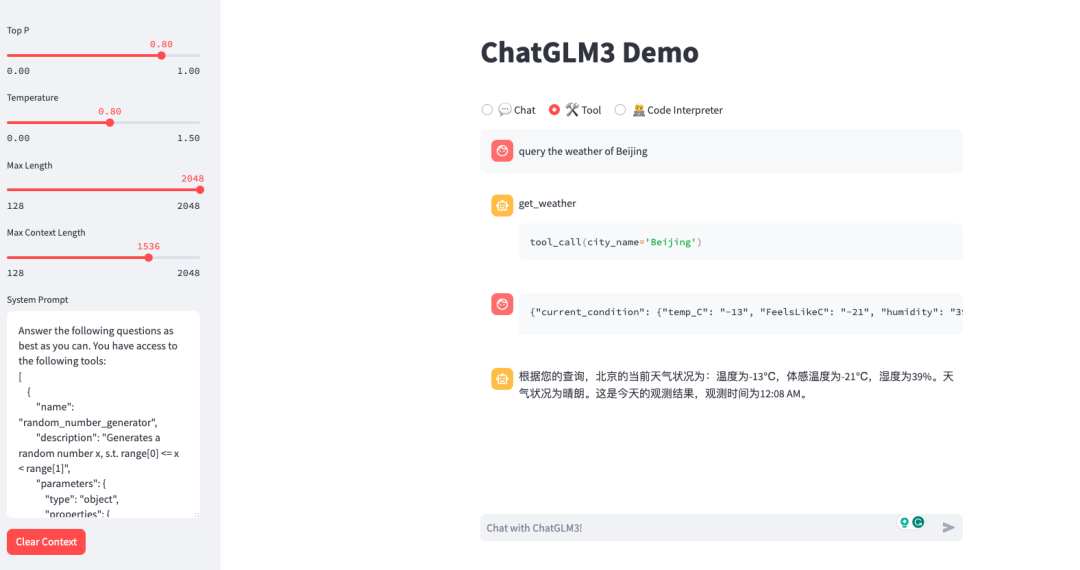
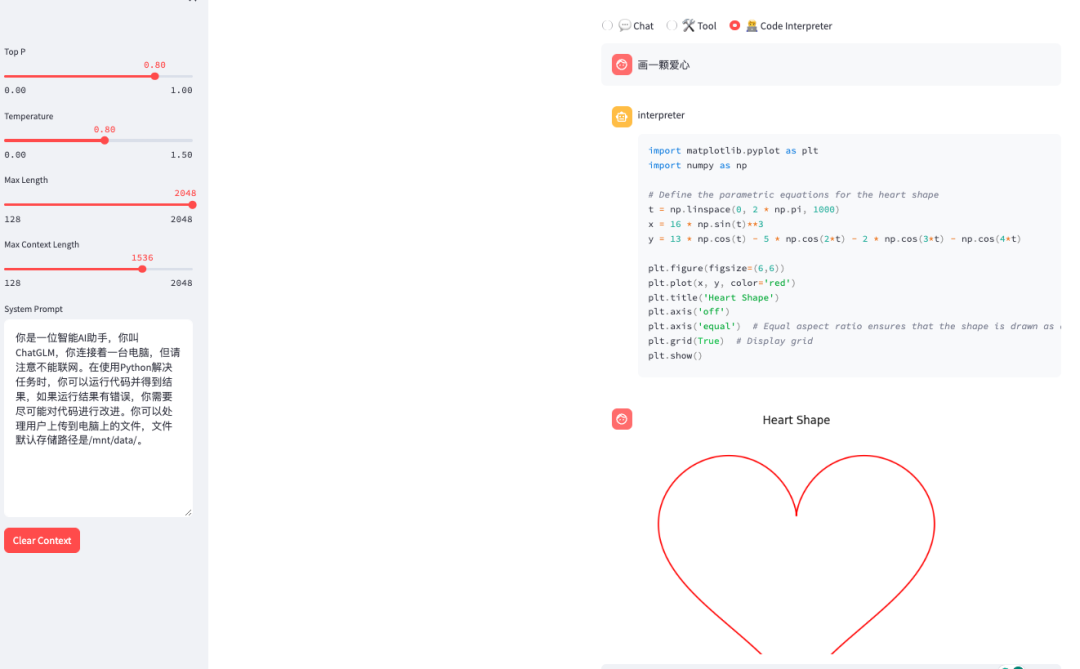
部署 API 服务
我们还可以将量化后的模型部署为 API 服务,chatglm.cpp 的 Python 包提供了启动 API 服务的功能,该 API 适配 OpenAI API。
首先是安装 chatglm.cpp 的 API 包,命令如下:
pip install -U 'chatglm-cpp[api]'
然后启动 API 服务,命令如下:
MODEL=./chatglm-ggml.bin uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000
MODEL 环境变量是量化模型的地址,然后我们使用curl命令来验证一下 API 服务是否正常,命令如下:
curl http://127.0.0.1:8000/v1/chat/completions -H 'Content-Type: application/json' -d '{"messages": [{"role": "user", "content": "你好"}]}'
# 返回结果
{
"id":"chatcmpl",
"model":"default-model",
"object":"chat.completion",
"created":1703052225,
"choices": [
{
"index":0,
"message": {
"role":"assistant",
"content":"你好!我是人工能助手 ChatGLM3-6B,很高兴见到你,欢迎问任何问题。"
},
"finish_reason":"stop"
}
],
"usage":{
"prompt_tokens":8,
"completion_tokens":29,
"total_tokens":37
}
}
可以看到 API 返回结果的数据结构跟 OpenAI API 的数据结构是一样的。
总结
本文介绍了如何在 Colab 上使用 chatglm.cpp 对 ChatGLM3-6B 模型进行 GGML 版本的量化,并介绍了多种部署方式来运行量化后的模型,这些运行方式可以让我们在不同的场景下使用量化模型,而且全程是在 CPU 服务器上运行的,无需任何 GPU 显卡。希望本文对大家部署 LLM 或打造私有化 LLM 应用有所帮助,文中的 Colab 脚本见这里[9],如果文中有什么错误或不足之处,欢迎在评论区指出。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。
参考:
[1]Colab: https://colab.research.google.com/
[4]GGML: https://github.com/ggerganov/ggml
[6]chatglm.cpp: https://github.com/li-plus/chatglm.cpp
[7]GGML: https://github.com/ggerganov/ggml
[8]还不支持 GGUF 格式: https://github.com/li-plus/chatglm.cpp/issues/135#issuecomment-1752027324
[9]这里: https://colab.research.google.com/drive/1j__5w9vMVyO5X8xFgCi8cUl231G1G55c?usp=sharing
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!