【LLM】Prompt Engineering
Prompt Engineering
- CoT
- CoT - SC
- ToT
- GoT
CoT: Chain-of-Thought

通过这样链式的思考,Model输出的结果会更准确
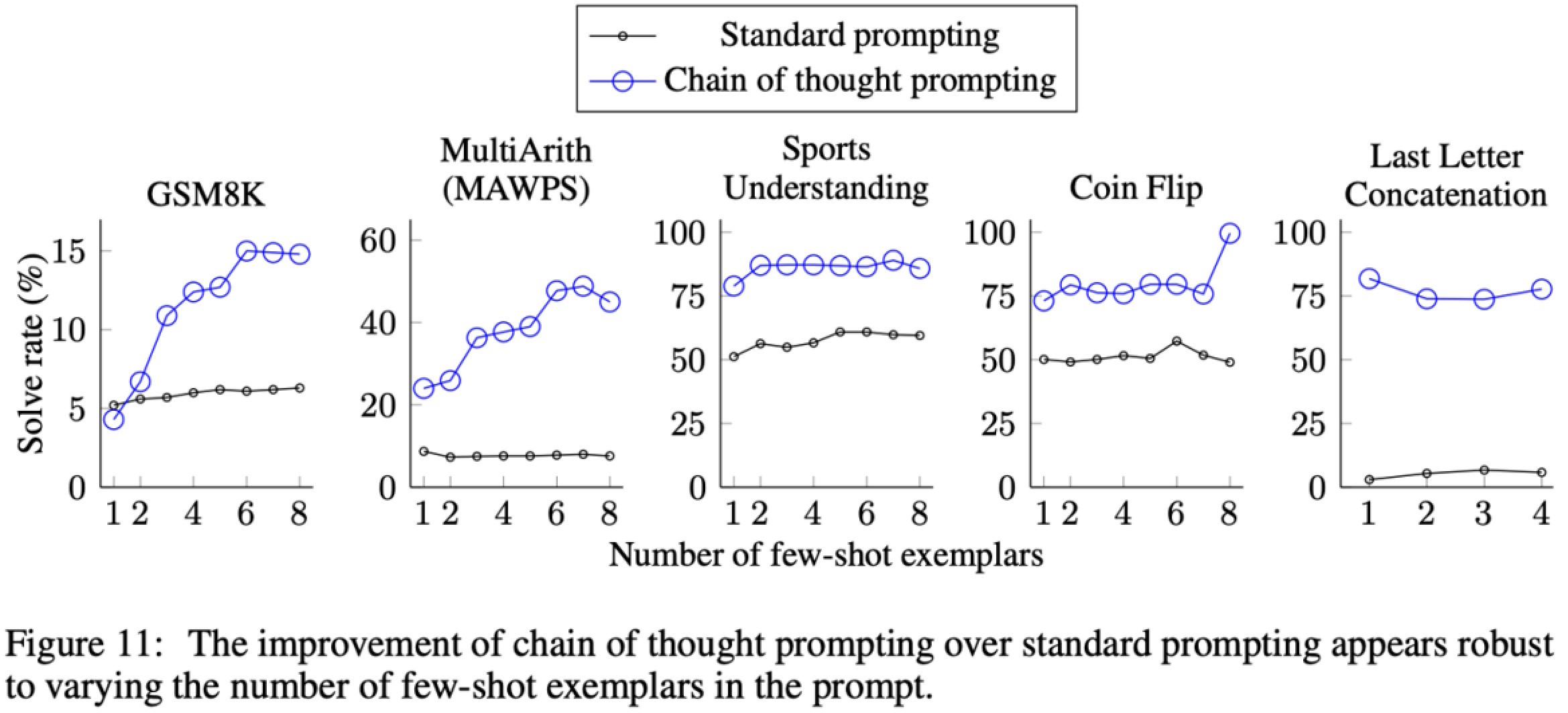
CoT-SC: Self-Consistency Improves Chain of Thought Reasoning in Language Models
往往,我们会使用Greedy decode这样的策略,每次在概率最大的几个token中选择一个token,进行一个链式推理。
但是这样的方法会有一个问题:就是当Greedy decode中有一步出现了错误 (比如将3 + 4 = 后生成了一个6),那么后面的推理就会越错越离谱

因此,人们提出了Self-consistency这种方式,每次生成多个推理路径 (reasoning paths),从多个推理路径得到的结果中取一致性最高的那个结果。

表中第三行就是在CoT的基础上加上Self-consistency机制。我们明显发现在不同的bench码里面,它的性能都是优于前面两种的。
ToT:Tree of Thoughts
与CoT-SC不同,ToT认为人的决策过程更像是一棵树,人在每一步决策的时候都有可能会决策失败 (或者没那么好),我们给每次推理都加上一个Value,用额外的prompting去检验Model现在的选择是不是对的

Game of 24
ToT的优势体现在24点这样的游戏中,要根据Input得到Result,光靠记忆是做不到的,若是靠CoT推理有时也会出问题。
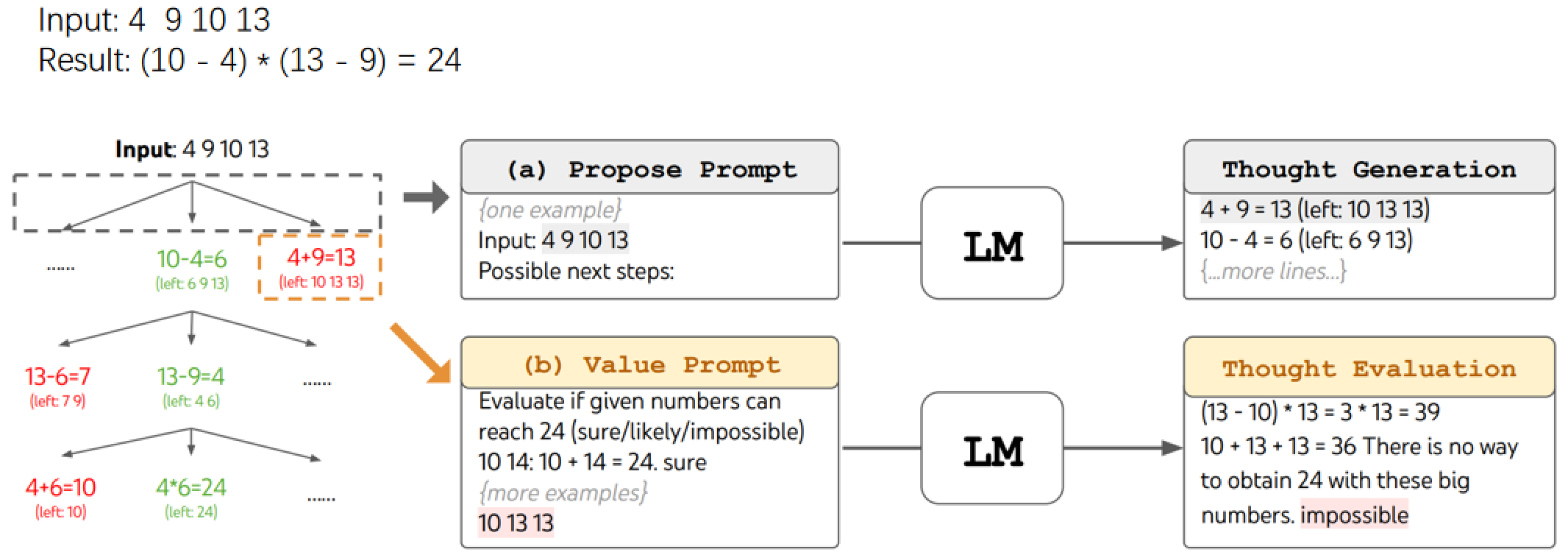
而ToT可以在中间步骤中将impossible的分支抛弃掉,然后回溯到上一个likely的分支继续,直到变为sure

可以看到ToT在24点游戏中的优势,b指ToT树的深度

GoT: Graph of Thoughts
在另一些任务中,任务的推理展开可能更类似于图而不是树。
用树描述推理展开会导致推理状态指数增大,而用图描述问题的话,意味着推理展开中可能有一些节点跟之前的一些节点是类似的或者它的推理逻辑是一样的,因此不同的分支可以被进一步推理到一个节点上去,一个节点也可以自己指向自己做一个refine

这样的结果就是能够大大减少推理的成本。
PEFT: Parameter-Efficient Fine-Tuning
如何做一个高效的Tuning
-
Fine-Tuning:全量微调
-
Adapter-Tuning
-
Prefix-Tuning
-
Prompt-Tuning
-
P-Tuning
-
*LoRA
Adapter-Tuning
当我们的模型参数量越来越大,对于算力要求会很高从而效果不好。Adapter-Tuning的做法是通过加上一些额外的参数 (下游微调),使得我们只要训练某几部分的一些的参数,而不是去改变整个模型的参数。
如下图左,Adapter被加在了两个Feed-foreard之后,其结构如右图所示,是Feedforward+Normalization+Feedforward的结构

通过这样的操作,我们调参量基本上只有先前的3%。
Prefix-Tuning
只在模型的Embedding上额外增加了一个Embedding层
比如进行翻译任务时,一般就对“请帮我将下面的文字翻译成英文…”这样的开头部分增加Embedding,然后进行Encode,之后微调也就值调整Embedding的部分

如果模型的线性层很大的话,Adapter-Tuning要调整的参数量其实也不少。而相比于Adapter-Tuning,Prefix-Tuning的调参量会稳定小很多 (大概Fine-Tuning的千分之一),因为只需要调整Embedding的参数。
Prompt-Tuning
其实道理跟Prefix-Tuning是一样的,也是根据任务类型去微调Prompt,不过没有专门设置一块Prefix出来,而是对额外的Mixed-task Batch微调罢了

效果跟前两者是差不多的。
P-Tuning-v2
清华大学提出的一种方法,和他们一代以及其他方法的区别在于,不仅仅影响第一层Transformer。P-Tuning-v2将下面这样的结构的输出,作为一个输入分别加到每一层Transformer上去,在不增加太多调参量的情况下也能达到很好的效果

LoRA: Low-Rank Adaptation of Large Language Models
LoRA的原理有点类似于外挂,通过BA去影响了每一层Transformer的输出,但不对原始模型做任何嵌入式的修改,因此LoRA非常灵活能够适应任何模型

下面是一些Tuning的参数实验,后续调用LoRA库的时候也会参考其中的一些参数,比如一般把针对q和v的r设置为8

ChatGLM Code

这里ids中130001和130004可以在官方的config.json中找到定义

Preparation
步入model.generate,我们发现并没有直接开始generate,而是进入了一段prepare的代码,用于生成position_ids和attention_mask
input_ids: 输入到模型的 token ID,通常是一个批次的文本数据经过 tokenization 后的形式。past和past_key_values: 用于缓存以前的计算结果,以提高解码效率,通常在自回归模型中使用。attention_mask: 指示哪些位置是有效输入的掩码,用于忽略(mask)某些特定的 token。position_ids: 指示 token 在序列中的位置。**kwargs: 接受额外的关键字参数。


第一次准备的时候不会进入1124行的if (由于没有past),所以会直接跳转到1151行执行。
如果 past 和 past_key_values 为空,这意味着函数处于生成过程的开始阶段。在这种情况下,将处理完整的 input_ids,并根据需要计算 attention_mask 和 position_ids。
如果 past 或 past_key_values 不为空,这意味着函数处于生成过程的后续步骤中。此时,只需要考虑输入序列的最后一个 token(last_token)。对于 attention_mask 和 position_ids,也只考虑最后一个位置的值。position_ids 是基于Mask位置计算得出的。
第一次执行完1154行的内容,attetion_mask如下所示,原因在于我们输入一共是五维的,对于前几个token来说所有区域都是可见的,所以不需要Mask (设置为False);而对于BOS来说,它只能看见前面的token,自己和自己后面的token不可见,所以要Mask掉 (设置为True)
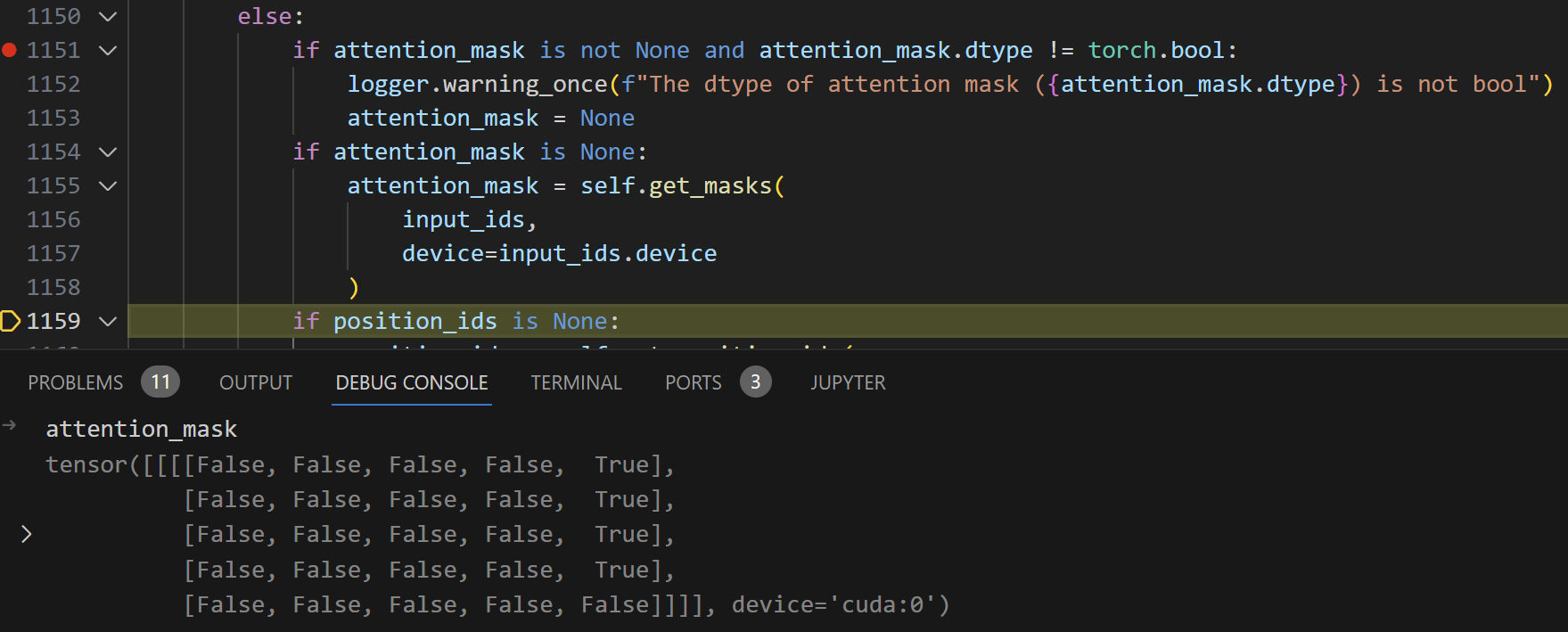

所以此时的input_ids与一开始的ids没有区别

执行完1159行的内容后,position_ids的值如下所示,可以看到Position1一直递增到了BOS的位置,Position2在BOS的位置被设置为了1


以上,就是在生成第一个token之前在prepare部分要做的准备。
Forward
prepare完成之后进入forward,forward的参数参数包括输入标识(input_ids)、位置标识(position_ids)、注意力掩码(attention_mask)、过去的键值对(past_key_values)、输入嵌入(inputs_embeds)、标签(labels)、以及几个控制输出的标志(use_cache, output_attentions, output_hidden_states, return_dict,其中use_cache 和 return_dict 根据配置或传入的参数值来确定是否使用缓存和是否返回字典形式的输出)

1190行调用了 Transformer 模型
- 使用提供的参数调用内部的 Transformer 模型(
self.transformer),稍后进入其中查看细节。 - 获取 Transformer 模型的输出,通常包括隐藏状态(
hidden_states)、注意力分数等。
打印一下transformer_outputs,好家伙, Transformer 模型输出了一大堆

这一大堆其实是由两部分组成的:last_hidden_state (最后一层的hidden state) 和 past_key_values

接着,hidden_states 通过一个线性层(self.lm_head)来生成语言模型的 logits(预测每个词汇的得分)。

在第一次运行时,1207、1220处的if判断都会被跳过
- 如果提供了
labels(目标标签),则计算损失。这通常用于训练过程,通过交叉熵损失函数计算预测和实际标签之间的损失。 - 将 logits 和损失调整回原始的数据类型(如果有必要)
到了return这里,将
- 根据
return_dict的值返回不同格式的输出。如果为True,返回一个包含损失、logits、过去的键值对 (相当于一个缓存,用于加速)、隐藏状态和注意力分数的结构化对象(CausalLMOutputWithPast)。 - 如果
return_dict为False,则返回一个包含所有这些元素的元组。
更新
执行完return我们就实现了第一个token的生成,此时程序会跳转到这里来更新一些参数

至此,我们生成了第一个token,开始生成第二个。
第二轮的时候position_ids为[[3], [2]],attention_mask为空

然后是第三轮

看一下结果

Add LoRA
LoRA 是一种高效的神经网络适应方法,通过在预训练模型的权重上应用低秩矩阵,从而在不显著增加参数数量的情况下增强模型的表示能力。
get_peft_model
下面展示如何在一个 ChatGLM 模型中添加 LoRA (Low-Rank Adaptation) 层来改进其性能,特别是在微调阶段。
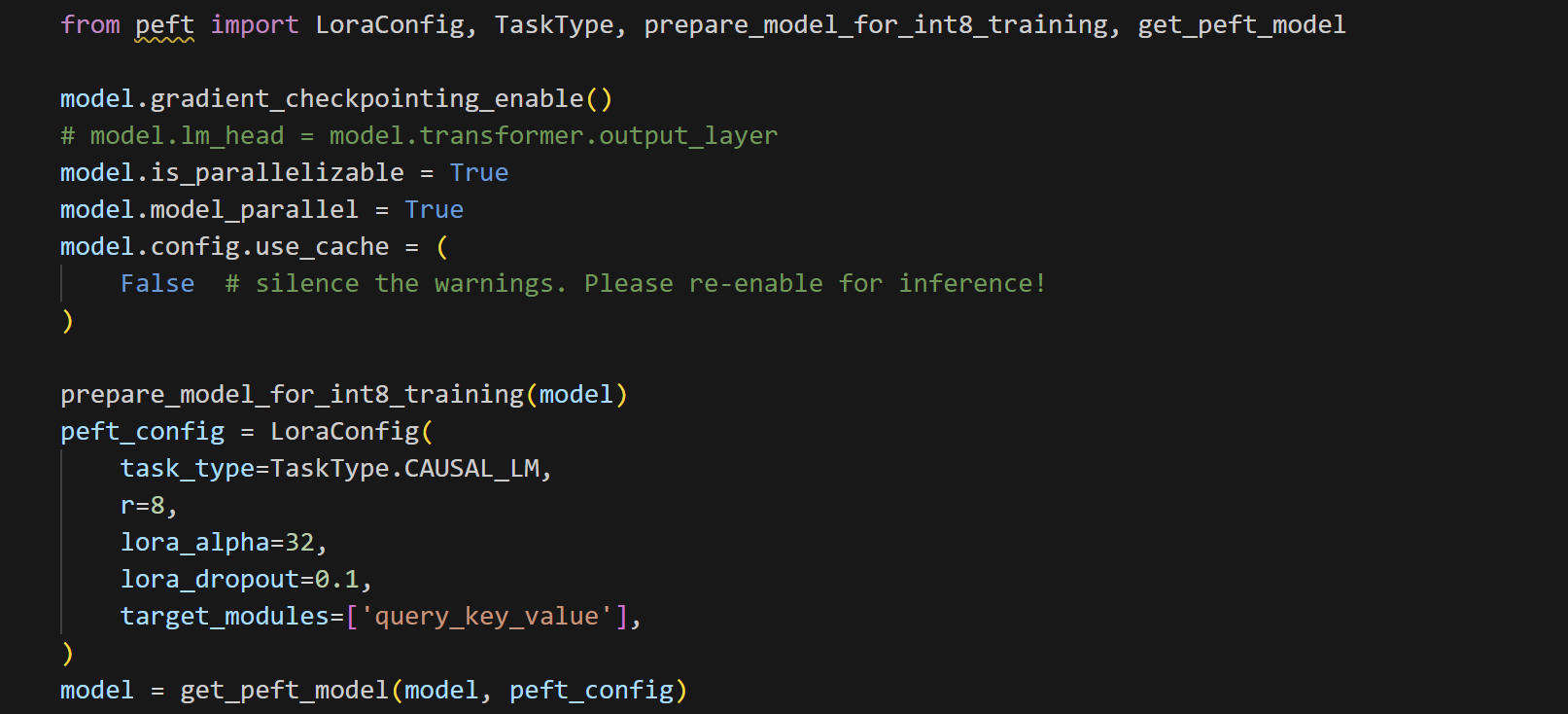
-
梯度检查点:
model.gradient_checkpointing_enable()这一行启用了梯度检查点功能,它有助于减少显存使用,允许在相对较小的 GPU 上训练大模型。
-
并行化设置:
model.is_parallelizable = True model.model_parallel = True这些行设置模型为可并行化,并启用模型并行,有助于在多个 GPU 上分布模型的计算。
-
禁用缓存:
model.config.use_cache = False对于某些训练任务,禁用模型的缓存机制可以避免额外的内存消耗。
-
准备进行 INT8 训练:
prepare_model_for_int8_training(model)这一行准备模型进行 INT8 训练,这是一种量化方法,可减少模型训练和推理过程中的内存和计算需求。
-
LoRA 配置:
peft_config = LoraConfig( task_type=TaskType.CAUSAL_LM, r=8, lora_alpha=32, lora_dropout=0.1, target_modules=['query_key_value'], )这里创建了一个
LoraConfig对象,用于配置 LoRA 参数。参数包括任务类型(因果语言模型CAUSAL_LM),LoRA 参数r和lora_alpha(决定低秩矩阵的大小和影响),lora_dropout(LoRA 层的 dropout 比率),以及目标模块(在这里是 ChatGLM 的query_key_value部分)。

目标模块是
query_key_value

这个层其实是可选的
-
获取带有 LoRA 的模型:
model = get_peft_model(model, peft_config)使用上述配置,获取一个经过 LoRA 修改的模型。这个步骤实际上是在模型的指定层中添加 LoRA 层,以增强模型的微调能力。
步入之后来到这里
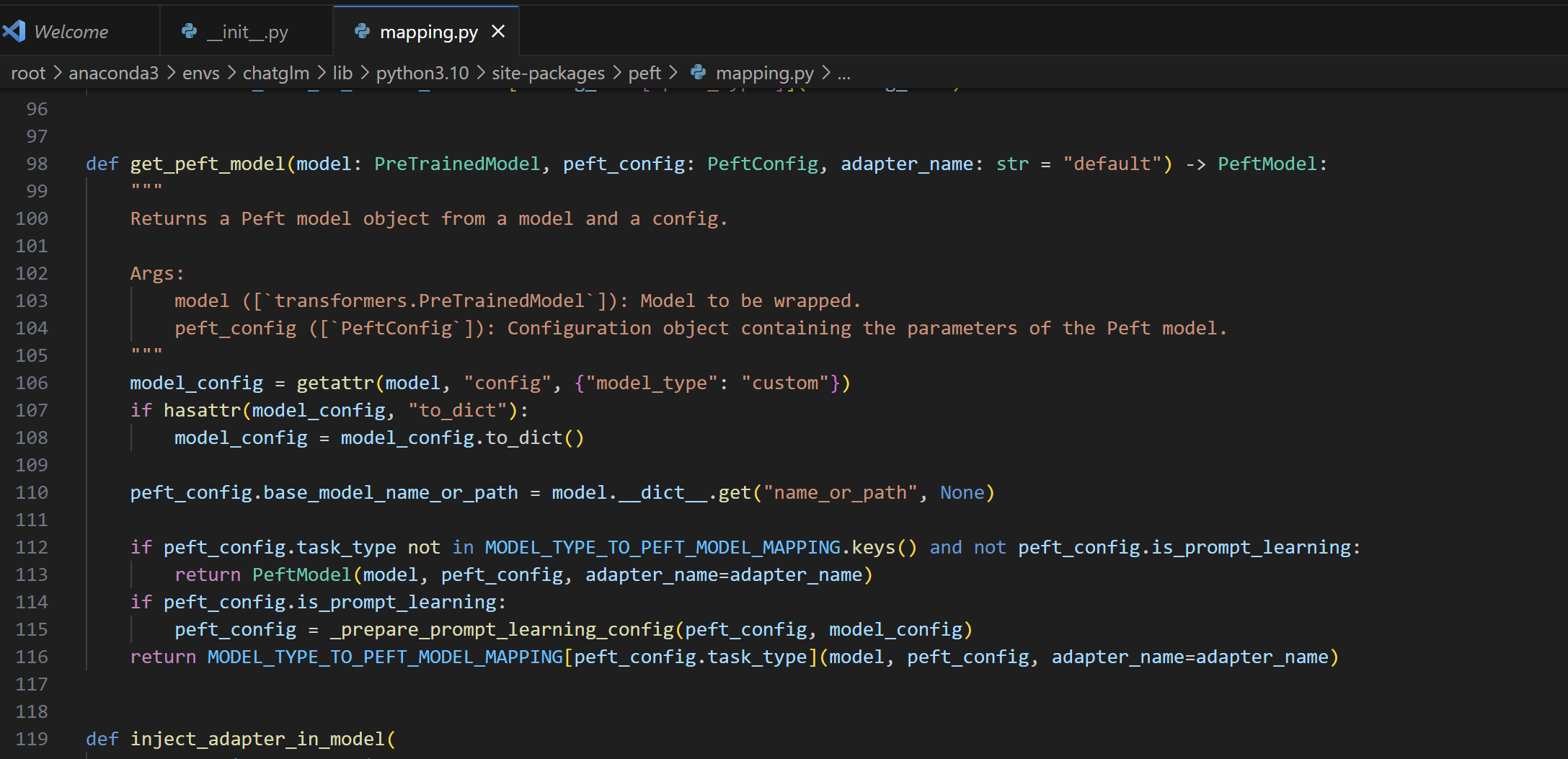
最重要的就是返回了一个 PeftModel 对象,再跟进去看看
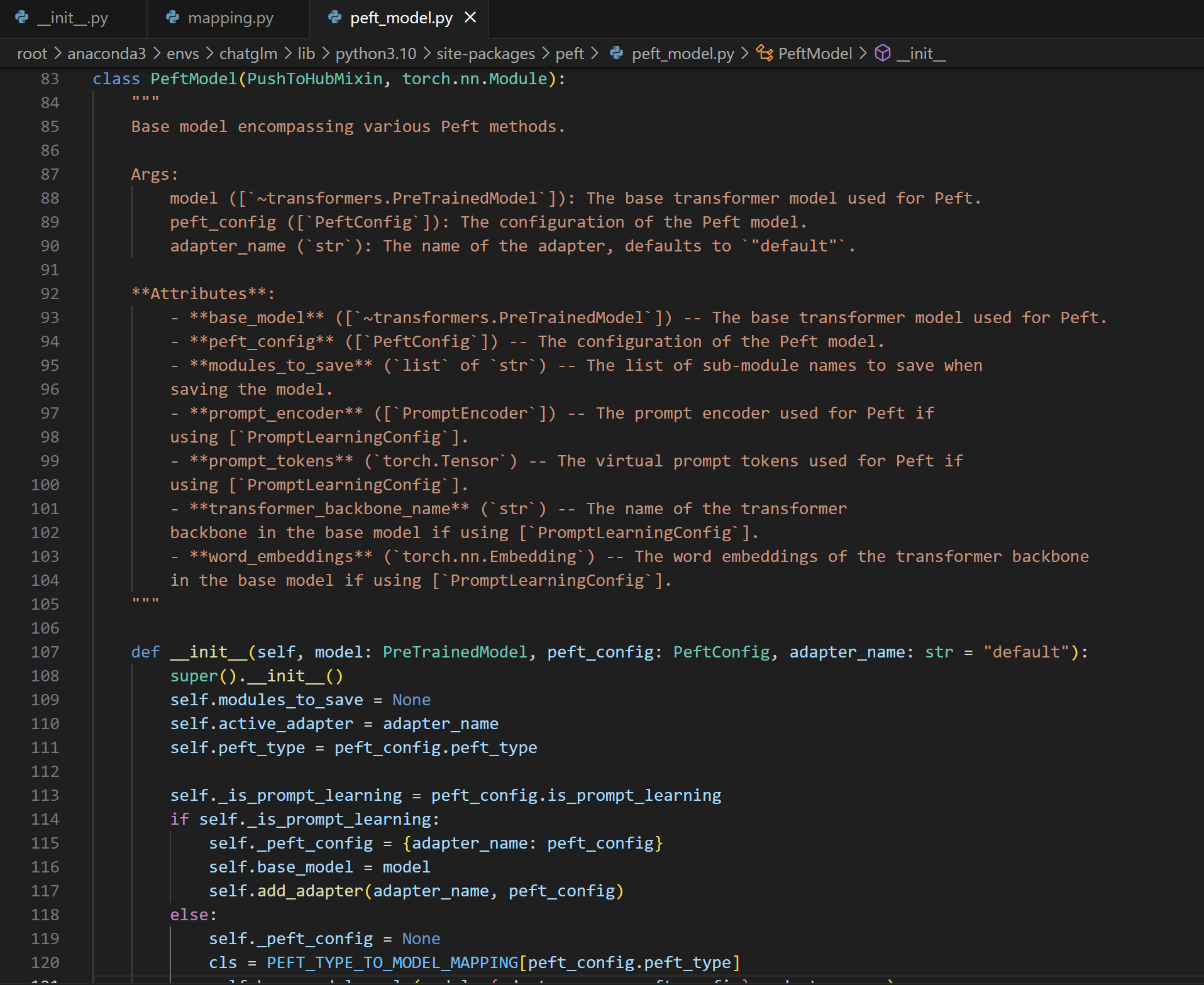
class PeftModel(PushToHubMixin, torch.nn.Module): """ 这段代码定义了一个名为 PeftModel 的类,它是用于封装各种 Peft 方法的基础模型。Peft(Performance Efficient Fine-Tuning)是一种用于提高模型微调效率和性能的方法。 这个类提供了一个框架,用于在基础的 Transformer 模型上应用 Peft 技术,如提示学习或其他微调方法。它通过将额外的模块或适配器添加到模型中,提高了模型微调的灵活性和效率。 """ def __init__(self, model: PreTrainedModel, peft_config: PeftConfig, adapter_name: str = "default"): super().__init__() self.modules_to_save = None # 列表,指定在保存模型时需要保存的子模块名称。 self.active_adapter = adapter_name # 激活的适配器名称,默认为 "default"。 self.peft_type = peft_config.peft_type # Peft的类型,从配置中获取。 self._is_prompt_learning = peft_config.is_prompt_learning # 标志,表明是否使用提示学习(Prompt Learning)。 if self._is_prompt_learning: self._peft_config = {adapter_name: peft_config} # 如果使用提示学习,将配置存储在字典中。 self.base_model = model # 基础 Transformer 模型。 self.add_adapter(adapter_name, peft_config) # 添加适配器,配置提示学习。 else: self._peft_config = None # 如果不使用提示学习,配置设置为 None。 cls = PEFT_TYPE_TO_MODEL_MAPPING[peft_config.peft_type] # 根据 Peft 类型获取相应的模型类。 self.base_model = cls(model, {adapter_name: peft_config}, adapter_name) # 初始化基础模型。 self.set_additional_trainable_modules(peft_config, adapter_name) # 设置额外的可训练模块。 self.config = getattr(self.base_model, "config", {"model_type": "custom"}) # 获取模型配置,如果不存在则设置为自定义类型。 if getattr(model, "is_gradient_checkpointing", True): # 检查模型是否支持梯度检查点。 model = self._prepare_model_for_gradient_checkpointing(model) # 准备模型以进行梯度检查点。 # 禁用模拟的张量并行性(Tensor Parallelism),避免数值差异。 if hasattr(self.base_model, "config") and hasattr(self.base_model.config, "pretraining_tp"): self.base_model.config.pretraining_tp = 1debug到这一步,我们能看到我们此时的
base_model是一个 LoraModel 对象
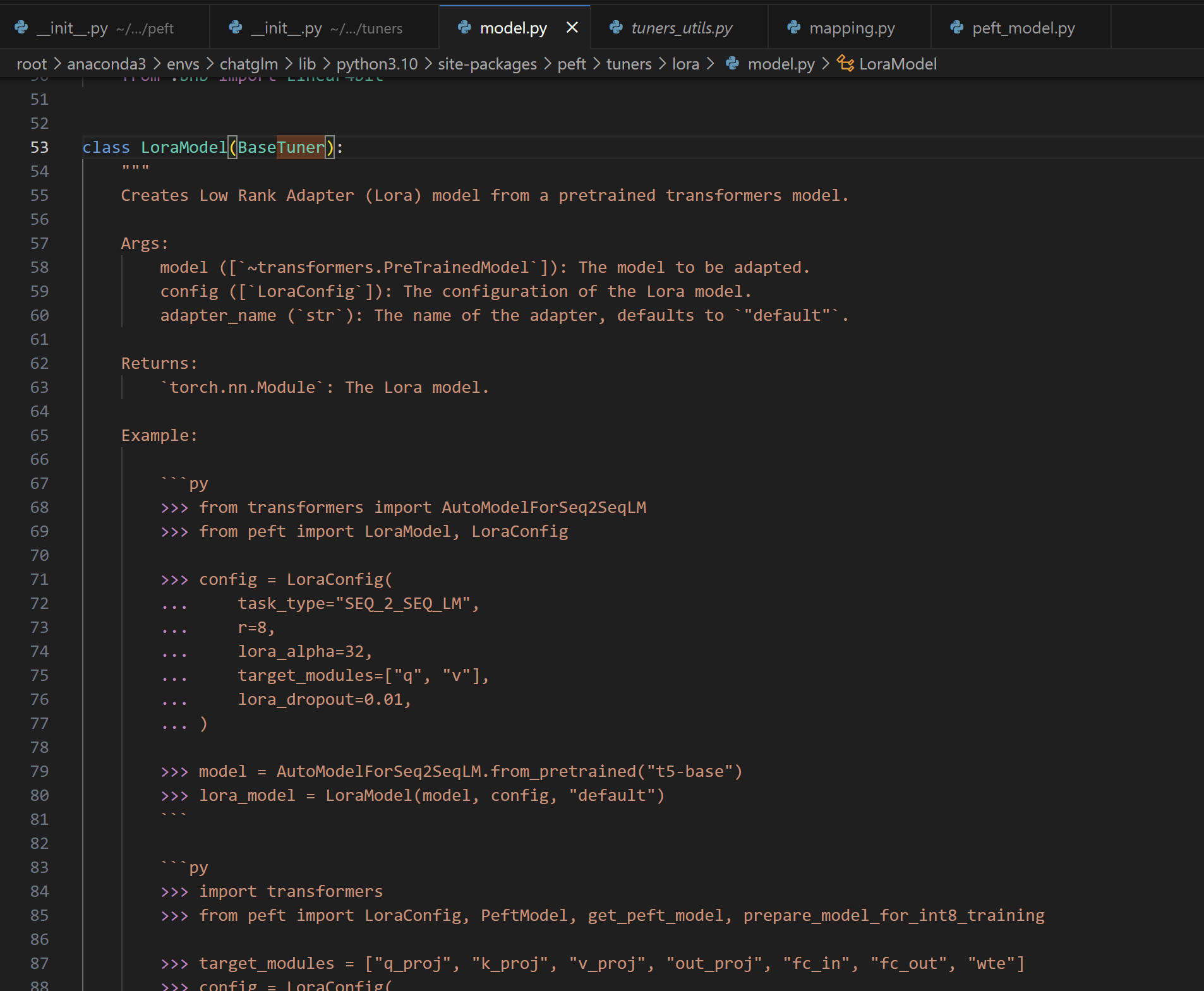
这个 LoraModel 又继承了 BaseTuner

class BaseTuner(nn.Module, ABC): """ 这段代码定义了一个名为 BaseTuner 的基础调谐器类,用于向 torch.nn.Module 注入可调节的层(如适配器层或其他调谐层)。这个类提供了通用的方法和属性,用于所有可以注入到 torch.nn.Module 的调谐器。 在这个类中,peft_config 用于存储调谐器的配置,这可能是单个 PeftConfig 对象或一个字典,字典中的每个键对应一个适配器的配置。该类还负责将适配器注入到传入的基础模型中,并确保模型具有正确的配置属性。 这个类为开发者提供了一个框架,用于创建和管理可注入到标准 PyTorch 模型中的调谐器。开发新的调谐器时,可以通过继承此类并重写其方法来实现特定的调谐逻辑。 """ def __init__(self, model, peft_config: Union[PeftConfig, dict[str, PeftConfig]], adapter_name: str) -> None: super().__init__() self.model = model # 基础模型,适配器调谐层将附加到此模型。 # 如果模型上没有 `peft_config` 属性,则为其创建一个。 # `peft_config` 是用于配置调谐器的配置对象。 if not hasattr(self, "peft_config"): self.peft_config = {adapter_name: peft_config} if isinstance(peft_config, PeftConfig) else peft_config else: # 如果模型已有 `peft_config`,则更新或添加新的配置。 if isinstance(peft_config, PeftConfig): self.peft_config[adapter_name] = peft_config else: self.peft_config.update(peft_config) self.active_adapter = adapter_name # 激活的适配器名称。 # 确保存在 `config` 属性,该属性在之后的处理中假定存在。 if not hasattr(self, "config"): self.config = {"model_type": "custom"} self.inject_adapter(self.model, adapter_name) # 将适配器注入到模型中。 # 将 `peft_config` 复制到注入的模型中。 self.model.peft_config = self.peft_config其中,
inject_adapter的实现如下
def inject_adapter(self, model: nn.Module, adapter_name: str): """ 创建适配器层并替换目标模块。如果传递了非提示调谐适配器类,这个方法会被 `peft.mapping.get_peft_model` 在底层调用。 Args: model (`nn.Module`): 要调谐的模型。 adapter_name (`str`): 适配器名称。 """ peft_config = self.peft_config[adapter_name] # 从 BaseTuner 类的 `peft_config` 属性中直接获取相应的 PEFT 配置。 # 检查配置是否完整,如果有问题则在方法开始时提前抛出异常。 self._check_new_adapter_config(peft_config) # 遍历模型中的所有子模块,并检查是否需要保存。 key_list = [key for key, _ in model.named_modules()] _check_for_modules_to_save = getattr(peft_config, "modules_to_save", None) is not None _has_modules_to_save = False # 获取模型配置,如果配置有 `to_dict` 方法,则将其转换为字典。 model_config = getattr(model, "config", {"model_type": "custom"}) if hasattr(model_config, "to_dict"): model_config = model_config.to_dict() # 准备适配器配置,这可能包括补充遗漏的字段。 peft_config = self._prepare_adapter_config(peft_config, model_config) for key in key_list: # 检查是否存在需要保存的模块。 if _check_for_modules_to_save and any( key.endswith(f"{module_to_save}") for module_to_save in peft_config.modules_to_save ): parent, target, target_name = _get_submodules(model, key) # 如果目标不是 ModulesToSaveWrapper 类型,则用该类型包装它。 if not isinstance(target, ModulesToSaveWrapper): new_module = ModulesToSaveWrapper(target, adapter_name) setattr(parent, target_name, new_module) else: target.update(adapter_name) _has_modules_to_save = True continue # 检查目标模块是否存在于适配器配置中。 if not self._check_target_module_exists(peft_config, key): continue # 替换目标模块 parent, target, target_name = _get_submodules(model, key) optional_kwargs = { "loaded_in_8bit": getattr(model, "is_loaded_in_8bit", False), "loaded_in_4bit": getattr(model, "is_loaded_in_4bit", False), "current_key": key, } self._create_and_replace(peft_config, adapter_name, target, target_name, parent, **optional_kwargs) # 如果没有找到目标模块,则抛出异常。 if not is_target_modules_in_base_model: raise ValueError( f"Target modules {peft_config.target_modules} not found in the base model. " f"Please check the target modules and try again." ) # 将只有适配器部分设置为可训练。 self._mark_only_adapters_as_trainable() # 如果是推理模式,将适配器的参数设置为不可训练。 if self.peft_config[adapter_name].inference_mode: for n, p in self.model.named_parameters(): if adapter_name in n: p.requires_grad = False # 更新需要保存的模块列表。 if _has_modules_to_save: if not hasattr(model, "modules_to_save"): model.modules_to_save = set(peft_config.modules_to_save) else: model.modules_to_save.update(set(peft_config.modules_to_save))在上面的 替换目标模块 中,使用到了关键方法
_create_and_replace
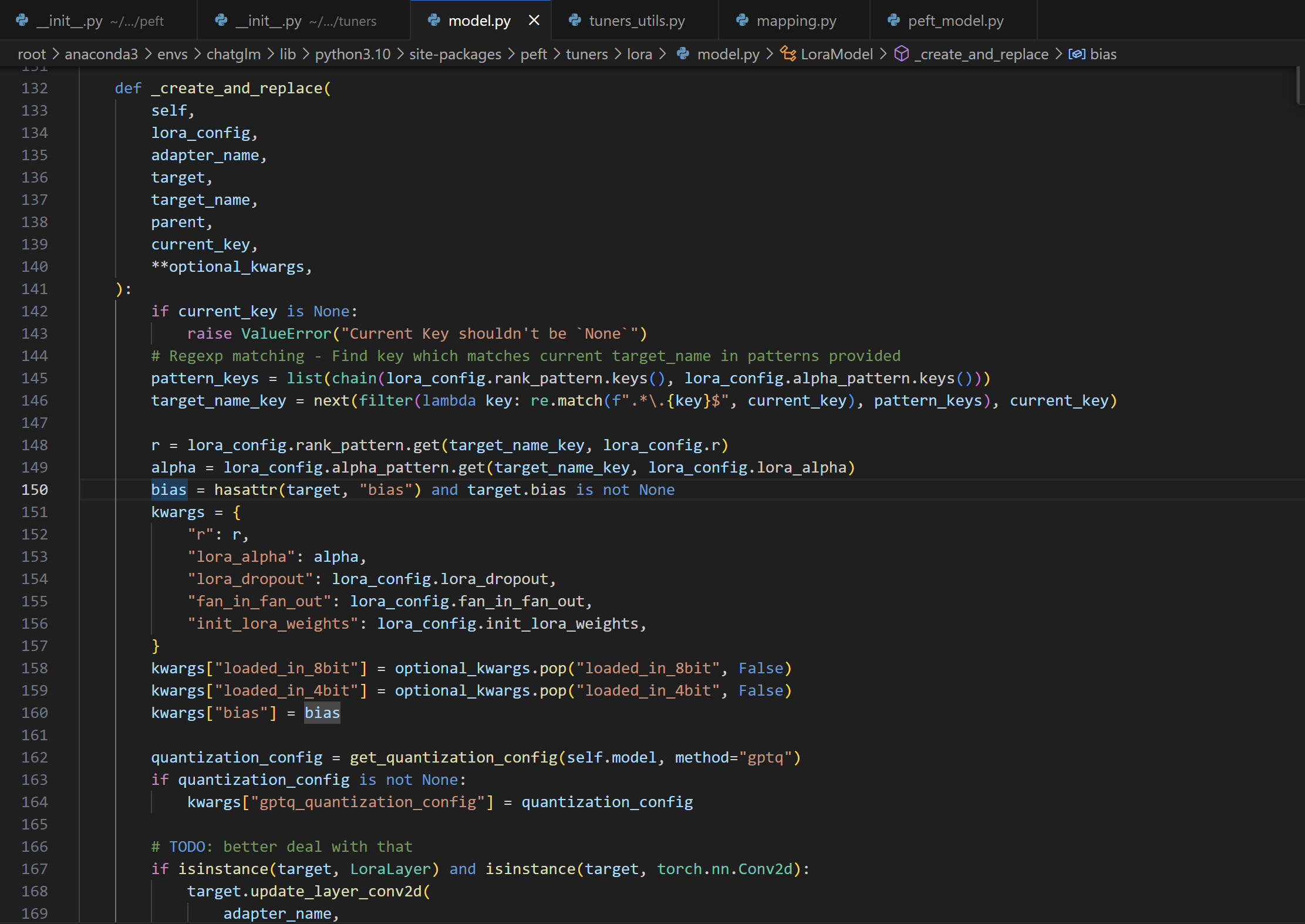
def _create_and_replace( self, lora_config, adapter_name, target, target_name, parent, current_key, **optional_kwargs, ): """ 这段代码定义了 _create_and_replace 方法,它在适配器调谐器中用于创建和替换目标模块(如神经网络中的层)。该方法根据 LoRA(Low-Rank Adaptation)配置创建新的模块或更新现有的模块。 此方法的主要作用是根据 LoRA 配置在模型中创建新的模块或更新现有模块,以增强模型的表示能力和适应性。它处理不同类型的目标模块(如卷积层、嵌入层或其他 LoRA 层),并根据配置调整它们的行为。这种方法允许在不显著改变原始模型架构的前提下,为模型添加额外的功能或调整其性能。 """ # 确保 current_key 不为 None if current_key is None: raise ValueError("Current Key shouldn't be `None`") # 使用正则表达式匹配模式,确定当前 key 是否匹配 LoRA 配置中的某个模式 pattern_keys = list(chain(lora_config.rank_pattern.keys(), lora_config.alpha_pattern.keys())) target_name_key = next(filter(lambda key: re.match(f".*\.{key}$", current_key), pattern_keys), current_key) # 根据模式或默认值获取 LoRA 的参数:r 和 alpha r = lora_config.rank_pattern.get(target_name_key, lora_config.r) alpha = lora_config.alpha_pattern.get(target_name_key, lora_config.lora_alpha) bias = hasattr(target, "bias") and target.bias is not None # 检查目标模块是否有偏置 # 准备 LoRA 层的参数 kwargs = { "r": r, "lora_alpha": alpha, "lora_dropout": lora_config.lora_dropout, "fan_in_fan_out": lora_config.fan_in_fan_out, "init_lora_weights": lora_config.init_lora_weights, } kwargs.update(optional_kwargs) # 添加额外的参数 # 如果模型有量化配置,则获取该配置 quantization_config = get_quantization_config(self.model, method="gptq") if quantization_config is not None: kwargs["gptq_quantization_config"] = quantization_config # 根据目标模块的类型,选择相应的更新方法 if isinstance(target, LoraLayer) and isinstance(target, torch.nn.Conv2d): # 对于卷积层,调用更新卷积层的方法 target.update_layer_conv2d(adapter_name, r, alpha, lora_config.lora_dropout, lora_config.init_lora_weights) elif isinstance(target, LoraLayer) and isinstance(target, torch.nn.Embedding): # 对于嵌入层,调用更新嵌入层的方法 target.update_layer_embedding(adapter_name, r, alpha, lora_config.lora_dropout, lora_config.init_lora_weights) elif isinstance(target, LoraLayer): # 对于其他 LoRA 层,调用通用的更新方法 target.update_layer(adapter_name, r, alpha, lora_config.lora_dropout, lora_config.init_lora_weights) else: # 如果目标不是 LoRA 层,创建新的 LoRA 模块并替换原有模块 new_module = self._create_new_module(lora_config, adapter_name, target, **kwargs) if adapter_name != self.active_adapter: # 如果添加的是附加适配器,它不会自动变为可训练 new_module.requires_grad_(False) self._replace_module(parent, target_name, new_module, target)_create_and_replace方法中,会根据目标模块的类型选择相应的更新方法。debug时,我们这里的目标不是 LoRA 层,所以创建新的 LoRA 模块并替换原有模块

@staticmethod def _create_new_module(lora_config, adapter_name, target, **kwargs): """ 这段代码定义了 _create_new_module 静态方法,用于根据给定的 LoRA 配置和目标模块类型创建新的适配器模块。 此方法的主要功能是根据目标模块的类型和 LoRA 配置创建相应的新模块。这包括处理不同类型的神经网络层(如线性层、嵌入层、卷积层等),并根据是否加载了特定的量化模式(如 8 位或 4 位)来决定创建哪种类型的新模块。此外,该方法还处理了一些特定的配置和警告,确保新创建的模块与原始目标模块兼容且适用于所需的任务。 """ # 获取 GPTQ 量化配置 gptq_quantization_config = kwargs.get("gptq_quantization_config", None) AutoGPTQQuantLinear = get_auto_gptq_quant_linear(gptq_quantization_config) # 从 kwargs 中获取和删除特定的参数 loaded_in_8bit = kwargs.pop("loaded_in_8bit", False) loaded_in_4bit = kwargs.pop("loaded_in_4bit", False) bias = kwargs.pop("bias", False) # 如果目标模块是 8 位线性模块,并且在 8 位模式中加载,则创建对应的 8 位模块 if loaded_in_8bit and isinstance(target, bnb.nn.Linear8bitLt): eightbit_kwargs = kwargs.copy() eightbit_kwargs.update({"has_fp16_weights": target.state.has_fp16_weights, "memory_efficient_backward": target.state.memory_efficient_backward, "threshold": target.state.threshold, "index": target.index,}) # 更新 8 位模块所需的参数 new_module = Linear8bitLt(adapter_name, target, **eightbit_kwargs) # 如果目标模块是 4 位线性模块,并且在 4 位模式中加载,则创建对应的 4 位模块 elif loaded_in_4bit and is_bnb_4bit_available() and isinstance(target, bnb.nn.Linear4bit): fourbit_kwargs = kwargs.copy() fourbit_kwargs.update({"compute_dtype": target.compute_dtype, "compress_statistics": target.weight.compress_statistics, "quant_type": target.weight.quant_type,}) # 更新 4 位模块所需的参数 new_module = Linear4bit(adapter_name, target, **fourbit_kwargs) # 如果目标模块是自动 GPTQ 量化线性模块,则创建相应的量化模块 elif AutoGPTQQuantLinear is not None and isinstance(target, AutoGPTQQuantLinear): new_module = QuantLinear(adapter_name, target, **kwargs) target.weight = target.qweight # 如果目标模块是嵌入层,则创建新的嵌入层模块 elif isinstance(target, torch.nn.Embedding): embedding_kwargs = kwargs.copy() embedding_kwargs.pop("fan_in_fan_out", None) # 移除不适用的参数 in_features, out_features = target.num_embeddings, target.embedding_dim new_module = Embedding(adapter_name, in_features, out_features, **embedding_kwargs) # 如果目标模块是卷积层,则创建新的卷积层模块 elif isinstance(target, torch.nn.Conv2d): out_channels, in_channels = target.weight.size()[:2] kernel_size = target.weight.size()[2:] stride = target.stride padding = target.padding new_module = Conv2d(adapter_name, in_channels, out_channels, kernel_size, stride, padding, **kwargs) # 如果目标模块是线性层或 Conv1D 层,则创建新的线性层模块 else: if isinstance(target, torch.nn.Linear): in_features, out_features = target.in_features, target.out_features ... elif isinstance(target, Conv1D): in_features, out_features = ... ... else: raise ValueError("不支持的目标模块类型") new_module = Linear(adapter_name, in_features, out_features, bias=bias, **kwargs) return new_module可以看到这个方法的作用是创建了一个
new_module,也就是下图中的A和B部分
接下来就要将
new_model和原来的W相加,debug走完_create_new_module之后来到_replace_module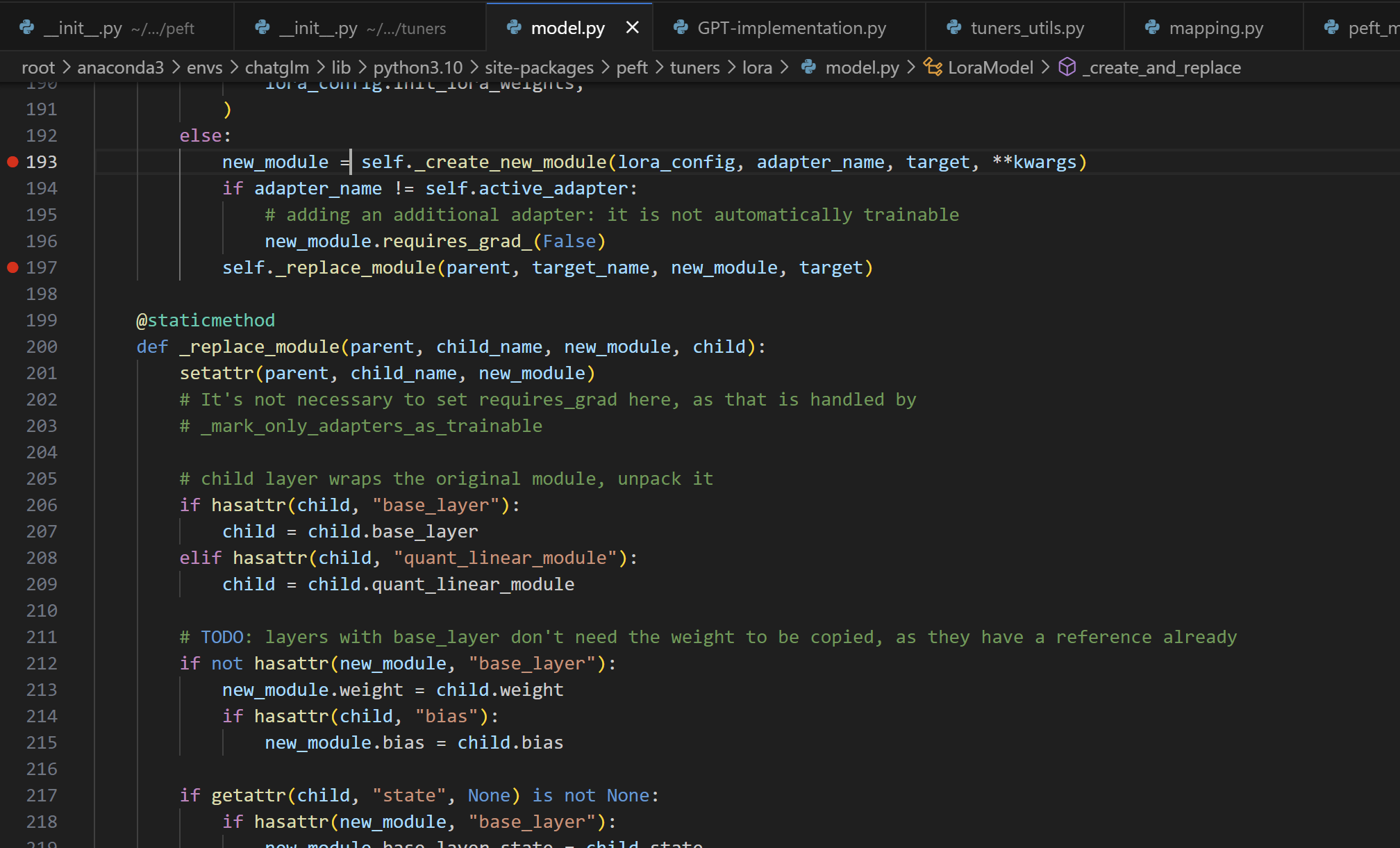
@staticmethod def _replace_module(parent, child_name, new_module, child): """ 这个方法用于将模型中的现有模块替换为新的模块。它处理包装层、权重、偏置和模块状态的复制,并确保新模块及其子模块都在正确的设备上。 """ setattr(parent, child_name, new_module) # 将新模块设置为父模块(上一层)的子模块 # 如果原始子模块有包装层,则获取其基础层 if hasattr(child, "base_layer"): child = child.base_layer elif hasattr(child, "quant_linear_module"): child = child.quant_linear_module # 如果新模块没有包装层,复制原始子模块的权重和偏置 if not hasattr(new_module, "base_layer"): new_module.weight = child.weight if hasattr(child, "bias"): new_module.bias = child.bias # 如果原始子模块有状态,则将其状态复制到新模块 if getattr(child, "state", None) is not None: if hasattr(new_module, "base_layer"): new_module.base_layer.state = child.state else: new_module.state = child.state new_module.to(child.weight.device) # 将新模块移动到正确的设备 # 确保新模块的所有子模块都被移到正确的设备 for name, module in new_module.named_modules(): if "lora_" in name or "ranknum" in name: module.to(child.weight.device)
至此我们回到了_create_and_replace并完成了一个层 (key_list中的一个key) 的外挂。最终在inject_adapter中我们会通过循环实现对所有 (选定) 层的外挂。
训练
在 Transformer 模型中,自注意力机制负责计算输入序列中的每个元素如何影响其他元素。它通过查询(query)、键(key)和值(value)三个向量来实现。
query_key_value层负责生成这三个向量。它接受来自前一层的输出,并将其转换为查询、键和值向量。
执行完后发现原来model的query_key_value里多了许多内容

lora_dropout:LoRA 层后的 dropout 层,有助于减少过拟合。lora_A和lora_B:这些是 LoRA 技术中的额外线性层,负责实现低秩矩阵乘法。base_layer:原始的Linear8bitLt层,表示自注意力中的原始query_key_value线性变换。

接下来使用特定的 tokenizer 对一个数据集进行预处理,以准备用于训练一个基于 Transformer 的语言模型。以下是对这段代码的详细解释,分条写在代码注释里:
datas = [
{
"context": "大师,我最近事业不顺利,感觉很迷茫,该怎么办?",
"target": "孩子,生活中的起伏和挫折是常态。放下烦恼,用平静的心态面对困境,努力奋斗,同时保持内心的善良与慈悲,你将找到属于你的光明之路。",
},
{
"context": "师父,我与家人之间常常发生争吵,如何改善家庭关系?",
"target": "阿弥陀佛,亲情是一份宝贵的财富,要从宽容和理解开始。培养平和的心态,倾听彼此的意见,以慈悲与智慧去化解冲突,共同创造和谐温暖的家庭氛围。",
},
{
"context": "师傅,我经常感到焦虑和压力,怎样才能获得内心的宁静?",
"target": "孩子,内心的宁静源于觉察和自我调适。修行冥想,深呼吸,寻找内心的栖息地。明白外在的变幻无常,放下过多的执着与欲望,你将发现内心的平静与安宁。",
},
{
"context": "大师,我常常陷入烦恼和抱怨,怎样才能培养感恩之心?",
"target": "施主,感恩是一种修养,需要从日常小事开始。每天意识到自己的幸运和获得,体察他人的善意和关爱。珍惜当下,感恩生活中的点滴,你将发现更多的快乐与满足。",
},
{
"context": "师父,我对未来感到迷茫和恐惧,不知道自己的人生目标是什么,有何建议?",
"target": "阿弥陀佛,人生的方向不一定要一目了然,它是通过不断尝试和探索而逐渐清晰的。保持对未知的勇敢与开放,寻找自己内心的声音。用心去体验,用智慧去选择,你将找到属于自己的道路。",
}]
from tokenize_dataset_rows import preprocess
from datasets import Dataset
def preprocess(tokenizer, config, example, max_seq_length):
target = example["target"] # 从输入示例中获取目标文本(例如回复或下文)
history = None # 初始化历史变量,可用于处理上下文信息
# 构建 prompt,这里根据 tokenizer 是否有 build_prompt 方法来决定处理方式(兼容)
if hasattr(tokenizer, "build_prompt"):
prompt = tokenizer.build_prompt(example['context'], history)
else:
prompt = example["context"] # 如果没有 build_prompt 方法,直接使用上下文作为 prompt
# 对 prompt 进行编码,得到一系列 token ID(prompting部分)
a_ids = tokenizer.encode(text=prompt, add_special_tokens=True, truncation=True,
max_length=max_seq_length)
# 对目标文本进行编码,得到一系列 token ID(想让GLM学会的部分,不加 special_token 即不加最后那两个`ids`中bos=130001和gmask=130004)
b_ids = tokenizer.encode(text=target, add_special_tokens=False, truncation=True,
max_length=max_seq_length)
# 将编码后的 prompt 和目标文本的 token ID 连接起来,并添加一个结束符 token ID
input_ids = a_ids + b_ids + [tokenizer.eos_token_id]
# 返回处理后的数据,包括拼接后的 token ID 和序列长度
return {"input_ids": input_ids, "seq_len": len(a_ids)}
# 对数据集中的每个条目应用预处理函数
dataset = [preprocess(tokenizer, model.config, item, max_seq_length=256) for item in datas]
# 将预处理后的数据转换为 Dataset 对象,方便后续处理
dataset = Dataset.from_list(dataset)
此代码主要用于将文本数据转换为模型训练所需的格式。它首先将上下文和目标文本分别编码为 token ID,然后将这些 ID 连接起来,并在末尾添加一个结束符 token ID。最后,它将这些处理后的数据转换为 Dataset 对象,这种格式更适合用于训练机器学习模型。
from finetune import ModifiedTrainer, data_collator
from transformers import TrainingArguments
# 设置训练参数
training_args = TrainingArguments(
"output", # 模型输出和检查点的目录
fp16=True, # 是否使用半精度浮点数训练(可以减少内存使用,提高训练速度)
gradient_accumulation_steps=1, # 梯度累积步数,对于大批量尺寸的有效替代
per_device_train_batch_size=5, # 每个设备(如 GPU)的批量大小
learning_rate=1e-4, # 学习率(一半不大于原本模型的超参)
num_train_epochs=50, # 训练的总轮数
logging_steps=10, # 记录日志的步数间隔
remove_unused_columns=False, # 是否移除数据集中未使用的列
seed=0, # 随机种子,用于可复现性
data_seed=0, # 数据加载的随机种子
group_by_length=False, # 是否按长度对数据进行分组,以提高效率
)
# 创建 Trainer 实例
trainer = ModifiedTrainer(
model=model, # 要训练的模型
train_dataset=dataset, # 训练数据集
args=training_args, # 训练参数
data_collator=data_collator(tokenizer), # 数据整理函数
)
# 开始训练
trainer.train()

结果
这个脚本的主要目的是使用一个预训练的语言模型来自动生成文本。它首先为每个数据项构建一个 prompt,然后将这个 prompt 输入到模型中以生成文本。该过程使用 generate 方法,这是许多基于 Transformer 的语言模型的标准特性,用于生成文本序列。
import torch
model.config.use_cache = (
True # 启用模型的缓存机制以提高生成效率
)
for item in datas: # 遍历数据集中的每个项
# 构建 prompt(提示文本),这通常是生成任务的起始部分
if hasattr(tokenizer, "build_prompt"):
text = tokenizer.build_prompt(item['context'], None)
else:
text = item["context"] # 如果没有 build_prompt 方法,则直接使用上下文作为文本
# 将文本编码为模型可以理解的 token ID
ids = tokenizer.encode(text, return_tensors='pt')
# 使用模型生成响应。max_length 指定生成文本的最大长度
outs = model.generate(input_ids=ids, max_length=128)
# 解码生成的 token ID 为可读文本,并打印结果
print(tokenizer.batch_decode(outs)[0])
此代码假定 datas 是包含多个文本项目的数据集,其中每个项目都有一个 context 字段,这个字段被用作生成任务的起始点。此外,代码也考虑了 tokenizer 是否有 build_prompt 方法来自定义 prompt 的构建方式,这在某些特定的模型或应用场景中可能是必要的。
需要注意的是,文本生成的长度通过 max_length 参数控制,这个参数需要根据特定的应用场景进行适当的设置。此外,生成的文本质量很大程度上取决于模型的预训练质量和数据的相关性。
对比一下微调前和微调后



)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!