数据结构与算法—排序算法(一)时间复杂度和空间复杂度介绍
排序算法
1.排序算法的介绍
??排序也称为排序算法(Sort Algorithm),排序是将一组数据,依指定的顺序进行排序的过程。
1.1 排序的分类
- 内部排序
- 指将需要处理的所有数据都加载到**内部存储器(内存)**中进行排序。
- 外部排序法
- 数据量过大,无法全部加载到内存中,需要借助**外部存储(文件等)**进行排序

- 数据量过大,无法全部加载到内存中,需要借助**外部存储(文件等)**进行排序
2.算法的时间复杂度
2.1 度量一个程序(算法)执行时间的两种方法
-
事后统计的方法
- 这种方法可行,但是有两个问题:
- 是要想对设计的算法的运行性能进行评测,需要实际运行该程序。
- 是所得时间的统计量依赖于计算机的硬件、软件等环境因素,需要在同一要计算机的相同状态下运行,才能比较哪个算法速度更快
- 这种方法可行,但是有两个问题:
-
事前估算方法
- 通过分析某个算法的时间复杂度来判断哪个算法更优。
2.2 时间频度
- 基本介绍
- 一个算法花费的时间于算法中语句的执行次数成正比例,哪个算法中语句执行次数多,他花费时间就多。**一个算法中的语句执行次数称为语句频度或时间频度。**记为T(n)。
2.2.1 忽略常数项
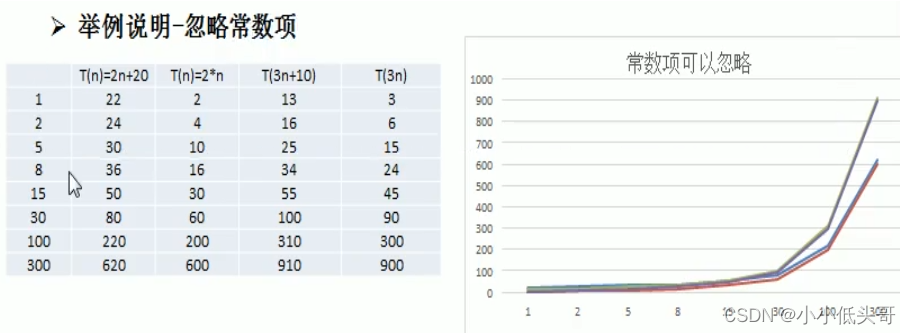
结论:
- 2n+20和2n随着n变大,执行曲线无限接近,20可以忽略。
- 3n+10和3n随着n变大,执行曲线无限接近,10可以忽略。
2.2.2 忽略低次项
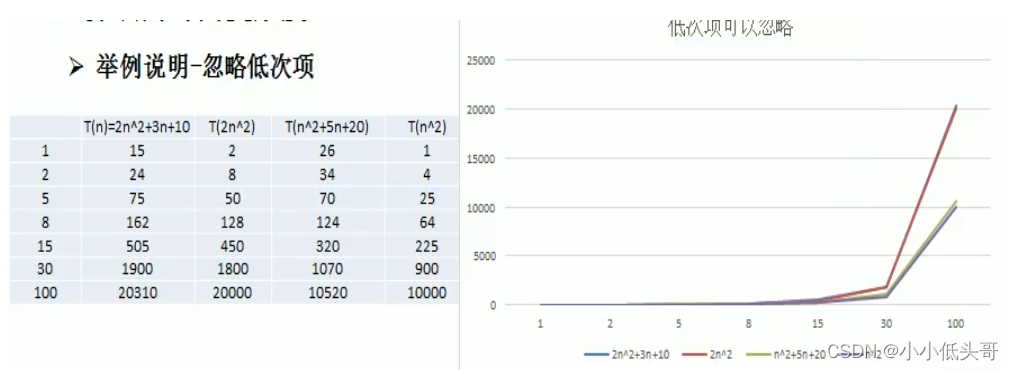
结论:
- 2n^2 + 3n + 10和2n^2随着n变大,执行曲线无限接近,可以忽略3n+10
- n^2 + 5n + 20和n^2随着n变大,执行曲线无限接近,可以忽略5n+20
2.2.3 忽略系数
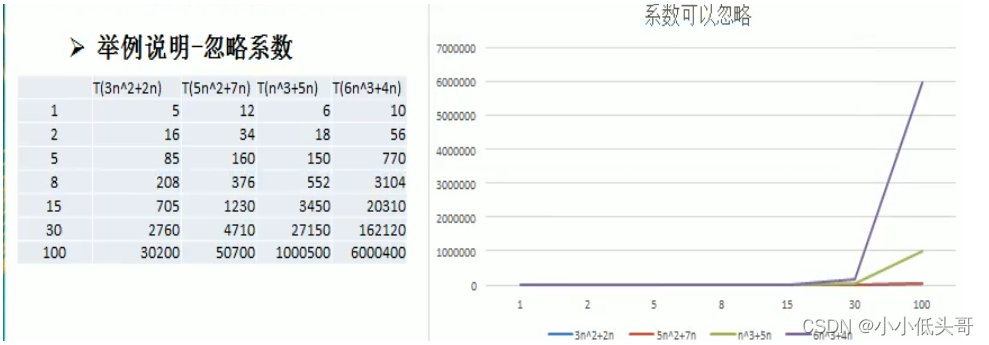
结论:
- 随着n值变大,5n^2+7n 和 3n^2+2n,执行曲线重合,说明这种情况下,5和3可以忽略。
- 而n^3 和 6n^3+4n,执行曲线分离,说明多少次方式关键。
2.3 时间复杂度
- 一般情况下,算法中的基本操作语句的重复执行次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n))为算法的渐进时间复杂度,简称时间复杂度。
- T(n)不同,但时间复杂度可能相同。如:T(n)=n^2+7n+6 与 T(n)=3n^2+2n+2它们的T(n)不同,但是时间复杂度相同, 都为O(n2)。
- 计算时间复杂度的方法
- 用常数1代替运行时间中的所有加法常数
- 修改后的运行次数函数中,只保留最高阶项
- 去除最高阶项的系数
2.3.1 常见的时间复杂度
常见算法时间复杂度由小到大为
- 常数阶 O ( 1 ) O(1) O(1)
- 对数阶 O ( l o g 2 n ) O(log_{2}n) O(log2?n)
- 线性阶 O ( n ) O(n) O(n)
- 线性对数阶 O ( n l o g 2 n ) O(nlog_{2}n) O(nlog2?n)
- 平方阶 O ( n 2 ) O(n^{2}) O(n2)
- 立方阶 O ( n 3 ) O(n^{3}) O(n3)
- k次方阶 O ( n k ) O(n^k) O(nk)
- 指数阶 O ( 2 n ) O(2^n) O(2n)
- 阶乘 O ( n ! ) O(n!) O(n!)
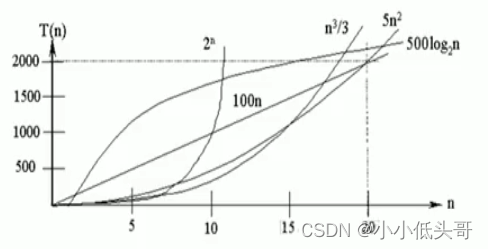
说明
- 随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越低。
- 由图5可见,应尽可能避免使用指数阶的算法。
2.3.1.1 常数阶 O ( 1 ) O(1) O(1)
? 无论代码执行了多少行,只要没有循环等复杂结构,那这个代码的时间复杂度就是 O ( 1 ) O(1) O(1)
int i = 1;
int j = 2;
i++;
j++;
int m = i + j;
上述代码在执行的时候,他消耗的时候并不随着某个变量的增长而增长,那么无论这类代码有多长,即使有几万几十万行,都可以用 O ( 1 ) O(1) O(1)来表示它的时间复杂度。(但是我的理解是时间频度应该不是1,而是5)
2.3.1.2 对数阶 O ( l o g 2 n ) O(log_{2}n) O(log2?n)
int i = 1;
while(i < n){
i = i * 2;
}
说明:在while循环里面,每次都将i乘以2,乘完之后,i距离n就越来越近了。假设循环x次之后,i就大于2了,此时这个循环就退出了,也就是说2的x次方等于n,那么 x = l o g 2 n x=log_2n x=log2?n也就是说当循环 l o g 2 n log_2n log2?n次以后,这个代码就结束了。因此这个代码的时间复杂度为: O ( l o g 2 n ) O(log_{2}n) O(log2?n)。 O ( l o g 2 n ) O(log_{2}n) O(log2?n)的这个2时间上是根据代码变化的,i=i* 3,则是 O ( l o g 3 n ) O(log_{3}n) O(log3?n)。
2.3.1.3 线性阶 O ( n ) O(n) O(n)
for(i = 1;i < n; ++i){
j = i;
j++;
}
说明:这段代码,for循环里面的代码会执行n遍,因此它消耗的时间是随着n的变化而变化的,因此这类代码都可以用o(n)来表示它的时间复杂度。
2.3.1.4 线性对数阶 O ( n l o g 2 n ) O(nlog_{2}n) O(nlog2?n)
for(m = 1;m < n;m++){
i = 1;
while(i < n){
i = i * 2;
}
}
说明:线性对数阶 O ( n l o g 2 n ) O(nlog_{2}n) O(nlog2?n)其实非常容易理解,将时间复杂度为 O ( l o g 2 n ) O(log_{2}n) O(log2?n)的代码循环N遍的话,那么它的时间复杂度就是 n ? l o g 2 n*log_{2} n?log2?,也就是了 O ( n l o g 2 n ) O(nlog_{2}n) O(nlog2?n)。
2.3.1.5 平方阶 O ( n 2 ) O(n^{2}) O(n2)
for(x = 1;i <= n;x++){
for(i = 1;i <= n; i++){
j = i;
j++;
}
}
说明:平方阶 O ( n 2 ) O(n^{2}) O(n2)就更容易理解了,如果把 O ( n ) O(n) O(n)的代码再嵌套循环一遍,它的时间复杂度就是 O ( n 2 ) O(n^{2}) O(n2),这段代码其实就是嵌套了2层n循环,它的时间复杂度就是, O ( n 2 ) O(n^{2}) O(n2)。即 O ( n 2 ) O(n^{2}) O(n2)如果将其中一层循环的n改成m,那它的时间复杂度就变成了 O ( n ? m ) O(n*m) O(n?m)。
2.3.2 平均时间复杂度和最坏时间复杂度
- 平均时间复杂度是指所有可能的输入实例均以等概率出现的情况下,该算法的运行时间。
- 最坏情况下的时间复杂度称最坏时间复杂度。一般讨论的时间复杂度均是最坏情况下的时间复杂度。这样做的原因是:最坏情况下的时间复杂度是算法在任何输入实例上运行时间的界限,这就保证了算法的运行时间不会比最坏情况更长。
- 平均时间复杂度和最坏时间复杂度是否一致,和算法有关(如图6)。
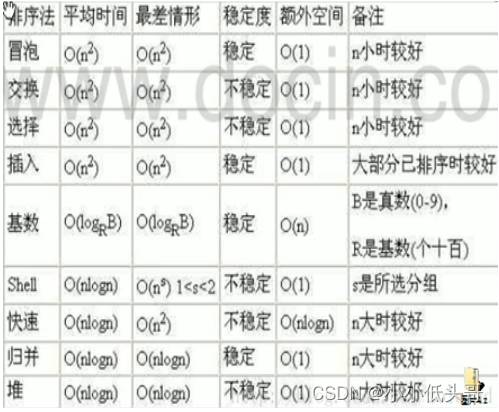
3. 算法的空间复杂度
基本介绍:
- 类似于时间复杂度的讨论,一个算法的空间复杂度(Space Complexity)定义为该算法所耗费的存储空间,它也是问题规模n的函数。
- 空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间大小的量度。有的算法需要占用的临时工作单元数与解决问题的规模n有关,它随着n的增大而增大,当n较大时,将占用较多的存储单元,例如快速排序和归并排序算法就属于这种情况
- 在做算法分析时,主要讨论的是时间复杂度。从用户使用体验上看,更看重的程序执行的速度。一些缓存产品(redis, memcache)和算法(基数排序)本质就是用空间换时间.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!