阿里云大模型数据存储解决方案,为 AI 创新提供推动力
云布道师
随着国内首批大模型产品获批名单问世,百“模”大战悄然开启。在这场百“模”大战中,每一款大模型产品的诞生,都离不开数据的支撑。如何有效存储、管理和处理海量多模态数据集,并提升模型训练、推理的效率,保障 AI 业务平台运行的稳定,仍是亟待解决的难题。在云栖大会上,阿里云推出一系列针对大模型场景的存储产品创新。这些产品通过利用 AI 技术赋能 AI 业务,可以帮助用户更轻松地管理大规模多模态数据集,提高模型训练、推理的效率和准确性。同时,这些产品还支持高可用性、可扩展性和安全性,满足不同用户的个性化需求。
为 AI 算力提速的存储服务
在实际生产过程中,AI 场景分为训练和推理两个流程。其中训练环节需要消耗大量的算力,为了提升算力资源的生产效率,对于数据集和 checkpoint 的读写加速至关重要。阿里云文件存储 CPFS 采用全并行 IO 架构,数据和元数据分片存储在所有节点上,单文件读写可以利用所有节点带宽,同时 CPFS 的弹性文件客户端可以利用近计算端缓存,进一步加速数据集和 checkpoint 读写。产品性能指标最高提供 20TB/s 吞吐和 3 亿 IOPS,在超大规模训练场景下,也能快速完成 checkpoint 读写,加速 AI 训练。
本次云栖大会发布的通义千问最新大模型产品,模型参数达到 2,000 亿级别,在训练过程中使用 CPFS 承载训练用数据集和 checkpoint 的存储。在千卡规模下,数据集的加载吞吐达到数百 GB/s,checkpoint 写入吞吐近百 GB/s,结合计算侧缓存加速,显著提升了模型训练效率。
在大规模推理环节时,需要多台 GPU 协同处理,需要短时间内加载模型文件至所有 GPU 服务器的内存。阿里云对象存储 OSS 推出加速器 2.0 功能,以应对存储在对象存储 OSS 中大模型的加载需求。OSS 加速器 2.0 具有高效、灵活和易于使用的特点,提供了对象 RESTful API 和 OSSFS 两种访问方式,让用户无需修改原有的应用程序,便可快速读取模型文件。OSS 加速器 2.0 内嵌于 OSS 服务中,数据无需进行搬迁就能够为热模型文件按需提供自动伸缩的弹性吞吐性能,且实现了按量付费。这样,无论是业务高峰还是低谷,用户都能够灵活应对,无需担心资源的浪费。
对于使用文件存储保存模型文件的客户。文件存储 NAS 推出的高级型规格可以提供低延迟数据访问的同时,降低使用成本 54%。弹性文件客户端 EFC 结合容器服务 ACK,提供了计算端分布式缓存池,并可以通过 P2P 技术充分利用多机带宽。在多机推理方案中,为模型热文件提供超大吞吐的拉取能力,缩短模型准备时间。
在整个大模型的业务流程当中,存储数据量庞大,且面对不同流程阶段时,上层应用需要使用不同的数据格式,极为容易发生数据孤岛的情况。阿里云利用对象存储 OSS 的能力,构建统一的数据湖存储,利用对象存储 OSS 的海量扩展、低成本的存储能力,搭建 AI 场景数据存储底座。
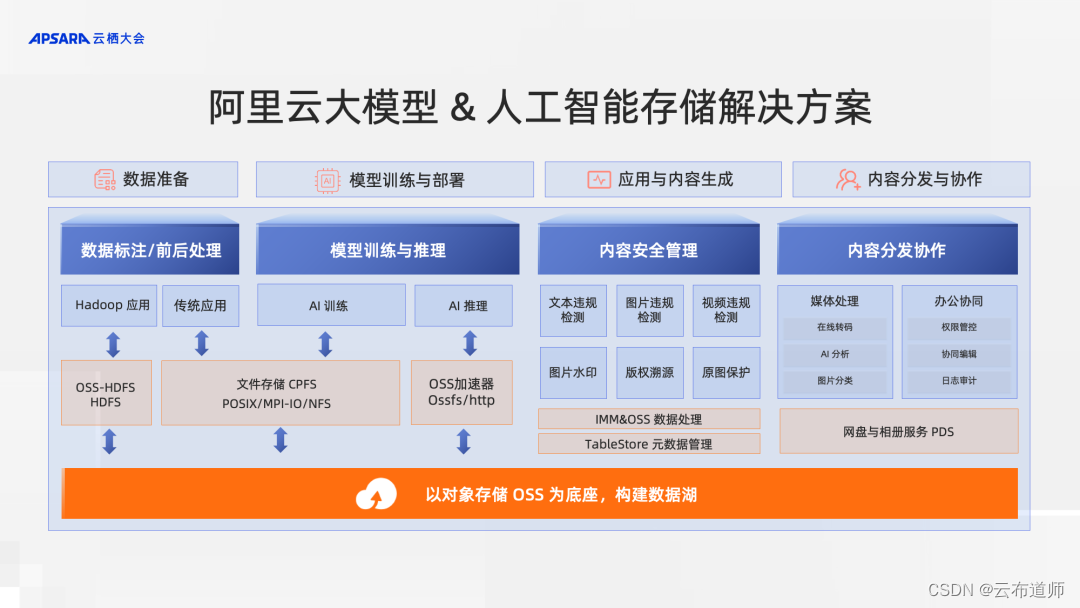
让 AI 数据高效组织
大模型表现出的优异能力,离不开大规模数据的支撑。若把大模型类比为学生的话,供其训练的素材集就是一本本教材。在训练过程中,该如何优化数据集,避免出现“毒教材”的现象发生。只有高质量的数据集才能实现高质量的训练和微调。
数据标签是数据集的重要元数据。在训练过程中,用户往往会发现标签数量过多,但是对素材的描述能力还是不足。这是因为堆积的标签数量无法满足业务需求,因此需要采用“原子标签+语义标签”的方式,以提高素材理解的深度。为了达到这个能力,阿里云也在不断地进行数据索引和检索能力的革新。针对不同业务需求与研发能力的客户,阿里云为其提供了三种数据索引和检索的方法。

针对用户简单静态标签数据检索的需求,阿里云 OSS 提供了 MetaQuery 的能力,能够实现、秒级查询海量数据。同时,OSS MetaQuery 提供了多种索引条件,覆盖九大类数据类型,与 OSS 的标签能力相结合,满足了用户的数据多维查询和管理的基本需求。
对于需要高性能检索且追求更低成本的用户而言,阿里云表格存储 Tablestore 为元数据存储和检索提供了卓越的性能和可靠性。Tablestore 是一种 Serverless 化元数据存储系统,支持线上实时查询,目前又提供了向量存储格式、向量检索,从而进一步实现对图、文、音、视的语义检索与传统检索相结合的查询功能。在索引查询方面,表格存储Tablestore 可支持毫秒级的响应速度,并可平滑扩展索引规模,无上限。
若用户既想享受到高性能的索引与检索服务,又不想投入过多研发资源,阿里云利用智能媒体管理 IMM,为其提供一站式服务化元数据管理服务。IMM 利用阿里云的 AI 能力理解富媒体文件的内容,抽取 AI 标签和 Embeding 存储到元数据库中,并利用大语言模型理解用户的自然语言查询,转化为内部的指令,更高效地帮助用户进行检索数据。阿里云将 FPGA 敏捷算力部署在对象存储 OSS 附近。通过这种方式,阿里云为用户的海量数据提供了更快捷、更智能、更节约的索引与检索服务,助力用户实现更高效的业务运营。
AIOps 让 AI 平台运行更加高效
在当今市场竞争日趋激烈的时代,AI 产品的用户体验已经成为了企业竞争力的核心所在。而对于那些运用人工智能技术的企业来说,不断的产品迭代已经成为了一种不可避免的趋势。企业不能让业务带“伤”运行,只有稳定且平滑的应用与计算任务,才能带给用户优质的产品体验。
阿里云日志服务 SLS 致力于打造高效、可观测的运维解决方案,凭借其多年的运维经验以及大语言模型的支持,不断提升其在此领域 的竞争力。SLS 发布智能运维基础模型,覆盖 Log、Trace、Metric 等可观测数据场景。模型提供开箱即用的异常检测、自动标注、分类和根因分析等能力。支持秒级在数千请求内定位到根因,在生产中准确率达 95% 以上。支持自动标注人工辅助微调,支持人工标注结果打标修正,模型根据人工反馈自动微调,提升场景准确率。
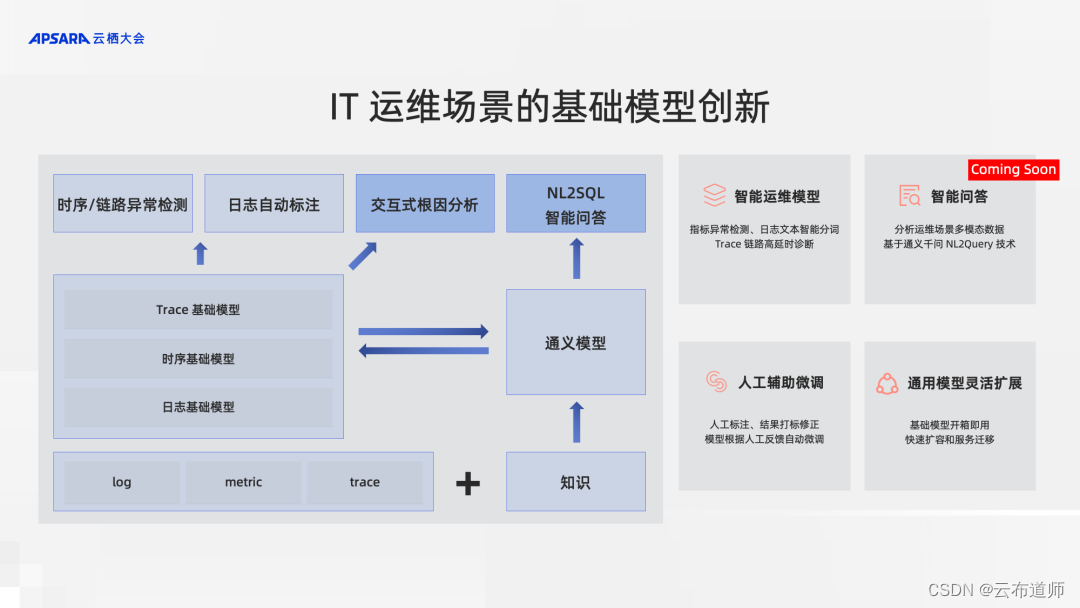
此外,SLS 还提供智能问答的能力,即 Alibaba CloudLens Copilot 大模型助力云设施运维与运营。采用基于大语言模型的 NL2Query 技术,精准理解用户的查询意图,提高查询结果准确性;无需理解复杂的 SQL 语言和查询语法,可准确将自然语言查询转化为 SQL 查询和可视化图表;建立场景化的知识图谱,持续学习,不断优化模型调整和知识库更新,不断改进问题解答的准确性和效果。
随着大模型产品的快速发展,数据的存储、管理和处理成为了不可忽视的重要问题。阿里云通过不断创新和优化,推出了一系列针对大模型场景优化的数据存储与管理方案,帮助用户更好地管理和处理海量多模态数据集,提高模型训练的效率、准确性以及降低成本支出。同时,这些方案还支持高可用性、可扩展性和安全性,满足不同用户的个性化需求。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!