Java大数据hadoop2.9.2搭建伪分布式yarn资源管理器
2024-01-07 17:25:20
1、修改配置文件
cd /usr/local/hadoop/etc/hadoop
cp ./mapred-site.xml.template ./mapred-site.xml
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>2、重新启动hadoop
停止hadoop
stop-dfs.sh
打开hadoop和yarn资源管理器
start-all.sh
3、运行统计
cd?/usr/local/hadoop/share/hadoop/mapreduce/
执行下方
hadoop jar ./hadoop-mapreduce-examples-2.9.2.jar wordcount /demo /demo/output
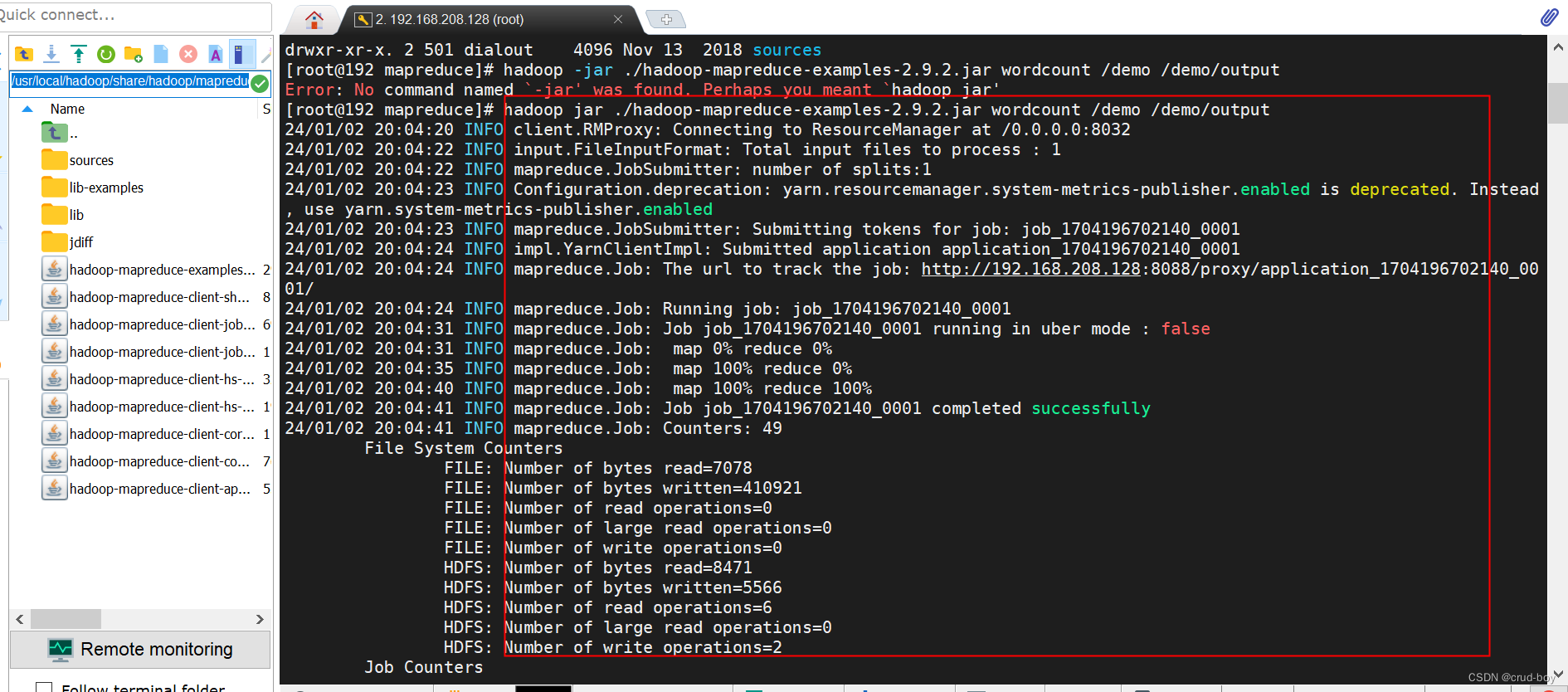
执行单词统计的任务,统计之前上传到hadoop的一个文件,把统计的输出到output文件夹
另外可以在浏览器输入ip:8088,查看任务的状态
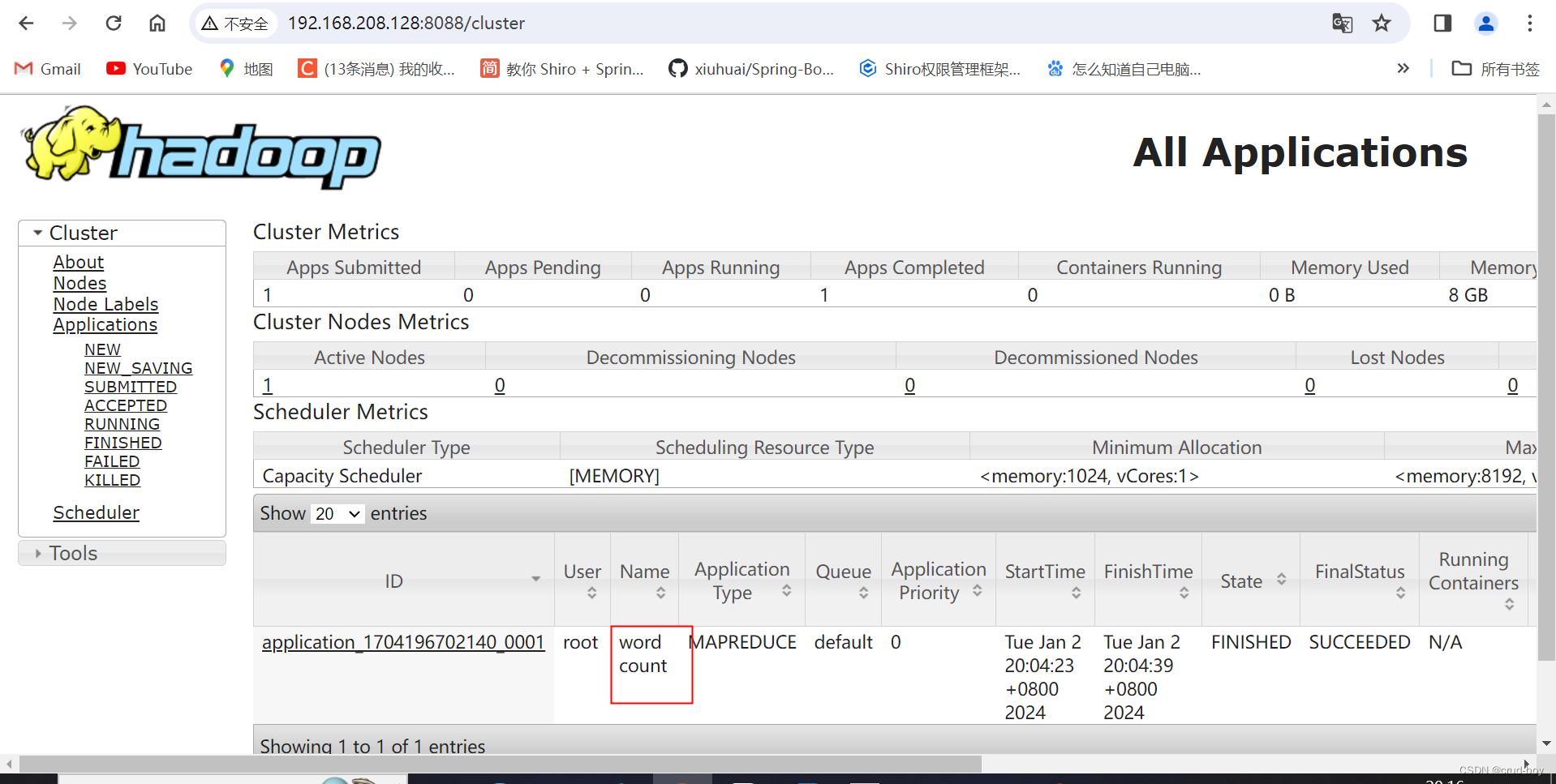
后面可在hadoop的web页面查看到文件
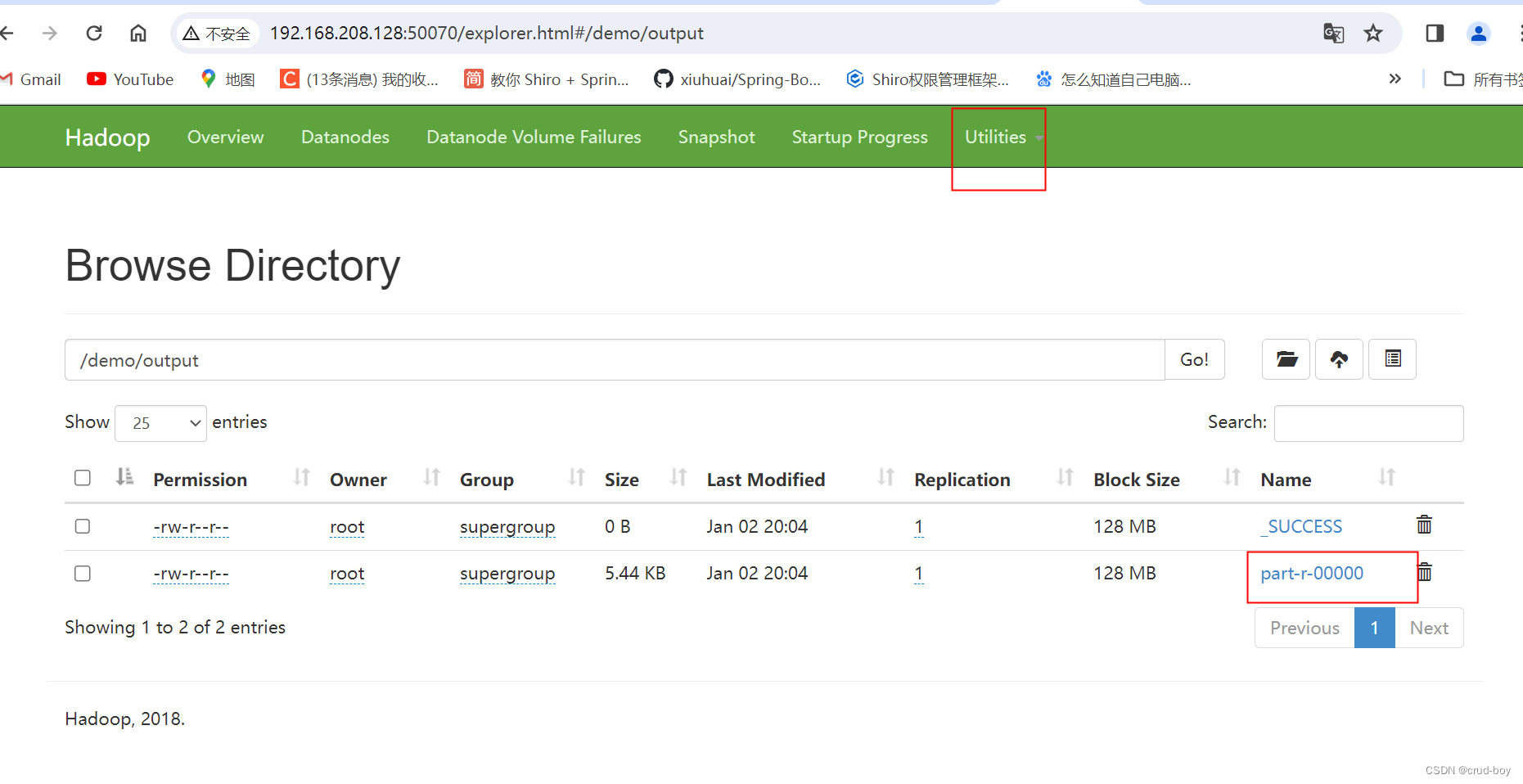
在Linux系统输入下方命令可以查看任务执行打印的内容
hdfs dfs -cat /demo/output/part-r-00000
文章来源:https://blog.csdn.net/bgy1996/article/details/135348283
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!