Python大数据之PySpark(七)SparkCore案例
2023-12-13 11:35:25
SparkCore案例
PySpark实现SouGou统计分析
jieba分词:
pip install jieba 从哪里下载pypi
三种分词模式
精确模式,试图将句子最精确地切开,适合文本分析;默认的方式
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
# -*- coding: utf-8 -*- # Program function:测试结巴分词 import jieba import re # jieba.cut # 方法接受四个输入参数: # 需要分词的字符串; # cut_all 参数用来控制是否采用全模式; # HMM 参数用来控制是否使用 HMM 模型; # use_paddle 参数用来控制是否使用paddle模式下的分词模式,paddle模式采用延迟加载方式,通过enable_paddle接口安装paddlepaddle-tiny,并且import相关代码; str = "我来到北京清华大学" print(list(jieba.cut(str))) # ['我', '来到', '北京', '清华大学'],默认的是精确模式 print(list(jieba.cut(str, cut_all=True))) # ['我', '来到', '北京', '清华', '清华大学', '华大', '大学'] 完全模式 # 准备的测试数据 str1 = "00:00:00 2982199073774412 [360安全卫士] 8 3 download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html" print(re.split("\s+", str1)[2]) # [360安全卫士] print(re.sub("\[|\]", "", re.split("\s+", str1)[2])) #360安全卫士 print(list(jieba.cut(re.sub("\[|\]", "", re.split("\s+", str1)[2])))) # [360安全卫士] --->['360', '安全卫士']
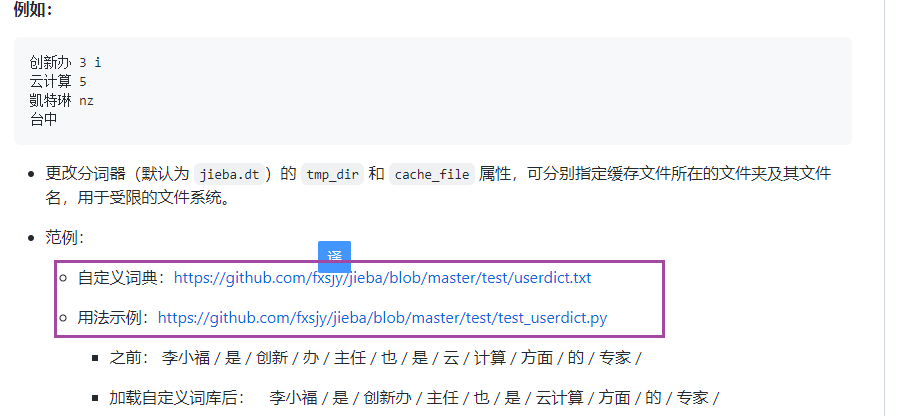
数据认知:数据集来自于搜狗实验室,日志数据
日志库设计为包括约1个月(2008年6月)Sogou搜索引擎部分网页查询需求及用户点击情况的网页查询日志数据集合。
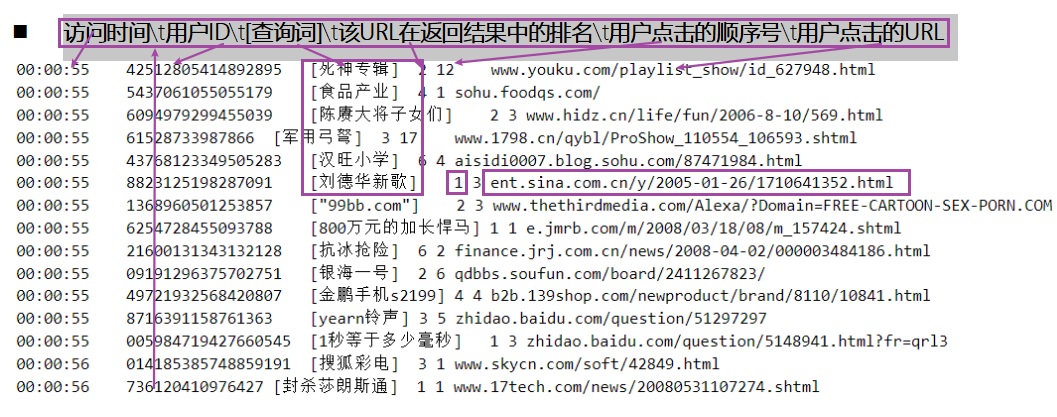
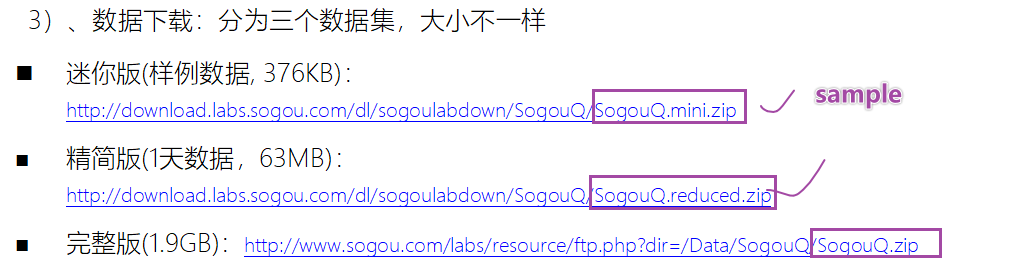
需求
1-首先需要将数据读取处理,形成结构化字段进行相关的分析
2-如何对搜索词进行分词,使用jieba或hanlp
jieba是中文分词最好用的工具
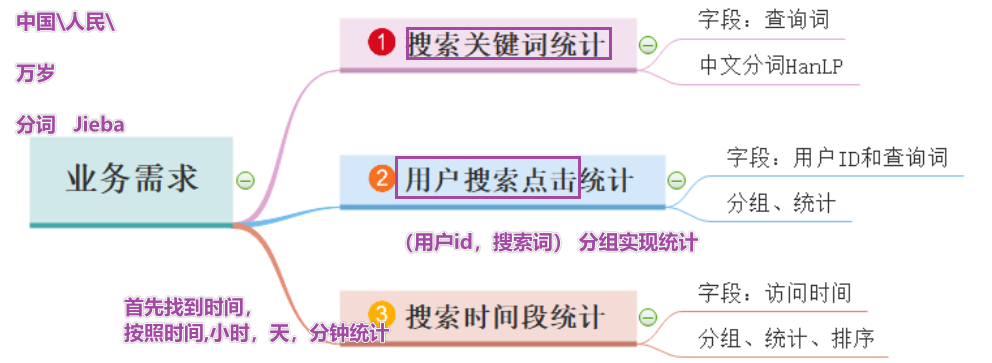
步骤
1-读取数据
2-完成需求1:搜狗关键词统计
3-完成需求2:用户搜索点击统计
4-完成需求3:搜索时间段统计
5-停止sparkcontext
代码
# -*- coding: utf-8 -*- # Program function:搜狗分词之后的统计 ''' * 1-读取数据 * 2-完成需求1:搜狗关键词统计 * 3-完成需求2:用户搜索点击统计 * 4-完成需求3:搜索时间段统计 * 5-停止sparkcontext ''' from pyspark import SparkConf, SparkContext import re import jieba if __name__ == '__main__': # 准备环境变量 conf = SparkConf().setAppName("sougou").setMaster("local[*]") sc = SparkContext.getOrCreate(conf=conf) sc.setLogLevel("WARN") # TODO*1 - 读取数据 sougouFileRDD = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/sougou/SogouQ.reduced") # print("sougou count is:", sougouFileRDD.count())#sougou count is: 1724264 # 00:00:00 2982199073774412 [360安全卫士] 8 3 download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html resultRDD=sougouFileRDD \ .filter(lambda line:(len(line.strip())>0) and (len(re.split("\s+",line.strip()))==6))\ .map(lambda line:( re.split("\s+", line)[0], re.split("\s+", line)[1], re.sub("\[|\]", "", re.split("\s+", line)[2]), re.split("\s+", line)[3], re.split("\s+", line)[4], re.split("\s+", line)[5] )) # print(resultRDD.take(2)) #('00:00:00', '2982199073774412', '360安全卫士', '8', '3', 'download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html') #('00:00:00', '07594220010824798', '哄抢救灾物资', '1', '1', 'news.21cn.com/social/daqian/2008/05/29/4777194_1.shtml') # TODO*2 - 完成需求1:搜狗关键词统计 print("=============完成需求1:搜狗关键词统计==================") recordRDD = resultRDD.flatMap(lambda record: jieba.cut(record[2])) # print(recordRDD.take(5)) sougouResult1=recordRDD\ .map(lambda word:(word,1))\ .reduceByKey(lambda x,y:x+y)\ .sortBy(lambda x:x[1],False) # print(sougouResult1.take(5)) # TODO*3 - 完成需求2:用户搜索点击统计 print("=============完成需求2:用户搜索点击统计==================") # 根据用户id和搜索的内容作为分组字段进行统计 sougouClick = resultRDD.map(lambda record: (record[1], record[2])) sougouResult2=sougouClick\ .map(lambda tuple:(tuple,1))\ .reduceByKey(lambda x,y:x+y) #key,value # 打印一下最大的次数和最小的次数和平均次数 print("max count is:",sougouResult2.map(lambda x: x[1]).max()) print("min count is:",sougouResult2.map(lambda x: x[1]).min()) print("mean count is:",sougouResult2.map(lambda x: x[1]).mean()) # 如果对所有的结果排序 # print(sougouResult2.sortBy(lambda x: x[1], False).take(5)) # TODO*4 - 完成需求3:搜索时间段统计 print("=============完成需求3:搜索时间段-小时-统计==================") #00:00:00 hourRDD = resultRDD.map(lambda x: str(x[0])[0:2]) sougouResult3=hourRDD\ .map(lambda word:(word,1))\ .reduceByKey(lambda x,y:x+y)\ .sortBy(lambda x:x[1],False) print("搜索时间段-小时-统计",sougouResult3.take(5)) # TODO*5 - 停止sparkcontext sc.stop()

总结
- 重点关注在如何对数据进行清洗,如何按照需求进行统计
- 1-rdd的创建的两种方法,必须练习
- 2-rdd的练习将基础的案例先掌握。map。flatMap。reduceByKey
- 3-sougou的案例需要联系2-3遍
- 练习流程:
- 首先先要将代码跑起来
- 然后在理解代码,这一段代码做什么用的
- 在敲代码,需要写注释之后敲代码
AI副业实战手册:http://www.yibencezi.com/notes/253200?affiliate_id=1317(目前40+工具及实战案例,持续更新,实战类小册排名第一,做三个月挣不到钱找我退款,交个朋友的产品)
后记
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ?留言 📝 如有错误敬请指正!
📢本文由 Maynor 原创,首发于 CSDN博客🙉
📢感觉这辈子,最深情绵长的注视,都给了手机?
📢专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12453356.html
文章来源:https://blog.csdn.net/xianyu120/article/details/133655756
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!