谷歌DeepMind最新研究:对抗性攻击对人类也有效,人类和AI都会把花瓶认成猫!
人类的神经网络(大脑)和人工神经网络(ANN)的关系是什么?
有位老师曾经这样比喻:就像是老鼠和米老鼠的关系。
现实中的神经网络功能强大,但与人类的感知、学习和理解方式完全不同。
比如ANN表现出人类感知中通常没有的脆弱性,它们容易受到对抗性扰动的影响。
一个图像,可能只需修改几个像素点的值,或者添加一些噪声数据,
从人类的角度,观察不到区别,而对于图像分类网络,就会识别成完全无关的类别。
不过,谷歌DeepMind的最新研究表明,我们之前的这种看法可能是错误的!
即使是数字图像的细微变化也会影响人类的感知。
换句话说,人类的判断也会受到这种对抗性扰动的影响。

论文地址:https://www.nature.com/articles/s41467-023-40499-0
谷歌DeepMind的这篇文章发表在《自然通讯》(Nature Communications)。
论文探索了人类是否也可能在受控测试条件下,表现出对相同扰动的敏感性。
通过一系列实验,研究人员证明了这一点。
同时,这也显示了人类和机器视觉之间的相似性。
对抗性图像
对抗性图像是指对图像进行微妙的更改,从而导致AI模型对图像内容进行错误分类,——这种故意欺骗被称为对抗性攻击。
例如,攻击可以有针对性地使AI模型将花瓶归类为猫,或者是除花瓶之外的任何东西。

上图展示了对抗性攻击的过程(为了便于人类观察,中间的随机扰动做了一些夸张)。
在数字图像中,RGB图像中的每个像素的取值在0-255之间(8位深度时),数值表示单个像素的强度。
而对于对抗攻击来说,对于像素值的改变在很小的范围内,就可能达到攻击效果。
在现实世界中,对物理对象的对抗性攻击也可能成功,例如导致停车标志被误识别为限速标志。
所以,出于安全考虑,研究人员已经在研究抵御对抗性攻击和降低其风险的方法。
对抗性影响人类感知
先前的研究表明,人们可能对提供清晰形状线索的大幅度图像扰动很敏感。
然而,更细致的对抗性攻击对人类有何影响?人们是否将图像中的扰动视为无害的随机图像噪声,它会影响人类的感知吗?
为了找到答案,研究人员进行了受控行为实验。
首先拍摄一系列原始图像,并对每张图像进行了两次对抗性攻击,以产生多对扰动图像。
在下面的动画示例中,原始图像被模型归类为「花瓶」。
而由于对抗性攻击,模型以高置信度将受到干扰的两幅图像进行错误分类,分别为「猫」和「卡车」。

接下来,向人类参与者展示这两张图片,并提出了一个有针对性的问题:哪张图片更像猫?
虽然这两张照片看起来都不像猫,但他们不得不做出选择。
通常,受试者认为自己随意做出了选择,但事实果真如此吗?
如果大脑对微妙的对抗性攻击不敏感,则受试者选择每张图片的概率为50%。
然而实验发现,选择率(即人的感知偏差)要实实在在的高于偶然性(50%),而且实际上图片像素的调整是很少的。
从参与者的角度来看,感觉就像他们被要求区分两个几乎相同的图像。然而,之前的研究表明,人们在做出选择时会利用微弱的感知信号,——尽管这些信号太弱而无法表达信心或意识。
在这个的例子中,我们可能会看到一个花瓶,但大脑中的一些活动告诉我们,它有猫的影子。
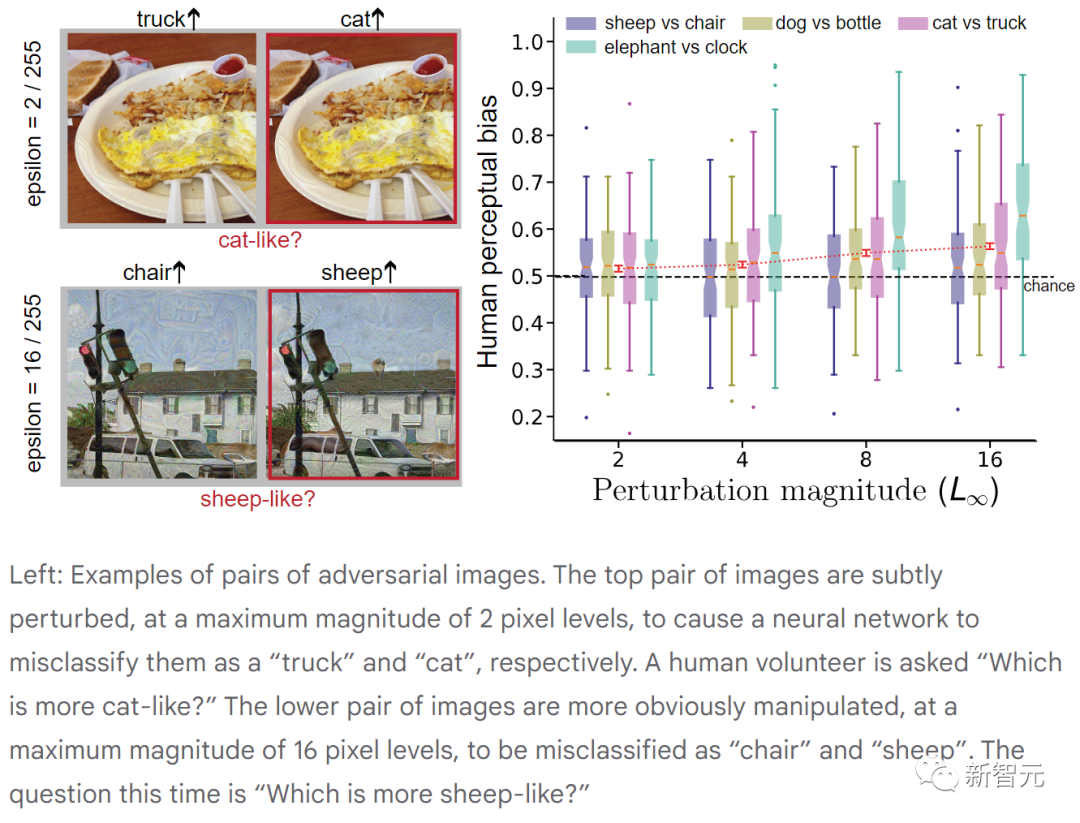
上图展示了成对的对抗图像。最上面的一对图像受到微妙的扰动,最大幅度为2个像素,导致神经网络将它们分别错误地分类为「卡车」和「猫」。(志愿者被问到「哪个更像猫?」)
下边的一对图像扰动更明显,最大幅度为16像素,被神经网络错误地归类为「椅子」和「羊」。(这次的问题是「哪个更像绵羊?」)
在每个实验中,参与者在一半以上的时间里可靠地选择了与目标问题相对应的对抗图像。虽然人类视觉不像机器视觉那样容易受到对抗性扰动的影响,但这些扰动仍然会使人类偏向于机器做出的决定。
如果人类的感知可能会受到对抗性图像的影响,那么这将是一个全新的但很关键的安全问题。
这需要我们深入研究探索人工智能视觉系统行为和人类感知的异同,并构建更安全的人工智能系统。
论文细节
生成对抗性扰动的标准程序从预训练的ANN分类器开始,该分类器将RGB图像映射到一组固定类上的概率分布。
对图像的任何更改(例如增加特定像素的红色强度)都会对输出概率分布产生轻微变化。
对抗性图像通过搜索(梯度下降)来获得原始图像的扰动,该扰动导致 ANN 降低分配给正确类别的概率(非针对性攻击)或将高概率分配给某些指定的替代类别(针对性攻击)。
为了确保扰动不会偏离原始图像太远,在对抗性机器学习文献中经常应用L (∞) 范数约束,指定任何像素都不能偏离其原始值超过±ε,ε通常远小于 [0–255] 像素强度范围。
该约束适用于每个RGB颜色平面中的像素。虽然这种限制并不能阻止个体检测到图像的变化,但通过适当选择ε,在受扰动的图像中指示原始图像类别的主要信号大多完好无损。
实验
在最初的实验中,作者研究了人类对短暂、遮蔽的对抗性图像的分类反应。
通过限制暴露时间来增加分类错误,该实验旨在提高个体对刺激物某些方面的敏感度,否则这些刺激物可能不会影响分类决策。
对真实类别T的图像进行了对抗性扰动,通过对扰动进行优化,使ANN倾向于将图像错误分类为A。参与者被要求在T和A之间做出强制选择。
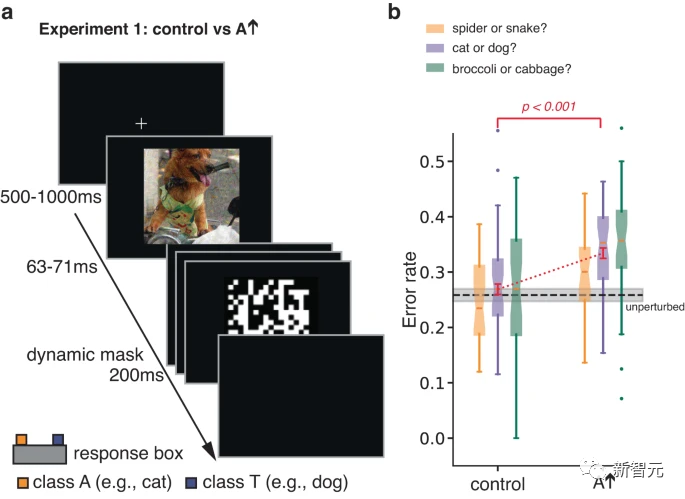
研究人员还在对照图像上对参与者进行了测试,对照图像是通过自上而下翻转在A条件下获得的对抗性扰动图像形成的。
这种简单的转换打破了对抗性扰动与图像之间像素到像素的对应关系,在很大程度上消除了对抗性扰动对ANN的影响,同时保留了扰动的规范和其他统计数据。
结果表明,与对照组图像相比,参与者更有可能将扰动图像判断为A类别。
上面的实验1使用了简短的遮蔽演示,以限制原始图像类别(主要信号)对反应的影响,从而揭示对对抗性扰动(从属信号)的敏感性。
研究人员还设计了另外三个具有相同目标的实验,但避免了大范围扰动和有限曝光观看的需要。
在这些实验中,图像中的主要信号不能系统地引导反应选择,从而使从属信号的影响得以显现。
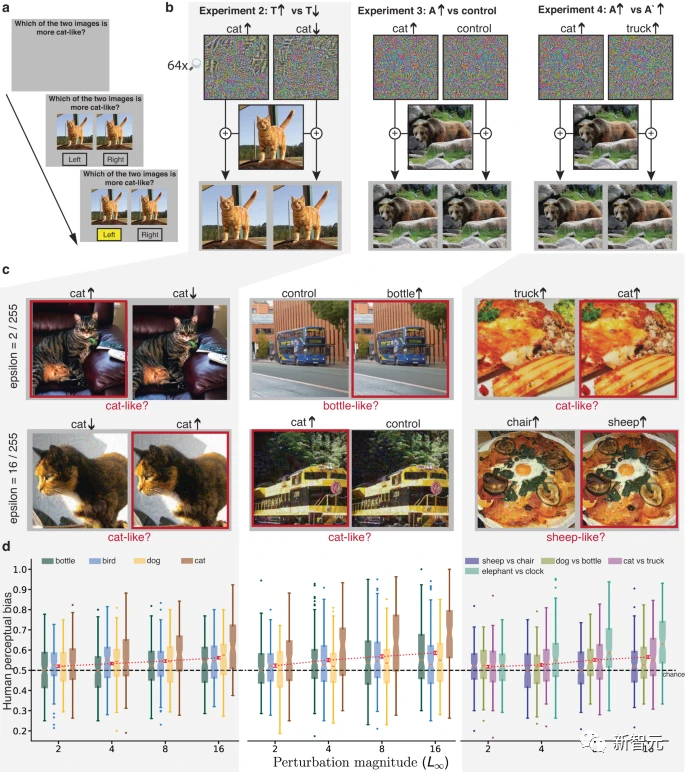
在每个实验中,都会出现一对几乎相同的未遮蔽刺激物,并且在选择反应之前一直保持可见。这对刺激物具有相同的主导信号,它们都是对同一底层图像的调制,但具有不同的从属信号。参与者需要选择更像目标类别实例的图像。
在实验2中,两个刺激物都是属于T类的图像,其中一个经过扰动,ANN预测它更像T类,另一个经过扰动,被预测为更不像T类。
在实验3中,刺激物是一幅属于真实类别T的图像,其中一幅被扰动以改变ANN的分类,使其向目标对抗类别A靠拢,另一幅则使用相同的扰动,但左右翻转作为对照条件。
这种对照的作用是保留扰动的规范和其他统计量,但比实验1中的对照更为保守,因为图像的左右两边可能比图像的上下部分具有更相似的统计量。
实验4中的一对图像也是对真实类别T的调制,一个被扰动得更像A类,一个更像第三类。试验交替要求参与者选择更像A的图像,或者更像第三类的图像。
在实验2-4中,每张图像的人类感知偏差与ANN的偏差显著正相关。扰动幅度从2到16不等,小于以前对人类参与者研究的扰动,并且与对抗性机器学习研究中使用的扰动相似。
令人惊讶的是,即使是2个像素强度水平的扰动也足以可靠地影响人类感知。
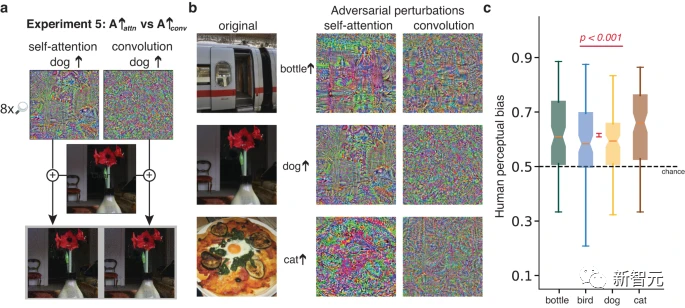
实验2的优势在于要求参与者做出直觉判断(例如,两张被扰动的猫图像中哪一个更像猫);
然而,实验2允许对抗性扰动仅通过锐化或模糊图像,即可使图像或多或少像猫一样。
实验3的优势在于,匹配了所比较的扰动的所有统计数据,而不仅仅是扰动的最大幅度。
但是,匹配扰动统计并不能确保扰动在添加到图像中时同样可感知,因此,参与者可能根据图像失真进行选择。
实验4的优势在于,它证明了参与者对被问的问题很敏感,因为相同的图像对会根据提出的问题产生系统性不同的回答。
然而,实验4要求参与者回答一个看似荒谬的问题(例如,两个煎蛋卷图像中的哪一个看起来更像猫?),导致问题解释方式的可变性。
综上所述,实验2-4提供了趋于一致的证据,表明即使扰动幅度非常小,且观看时间不受限制,对人工智能网络产生强烈影响的从属对抗信号,也会在相同方向上影响人类的感知和判断。
此外,延长观察时间(自然感知的环境),是对抗性扰动产生实际后果的关键。
参考资料:
https://deepmind.google/discover/blog/images-altered-to-trick-machine-vision-can-influence-humans-too/

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!