目标检测-One Stage-YOLOx
文章目录
前言
根据前文CenterNet、YOLOv4等可以看出学界和工业界都在积极探索使用各种tricks(anchor-free、各种组件、数据增强技术等等)来改进One Stage网络的表现,2021年旷视科技结合先进的改进技巧,产出了多种改进模型,在多种情况下达到速度和精度的SOTA。
值得一提的是,YOLOx使得YOLO系列回归到了anchor-free(YOLOv1是anchor-free的),后续YOLOv6、YOLOv7、YOLOv8均为anchor-free算法
提示:以下是本篇文章正文内容,下面内容可供参考
一、YOLOx的网络结构和流程
1.YOLOx的不同版本
YOLOx给出了以下版本:
(1)标准网络结构:Yolox-Darknet53、Yolox-s、Yolox-m、Yolox-l、Yolox-x。
(2)轻量级网络结构:Yolox-Nano、Yolox-Tiny
ps:
- 选择Yolov3_spp的改进版作为Yolov3 baseline,在此基础上添加各种trick,比如Decoupled Head、SimOTA等,得到了Yolox-Darknet53版本
- 以Yolov5的四个版本作为baseline,采用有效的trick,逐一进行改进,得到Yolox-s、Yolox-m、Yolox-l、Yolox-x四个版本
- 设计了Yolox-Nano、Yolox-Tiny轻量级网络,并测试了一些trick的适用性
2.Yolox-Darknet53
YOLOv3 baseline
- 采用了YOLOv3-SPP网络(在YOLOv3 backbone后面加入了SPP层)。
- 采用了新的训练策略:EMA权值更新、cosine学习率机制、IoU损失、IoU感知分支
- 数据增强:仅使用RandomHorizontalFlip(翻转)、ColorJitter(对比度、亮度等)、多尺度数据增强,移除了RandomResizedCrop(随机裁剪),因为发现其和planned mosaic augmentation功能上有重叠。
基于上述训练技巧,基线模型在COCO val上取得了38.5%AP指标
ps:和CenterNet不同的是,Yolox分为cls、reg以及obj分支,其中
- cls代表分类任务,主要负责预测图像中物体的类别,使用BCE损失
- reg代表回归任务,主要负责预测物体的位置和尺寸信息,使用IoU损失
- obj代表目标存在性任务(IoU感知分支),即模型需要判断边框中是否存在目标物体(置信度),使用BCE损失

Yolox-Darknet53
Yolox-Darknet53在YOLOv3 baseline基础上再次采用了以下五种tricks:
Decoupled head:检测头由Head修改为Decoupled Head,提升了收敛速度和精度,但同时会增加复杂度
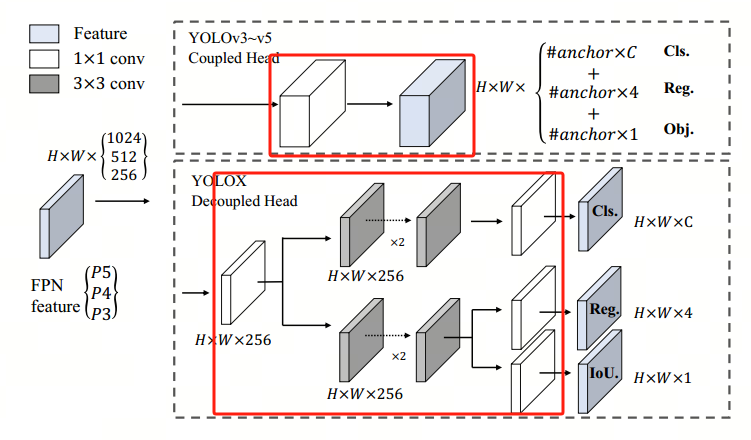
Strong data augmentation:使用了Mosaic和MixUp,同时在使用强大的数据增强后,发现ImageNet预训练不再有益,因此从头开始训练所有模型Anchor-free:类似CenterNet的思想Multi positives:类似CenterNet的anchor-free仅为每个对象选择一个正样本(中心位置),同时忽略其他高质量预测,然而,优化这些高质量的预测也可以带来有益的梯度,缓解训练期间正/负采样的极端不平衡,因此YOLOx将中心3×3区域都分配为正样本SimOTA:一种标签匹配方法,标签分配是近年来目标检测领域的另一个重要进展。所谓标签匹配实质上就是将预测框和真实(gt)框进行匹配,简单做法是基于阈值,如IoU,但这种做法比较粗糙。
将精度推至47.3 AP
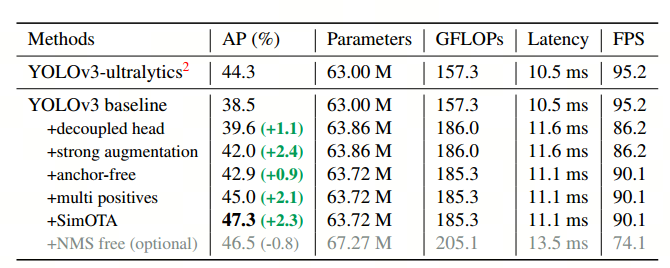
ps:YOLOv3-ultralytics是YOLOv3的最佳实践,采用了数据增强等tricks,具体改进看源码
SimOTA详解
ps:OTA来源于旷世科技另一篇文章《Ota: Optimal transport assignment for object detection》,SimOTA是OTA的简化,求近似解
SimOTA将标签匹配转换为运输问题,自动的去匹配输出和标记之间的关联,流程如下:
- 网络的输出为85*8400,也就是有8400个预选框,根据初步筛选规则得到1000个正样本预选框
- 规则1:寻找预选框中心点落在ground truth框范围的所有预选框
- 规则2:以ground truth框中心点为基准,设置边长为5的正方形,挑选在正方形内的预选框
- 假定有3个目标框,针对筛选出的1000个候选检测框,和3个ground truth框计算Loss函数
- 类别损失:pair_wise_cls_loss,维度:[3,1000]
- 位置损失:pair_wise_iou_loss,维度:[3,1000]
- 两个损失函数加权相加,得到总代价cost矩阵,维度:[3,1000]
- 设置候选框数量,假定设置为10,则会给每个目标框挑选10个iou最大的候选框,记录为topk_ious矩阵,则topk_ious的维度为[3,10]
- 将topk_ious按第2维求和取整,可以得到每个目标框应该分配的预选框数量
得到每个目标框应该分配的预选框数量后,具体的选择规则是根据cost矩阵,选择cost值最低的一些候选框

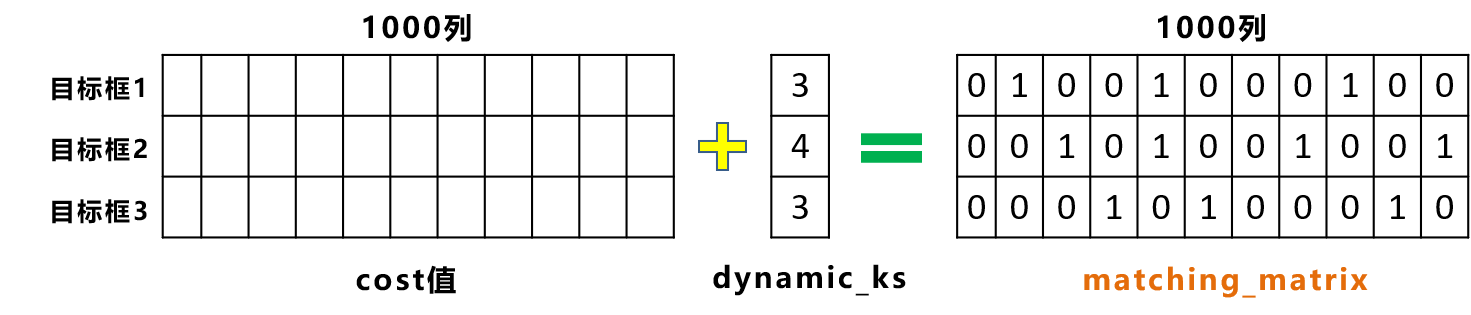
- 过滤共用的候选框:当同一个候选框对应多个目标框时,选择cost更小的候选框,即得到最终的匹配结果

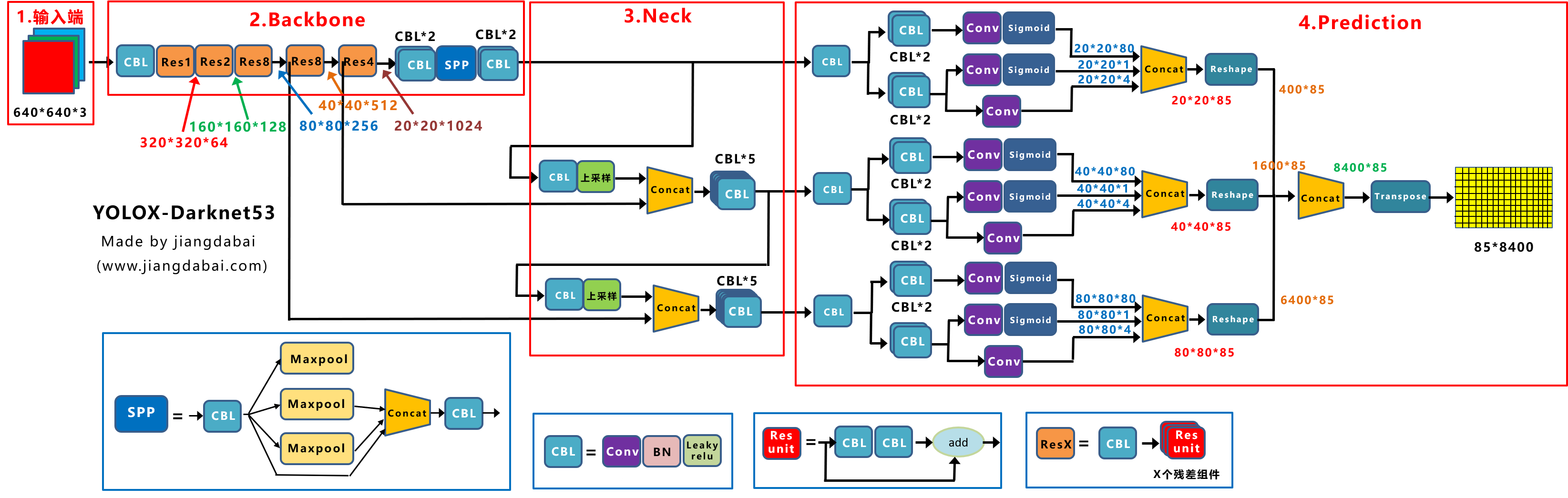
以下是Yolox-Darknet53的网络结构,可以看出:
- BackBone和Neck和Yolov3 baseline一致
- Head变为了3个Decoupled head,每个Decoupled head都是Anchor-free的多分支形式(cls、obj、reg)
3.Yolox-s/Yolox-m/Yolox-l/Yolox-x
在对Yolov3 baseline进行不断优化,获得不错效果的基础上。作者又对Yolov5系列的Yolov5s、Yolov5m、Yolov5l、Yolov5x四个网络结构,也使用上述5个trick进行改进。
(1)输入端:在Mosa数据增强的基础上,增加了Mixup数据增强效果;
(2)Backbone:激活函数采用SiLU函数;
(3)Neck:激活函数采用SiLU函数;
(4)输出端:检测头改为Decoupled Head、采用anchor free、multi positives、SimOTA的方式。
以下是Yolox-s的网络结构图
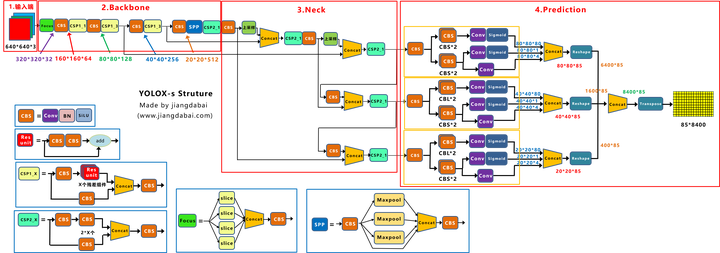
4.Yolox-Nano/Yolox-Tiny
针对边缘设备部署需求,构建了两个轻量级网络:
- 针对Yolov4-Tiny,构建了Yolox-Tiny网络结构。
- 针对FCOS 风格的NanoDet,构建了Yolox-Nano网络结构。
二、YOLOx的创新点
- 结合最新最先进的一些tricks改进了YOLO系列网络,达到了速度和精度上新的SOTA
- 将YOLO系列网络重新引入anchor-free方向,使得模型更加简单易训
总结
YOLOx是继YOLOv4之后新的tricks集大成者,在工业上具有重大意义
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!