VIGC: Visual Instruction Generation and Correction---------VIGC:视觉指令生成和纠正
上海人工智能实验室
Abstract
视觉编码器和大语言模型(LLM)的集成推动了多模态大语言模型(MLLM)的最新进展。然而,视觉语言任务的高质量指令调整数据的稀缺仍然是一个挑战。当前领先的范例,例如 LLaVA,依赖于仅语言的 GPT-4 来生成数据,这需要预先注释的图像标题和检测边界框,这在理解图像细节方面遇到了困难。该问题的一个实用解决方案是利用可用的多模态大语言模型(MLLM)来生成视觉语言任务的指令数据。然而,值得注意的是,目前可用的 MLLM 不如相应的 LLM 强大,因为它们往往会产生不充分的响应并生成虚假信息。作为解决当前问题的解决方案,本文提出了视觉指令生成和校正(VIGC)框架,该框架使多模态大型语言模型能够生成指令调整数据并逐步提高其动态质量。具体来说,视觉指令生成(VIG)指导视觉语言模型生成不同的指令调整数据。为了保证生成质量,视觉指令校正(VIC)采用迭代更新机制来纠正VIG产生的数据中的任何不准确之处,有效降低产生幻觉的风险。利用VIGC生成的多样化、高质量的数据,我们对主流模型进行微调,并根据各种评估来验证数据质量。实验结果表明,VIGC不仅弥补了纯语言数据生成方法的缺点,而且有效提升了基准测试性能。模型、数据集和代码可在 https://opendatalab.github.io/VIGC 获取。

图 1:纯语言 GPT-4 方法与所提出的方法之间的比较,突出了前者的两个关键局限性:(1) 需要进行大量的人工注释,(2) 无法处理视觉数据,从而导致丢失详细信息。
Introduction
----
介绍
在过去的一年里,语言模型取得了重大进展,特别是大型语言模型 (LLM) 中指令调优的出现。该技术使模型能够以零样本的方式执行复杂的任务(OpenAI 2023a,b)。视觉编码器与这些法学硕士的融合(Touvron et al. 2023;Chiang et al. 2023)导致多模态法学硕士领域取得了实质性进展,导致了 BLIP-2 等框架的创建(Li et al. 2023b) )、MiniGPT-4(Zhu 等人,2023b)、LLaVA(Liu 等人,2023b)和 InstructBLIP(Dai 等人,2023)。这些框架推动了图文多模态任务的快速发展,在图文对话中展现了令人印象深刻的能力。
在过去的一年里,语言模型取得了重大进展,特别是大型语言模型 (LLM) 中指令调优的出现。该技术使模型能够以零样本的方式执行复杂的任务(OpenAI 2023a,b)。视觉编码器与这些法学硕士的融合(Touvron et al. 2023;Chiang et al. 2023)导致多模态法学硕士领域取得了实质性进展,导致了 BLIP-2 等框架的创建(Li et al. 2023b) )、MiniGPT-4(Zhu 等人,2023b)、LLaVA(Liu 等人,2023b)和 InstructBLIP(Dai 等人,2023)。这些框架推动了图文多模态任务的快速发展,在图文对话中展现了令人印象深刻的能力。传统的多模态模型遵循两阶段训练过程。初始阶段涉及使用图像-文本对训练模型,以增强两种模式之间的特征对齐。后续阶段利用高质量的多模式指令调整数据来增强模型遵循指令的能力,从而提高其对用户查询的响应。然而,与大量可用的多模态预训练数据相比(Schuhmann et al. 2022;Sharma et al. 2018;Changpinyo et al. 2021),获取高质量的指令调优数据相对更具挑战性。当前的高质量多模态微调数据(Liu et al. 2023b;Li et al. 2023a)主要基于纯语言 GPT-4(OpenAI 2023b)生成,如图 1-(a) 所示。这种方法需要昂贵的手动预注释,并限制问题的设计和对现有注释信息生成的响应。因此,如果提出的问题不在该注释信息范围内,GPT-4 无法做出回应。此方法还会丢失图像中可回答问题的详细信息。
传统的多模态模型遵循两阶段训练过程。初始阶段涉及使用图像-文本对训练模型,以增强两种模式之间的特征对齐。后续阶段利用高质量的多模式指令调整数据来增强模型遵循指令的能力,从而提高其对用户查询的响应。然而,与大量可用的多模态预训练数据相比(Schuhmann et al. 2022;Sharma et al. 2018;Changpinyo et al. 2021),获取高质量的指令调优数据相对更具挑战性。当前的高质量多模态微调数据(Liu et al. 2023b;Li et al. 2023a)主要基于纯语言 GPT-4(OpenAI 2023b)生成,如图 1-(a) 所示。这种方法需要昂贵的手动预注释,并限制问题的设计和对现有注释信息生成的响应。因此,如果提出的问题不在该注释信息范围内,GPT-4 无法做出回应。此方法还会丢失图像中可回答问题的详细信息。
为了解决这个问题,研究人员开始考虑使用视觉语言模型(VLM)生成数据(Zhu et al. 2023a;You et al. 2023),因为 VLM 在预训练过程中看到了大量的图像-文本对相,本质上蕴含着丰富的知识。目前,可访问的 MLLM 不如其对应的 LLM 强大。他们经常产生不充分的反应并产生错误的信息,例如幻觉。然而,现有方法尝试使用 VLM 生成数据,而没有考虑如何确保生成数据的质量或通过实验对其进行验证。
与上述方法相比,我们提出了可视化指令生成和校正(VIGC),这是一种高质量指令数据生成的新方法。该方法基于现有的视觉语言模型(VLM),通过初始指令数据的微调,引导模型在新图像上生成多样化的视觉语言问答对。生成多样化数据的能力源于视觉编码器和大型语言模型都在广泛的数据集上进行了微调,包含丰富的图像理解和逻辑语言能力。然而,我们发现直接从提供的指令生成的数据存在严重的幻觉问题,这是困扰大型多模态模型的常见问题(Peng 等人,2023b;Liu 等人,2023a)。幸运的是,我们的视觉指令校正模块可以通过迭代更新显着减少模型幻觉现象。我们论文的主要贡献如下:
我们引入了视觉指令生成和校正(VIGC),这是一个能够自主生成高质量图像文本指令微调数据集的框架。 VIGC框架由两个子模块组成:视觉指令生成(VIG)和视觉指令校正(VIC)。具体来说,VIG 生成初始视觉问答对,而 VIC 减轻模型幻觉并通过迭代 Q-Former (IQF) 更新策略获得高质量数据。
? 我们计划发布一系列使用VIGC生成的数据集,包括36,781个VIGC-LLaVA-COCO-extra和约180万个VIGC-LLaVA-Objects365,用于大型多模态模型的研究。据我们所知,这是第一个由 MLLM 自主生成的多模态指令微调数据集。
? 我们对生成的数据进行了广泛的实验。当与 VIGC 生成的数据结合训练时,LLaVA7B 模型的性能显着提高,甚至超过了 LLaVA13B 模型。此外,在MMBench、OKVQA和A-OKVQA等主流多模态评估数据集上,使用VIGC数据训练的模型一致表现出性能增强。
Related Work
遵循指令的LLM
大型语言模型 (LLM) 的出现和发展对自然语言处理 (NLP) 领域产生了重大影响,包括但不限于 GPT-3 (Brown et al. 2020)、PaLM (Chowdhery et al. 2022) 、T5(Raffel 等人,2020)和 OPT(Zhang 等人,2022)。这些模型配备了广泛的训练数据和复杂的优化技术,在各种任务中表现出了卓越的性能。然而,他们有效遵循指令的能力仍然存在一个显着的挑战,这通常会导致在各种实际应用中得到次优结果。为了解决这个问题,人们引入了各种指令微调数据集。增强模型,例如 InstructGPT (Ouyang et al. 2022)、ChatGPT (OpenAI 2023a)、FLAN-T5 (Chung et al. 2022)、FLAN-PaLM (Chung et al. 2022) 和 OPTIML (Iyer et al. 2022) ),旨在改进零样本和少样本学习能力,主要是通过学习将指令映射到相应的预期输出。尽管取得了这些进步,指令数据集的生成经常依赖于预先存在的 NLP 任务,这限制了它们的通用性。为了提高指导的质量和多样性,Wang 等人。 (Wang 等人,2022)介绍了 SELF-INSTRUCT,这是一种利用生成的指令数据来提高LLM性能的方法。虽然这些方法在增强语言模型的指令跟踪能力方面取得了重大进展,但它们表现出标准限制,因为它们不能直接推广到多模态数据。
多模式指令调优
与创建语言指令微调数据集相比,构建多模态指令微调数据集需要对图像内容和相应文本的开发有透彻的了解。 MiniGPT-4 利用特征对齐模型来解释 CC 数据集(Sharma 等人,2018 年;Changpinyo 等人,2021 年),使用 ChatGPT 进行初始过滤,并最终生成 3,500 个图像文本对以进行模型细化。然而,这种方法在指令多样性和数量方面遇到限制。相比之下,LLaVA 提出了一种基于纯语言 GPT-4 (OpenAI 2023b) 的创新方法,从包括标题描述和目标数据的信息生成多模态指令数据。虽然这种方法生成高质量的数据,但它需要对每个标题描述、目标信息和问题进行手动注释,这本质上限制了可扩展性。为了将数据扩展至更全面的任务系列,InstructBLIP 开创了指令模板构建方法,将 26 个独特的数据集转换为指令微调数据,并在多个任务中取得了令人印象深刻的结果。同时,MIMIC(Li et al. 2023a)组装了更大规模的指令微调数据集。
然而,所有这些数据集都需要以注释的形式进行人工干预,并且它们的多样性本质上受到现有数据的限制。相比之下,我们的研究旨在提出一种自引导、模型驱动的指令微调数据生成方法,该方法能够创建适合任何新颖图像的高质量微调数据。能够创建适合任何新颖图像的高质量微调数据。
视觉问题生成
视觉问题生成(VQG)旨在根据提供的图像生成相关问题,由于多样性、自然性和参与度的需要,这带来了相当大的挑战。穆斯塔法扎德等人。 (Mostafazadeh 等人,2016)提出了视觉问题生成(VQG)的任务,并尝试采用基于检索和生成的方法建立一个基础的 VQG 框架。 iQAN(Li et al. 2018)后来提出了一个统一的、可逆的网络,可以解决 VQA 和 VQG 任务,从而能够从图像中检索答案和生成问题。 Guiding Visual Question Generation (Vedd et al. 2021) 等指导模型也对该领域做出了重大贡献。
本文提出了视觉指令生成和校正(VIGC)网络,该模型与 VQG 一样,可以生成图像相关内容。与现有的工作不同,我们的方法通过开发不同的问题并根据不同的需求类别提供适当的答案,引入了额外的复杂性。利用大型语言模型的丰富知识,我们的模型的输出优于传统的 VQG 任务,而传统的 VQG 任务通常受到训练样本大小的限制。
方法
本文专注于利用现有视觉语言模型的力量来自主生成遵循数据的多模式指令。所提出的方法有助于创建强大且多样化的微调数据集,消除了密集的手动干预的需要。然而,利用现有的多模式模型来实现这一目标面临着巨大的挑战。为了缓解这些问题,我们引入了一个名为 VIGC 的自指导框架。在现有微调数据的指导下,该框架可以生成更高质量、更多样化的新数据,如图 2 所示。
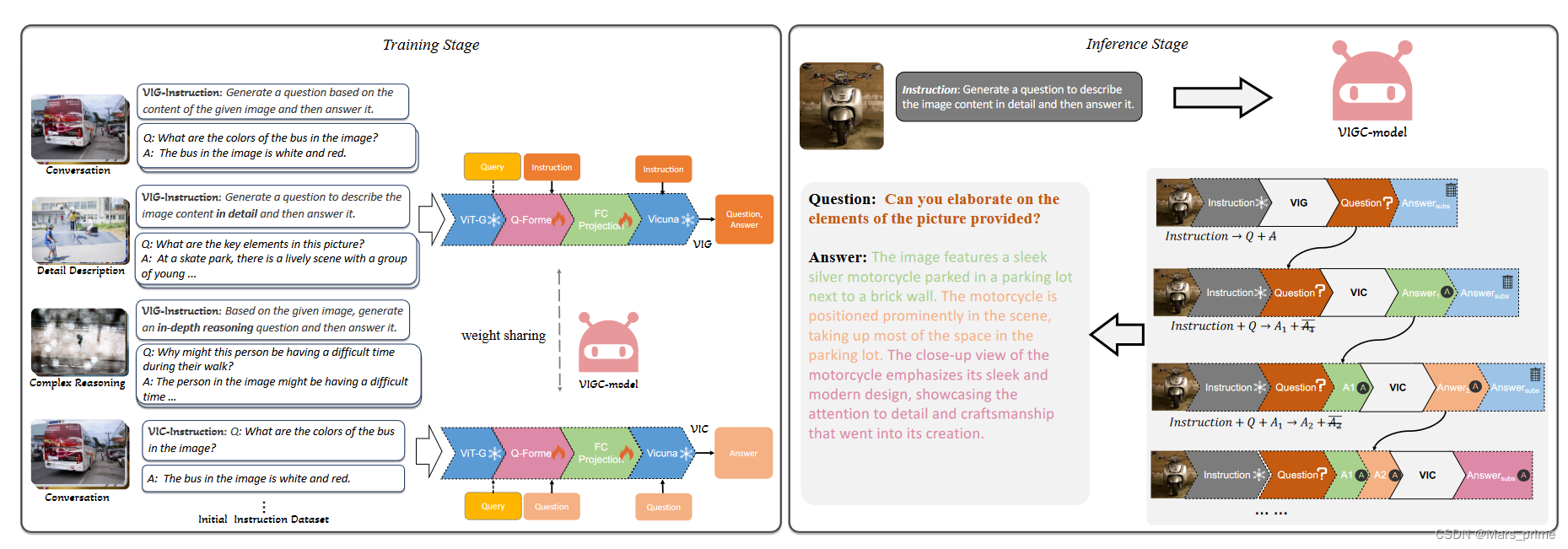
图 2:建议的视觉指令生成和校正 (VIGC) 框架。左图展示了 VIGC 训练过程:指令微调数据被输入到 VIG 和 VIC 子模块中。 VIG 旨在生成与图像相关的问答对,而 VIC 则改进 VIG 生成的答案以提高精度。右图描述了推理阶段,VIGC 将任意图像作为输入,生成初始答案,然后对其进行细化以构建高质量的微调数据。
初始指令构建
与可以通过独立语言模型轻松生成的语言指令相比(Peng et al. 2023a;Wang et al. 2022),视觉文本多模态指令的构建需要对视觉内容的详细理解,以及能力根据图像的实际内容提出相关问题并提供正确答案。然而,现有的多模态模型缺乏直接生成视觉语言指令数据的能力。为了克服这个限制,我们利用现成的指令微调数据并制定额外的指令模板,从而促进指令数据的自动生成。
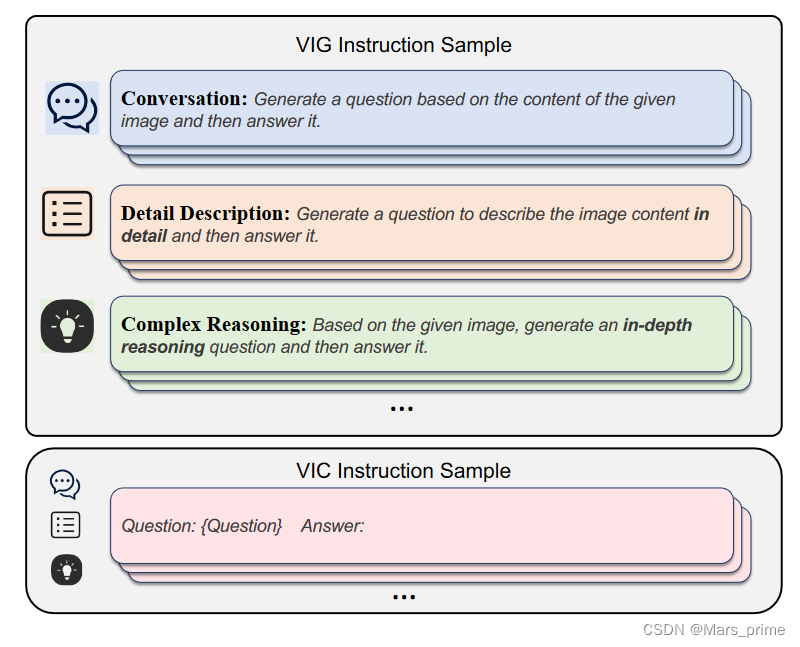
图 3:与 VIG 和 VIC 子模块中的指令调整相对应的模板示例。
我们提出的方法普遍适用于生成各种类型的图像文本多模态指令微调数据。为了阐明我们的方法,我们使用 LLaVA 样式数据指令的生成来举例说明。具体来说,我们按照 LLaVA 中描述的指令微调数据类型的分类,构建包含对话、详细描述和复杂推理的指令模板。图3展示了这三种类型的指令模板的实例,它们本质上并不复杂,主要要求“根据图像内容生成T型问答对”。理论上,如果模型在训练后能够遵循这些指令描述,那么它应该能够熟练地生成问答对。
利用指令模板和现有的视觉指令调整数据(即 LLaVA 中的问答对),我们构建了一个全面的 VIG 指令调整数据集,如下所示:

其中i ∈ {1, 2, ..., Nt},Nt表示指令类型,这样的对话,详细描述等。Xi表示RGB图像,Ii表示特定类型t对应的指令,Qt i是与指令 It 背景下的图像 Xi 相关的问题,At i 是问题 Qt i 的答案。我们的目标是利用该数据集来训练模型,在给定特定指令 It 的情况下,模型可以按照指定的指令类型为给定图像生成相应的问答对。图 2 提供了初始指令数据集的图示。
与 VIG 不同,VIC 指令采用图像和查询作为微调过程的输入,目的是生成精确的响应。 VIC指令的数据集如下所示:
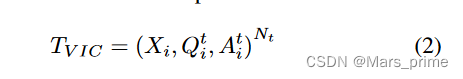
视觉指令生成
与当前流行的多模态模型(例如 MiniGPT-4(Zhu et al. 2023b)和 InstructBLIP(Dai et al. 2023))保持一致,所提出的 VIGC 的架构可以分为四个主要组件:视觉编码器(ViT)( Fang et al. 2023)、大语言模型 (Vicuna) (Chiang et al. 2023)、用于视觉特征提取的 Q-Former (Li et al. 2023b) 以及用于协调视觉的全连接 (FC) 投影-语言特征。从功能上来说,该模型可以进一步分为两个不同的子模块:视觉指令生成(VIG)模块和视觉指令校正(VIC)模块。必须强调的是,这两个子模块共享网络参数,主要区别在于用于训练的数据类型。
VIG 模块的主要目标是自主生成与任何给定图像的特定教学命令相对应的相关视觉问答对。图 2 说明了 VIG 模块在训练阶段遵循的流程。在训练阶段,VIG 模块随机选择图像,随后通过视觉编码器进行处理。它生成一组固定的视觉特征嵌入。 Q-Former 模块专门设计用于了解教学信息,进一步完善了这些视觉特征。在此阶段,模型采用可学习的视觉查询,结合指令执行自注意力操作。此操作之后是具有视觉嵌入的交叉注意阶段。这种机制促使视觉特征集中于指导信息,从而增强其在指定任务的背景下的相关性和准确性。在交叉注意力阶段之后,细化的特征通过 FC 映射层进行传递,这是将视觉特征与其语言对应物对齐的关键步骤,从而确保视觉和语言特征的无缝集成。随后,指令对齐的特征被语言模型摄取。这个过程指导模型生成预测结果。具体来说,这种情况下的目标是生成与图像 Xi 的内容本质上相关的视觉问题和答案,其性质由指令决定。我们利用大语言模型固有的原始自回归损失函数。这种方法指导模型生成与训练集中提供的问答对一致的句子。
视觉指示校正
在本研究进行的探索中,我们发现现有的多模态模型(Liu et al. 2023b)、(Dai et al. 2023)非常类似于语言模型(Radford et al. 2018、2019;Brown et al. 2020;OpenAI) 2023b,a),经常表现出幻觉问题。这种幻觉现象也存在于 VIG 生成的数据中,尤其是在大量描述的情况下。我们将此归因于多模态模型在答案生成阶段逐渐依赖当前答案文本的趋势,从而逐渐忽略图像信息,从而导致对图像中不存在的目标的描述。为了消除生成数据中的幻觉现象,并确保基于该数据的下游任务不被污染,我们专门引入了指令修正模块来更新答案,减少幻觉的发生。
为了有效利用 VIC,需要在模型训练和推理阶段采取具体行动:
在训练阶段:VIG 阶段的目标是根据指令生成相应的视觉问答对。相反,VIC 训练阶段的目标是为模型提供问题,从而引导模型在 Q-Former 特征提取过程中专注于提取与输入问题/文本相关的特征。这些特征为后续答案奠定了基础。
在推理阶段:使用上述 VIC 方法训练模型后,它可以将 VIG 生成的问答对中的问题作为输入,并在推理阶段重新生成答案。由于模型在制定响应时更加强调问题,因此生成的结果通常更准确。此外,我们迭代这个 Q-Former 特征更新过程,称为 Iterativate-Q-Former (IQF),如图 2 中的 VIGC 推理阶段所示。在部署 VIC 模块之前,我们首先生成初始问题 (Q) 和使用 VIG 回答 (A)。在第一次迭代中,我们使用指令和问题作为输入,输出答案 A1 和 ? A1,其中 A1 表示答案的第一句,? A1 表示第一句之后的所有内容。在第二次迭代中,我们输入指令、问题和上一步的答案 A1 来预测 A2,这个过程不断迭代,直到遇到终止符号。这种迭代方法的功效主要是由于使用最新的文本信息不断更新视觉特征,使后续结果更加准确。然而,应该指出的是,虽然该方法对于提供图像内容的详细描述非常有益,但其对于对话任务和推理任务的有效性相对有限。这是因为对话任务通常由单个句子组成,推理任务中的后续内容并不严重依赖图像信息。
实验
数据集
训练数据。我们使用两种类型的视觉语言指令微调数据来训练 VIGC 网络。第一种类型以 LLaVA 数据集 (Liu et al. 2023b) 为代表,是手动策划的,并与仅语言 GPT-4 (OpenAI 2023b) 结合用于多模态模型。它包括 150K 训练样本,细分为简单对话(57,669 个样本)、详细描述(23,240 个样本)和复杂推理视觉语言数据(76,803 个样本)。该数据集涵盖多模态对话的各个方面,包括类别识别、计数、动作识别和场景识别。详细的描述需要仔细的图像观察和全面的细节描述,而复杂的推理任务需要深入的推理和外部知识的整合。第二种类型的数据是从公开可用的图像文本数据集导出的多模式指令微调数据。具体来说,我们使用 InstructBLIP (Dai et al. 2023) 中使用的 OKVQA (Marino et al. 2019) 和 A-OKVQA (Schwenk et al. 2022) 数据集进行 VIGC 训练。这些数据集需要广泛的外部知识,是评估 VIGC 能力的理想选择。
推理数据。在 VIGC 网络训练之后,我们使用图像数据集生成了多模态指令的微调数据。我们使用两个不同的数据集 COCO(Lin 等人,2014 年)和 Objects365(Shao 等人,2019 年)来评估 VIGC 在处理相同或不同图像域内的数据方面的有效性。 COCO 数据集是构建 LLaVA、OKVQA 和 A-OKVQA 数据集的基础。需要强调的是,在数据生成阶段,我们故意省略了之前包含在测试集中的任何图像,以确保评估的公平性和有效性。
实施细节
在 VIGC 的训练阶段,我们利用 MiniGPT4 (Zhu et al. 2023b) 第一阶段预训练模型作为初始参数的来源。这确保了初始模型不包含用于训练的额外指令微调数据,从而保持下游任务验证的公平性。该模型包含 EVA-CLIP 中的 ViT-G/14(Fang et al. 2023)、Q-Former(Li et al. 2023b)和线性投影层。使用的语言模型是 Vicuna7B 和 Vicuna13B (Chiang et al. 2023)。值得注意的是,如图 1 所示,我们的 Q-Former 被设计为同时接收指令或问题文本,这对于 VIC 中的迭代校正至关重要。因此,我们利用 BLIP2-FlanT5XXL (Li et al. 2023b) 中的 Q-Former 作为 Q-Former 的初始参数。我们将此网络模型指定为 MiniGPT-4+。训练过程中,仅对Q-Former和线性投影层的参数进行微调,而语言和视觉模型的参数保持不变。训练共进行 10 个 epoch,每个 epoch 后都会验证模型的性能。随后选择表现出最佳性能的模型来生成数据。
在批量大小方面,我们对 7B 和 13B 模型都使用 64。整个训练过程在 8 个 A100 (80GB) GPU 上执行,大约需要 10 小时即可完成。
LLaVA 数据和评估
数据集分析。
为了生成更多样化的 LLaVAlike 数据集,VIGC 模型使用 LLaVA-150K 数据和三种类型的指令模板的组合进行训练。在推理阶段,我们使用了 COCO 2017 训练集中的图像,有意排除了 LLaVA 数据集中已包含的图像。最终选出了总共 36,781 张初始图像,作为指令数据生成的基础;我们将此数据称为 coco-extra,它作为评估期间用于模型训练的默认补充数据。
基于上述数据,VIG 网络生成各种初始问题和答案。随后,VIC 网络通过迭代 QFormer (IQF) 操作将问题和现有答案作为输入来细化输出,从而生成更高质量的响应。图 4 说明了通过 VIGC 流程生成的三类数据:
? 对话:问题通常很具体,可以得到简洁明了的回答。
? 详细描述:问题相对固定,围绕描述图像的内容。这要求模型能够清晰地观察图像内的所有目标。据观察,直接从视觉信息生成(VIG)生成的详细描述充满了许多错觉。然而,应用视觉信息校正(VIC)后,这些虚幻现象明显减少。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!