AIGC的初识
🌞欢迎来到自然语言处理的世界?
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏??留言📝
🌟本文由卿云阁原创!
📆首发时间:🌹2023年12月26日🌹
??希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
AIGC是什么?
? ? ? 当下热门科技词汇,AIGC当之无愧位列其中 但你真的了解AIGC吗?从某一天开始,我们突然发现ai生成图片,音频,图片,视频等等内容啦。而且难以分清创作者是人类还是ai,AIGC是指由AI生成的内容,是AI-generated content的缩写。想chatgbt生成的文章,都属于AIGC。
? ? 当AIGC在国内火爆的同时,海外流行的是另一个词"Generation AI",生成式AI,生成式AI所生成的内容就是AIGC。所以像chatgbt这种就属于生成式ai,在国内AIGC这个词更加的流行,很多情况下AIGC也用于指代生成式ai。
? ? AI、机器学习、监督学习、无监督学习、强化学习、深度学习、大语言模型之间的关系?
? ? AI是计算机科学与技术下的一个学科,目的是让AI去理解人类的智能,从而解决问题和完成任务,早在1956年ai就被确定成了一个学科领域,机器学习是ai的一个子集,它不需要人类做显示的编程,而是让计算机通过算法自觉的学习和改进,去做出预测和决策,显示编程就类似于if(一个男生&&长的还很帅)他一定是csdn公司的,这个过程中,计算机没有进行任何的学习,但是如果我们可以给计算机大量的数据,让其进行自主的学习和判断,这种就是机器学习,机器学习领域中有多个分支,包括监督学习(有标签,如分类和回归(房价预测)),无监督学习(无标签,比如聚类算法(新闻文章),强化学习(从结果反馈中行动,下围棋)。深度学习是机器学习的一个方法,运用人工神经网络。
? ? ?生成式ai是深度学习的一种应用,利用神经网络识别现有的内容和模式,学习生成新的内容,内容形式可以是图片文本等等。
深度学习和大语言模型有何区别?
? ?大语言模型是深度学习的一个应用,专注于自然语言处理。大说明模型的参数量特别大,需要海量的文本数据集。
啥是大语言模型?
? ? 2022年11月30日,OpenAI发布了ChatGPT,成为拥有100万用户的最快在线产品。大语言模型首先需要通过监督文本进行大量的无监督学习。参数量越大,可能效果更好。
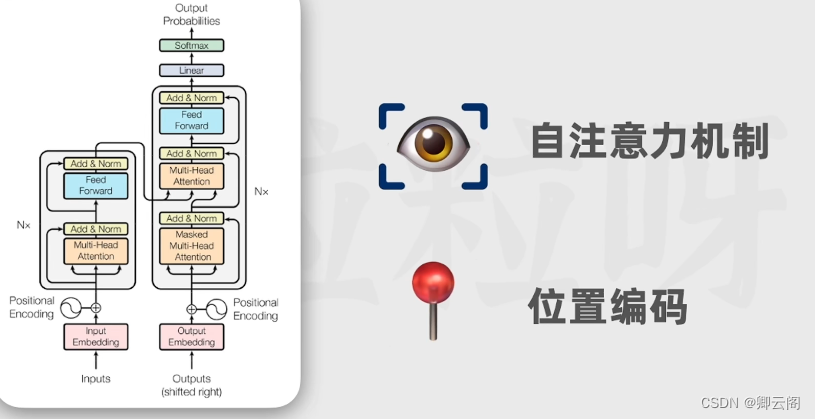
Transformer是什么?它在大语言模型中的作用是什么?
Transformer出来之后自然语言处理的方向就被改变啦。
? ? ? Transformer提出之前,我们大部分用的是循环神经网络(RNN),每一步的输出取决于当前的隐藏状态和当前的输入,等上一个步骤完成后才能进行当前的运算,无法并行计算效率低。而且不擅长处理长文本,词之间的距离越远,影响越弱,
? ? ?为了弥补这一个缺点,后来出现了lstm(长短期记忆网络),但是其也没有解决并行计算的能力,后来Transformer的出现啦,其特点在于自注意力机制,他会注意这个词和其它词语之间的相关性有多强。
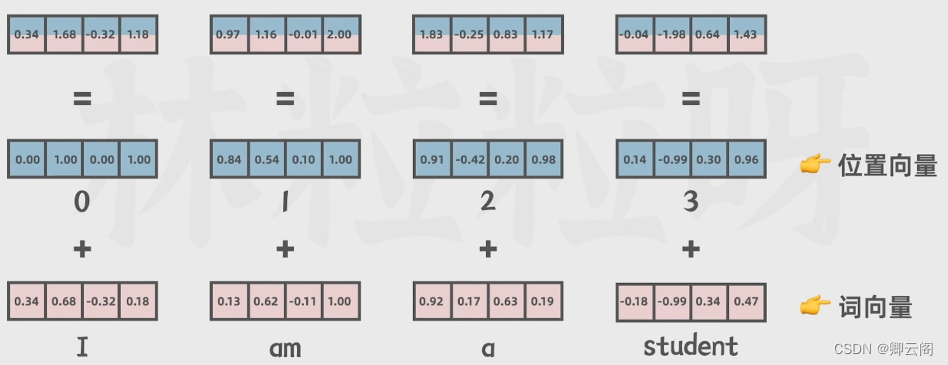
? ? 还有一个特点在于位置编码,在语言里字很重要,顺序不一样也会导致意思大相径庭,所以我们会用序列这个词,Transformer既可以捕获每个词的意思还可以捕获每个词的位置,从而理解不同词的顺序关系,借助位置编码词可以不按照顺序输送给Transformer,模型可以同时处理所有的位置。
在计算时每个词都可以独立的计算,不需要等待其它位置的计算结果,大大的提高了训练的速度。
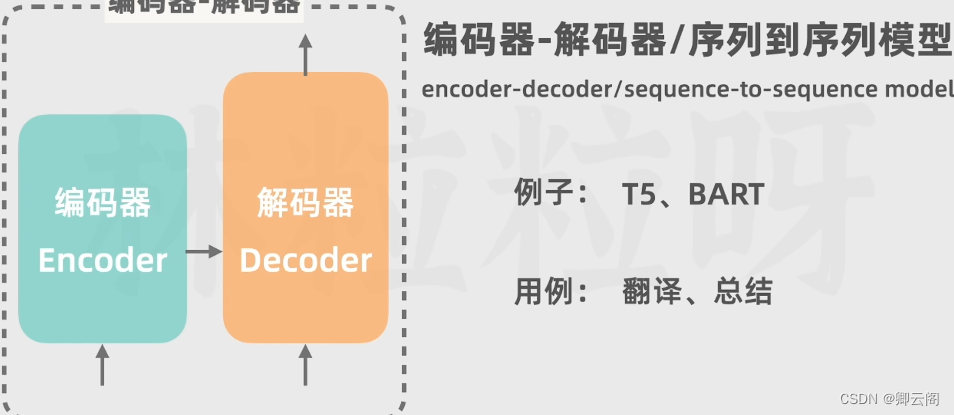
Transformer是一种由编码-解码结构组成的深度学习模型,用于生成文本?
有人说它是通过预测下一个词的概率来进行文本生成的,这种效果有点像自动补全。
假如我们让Transformer做一个翻译法语的任务。
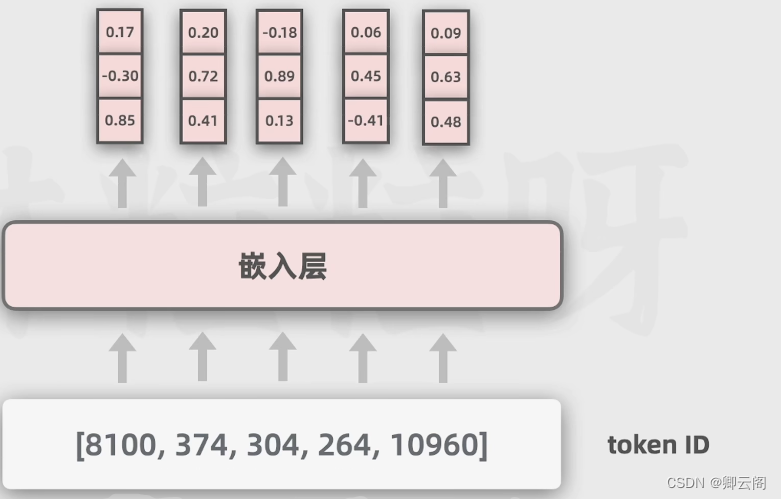
? ? ?首先我们输入的文本会被token化,也就是先把输入拆成各个的token,token可以理解成文本的一个基本单位,取决于不同的token化方法,长单词可能会被分成多个token。然后每一个token会用一个整数表示,这个数字被叫做token id。
?然后我们再把它传入到嵌入层,嵌入层是让每个token都用向量表示,向量可以简单的看出是一段数字,大于一个数字。关系越大,距离的越近。向量长度越大包含的信息越多。
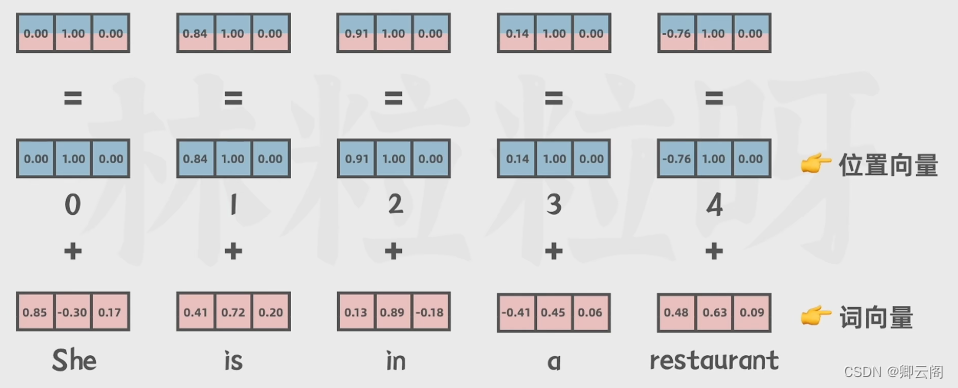
通过编码器的嵌入层得到词向量后,下一步是对向量进行位置编码,这个是一个很大的特点。
位置编码就是把位置向量和上一步得到的词向量,传给编码器。
编码器的作用是把输入转换成一种更抽象的表示形式,这个表示形式也是向量,捕捉关键特征的核心是自注意力机制,模型会关注序列中的其他词,如果两个词bu之间的相关性更强,那么她们的相关性更高。
自注意包含了对文本的一个全面的关注,在输出的结果里,不仅包含这个词本身的信息还融合了上下文的相关信息,编码器的结果会根据上下文的关系不断的调整,Transformer实际使用了多头注意力,有的关注名词,有点关注动词等等,而且可以做并行运算,多头注意力还有一个前神经网络,会对数据进行进一步的处理,编码器实际上是有多个堆叠在一起。
解码器是大语言模型生成一个个词的关键,编码器把各个数据的抽象表示传给解码器,还会先接受一个特殊值,这个值表示输出序列的开头(已经生成的文本),文本要经过嵌入层和位置编码,然后被输入多头注意力层,此时的自注意力只会关注这个词和它前面的词(带掩码的多头注意力)。
注意力会捕捉编码器的输出和解码器即将输出之间的对应关系,从而将原始序列的融入输出序列的输出过程中,解码器的神经网络的作用和解码器的类似,通过额外的运算增强表达能力。
解码器的最后阶段包含,一个线性层和一个softman层,转换成词汇表的概率分布,代表下一个token的概率,大多数情况下模型会选择概率更高的token。
ChatGPT的训练过程
无监督学习预训练
通过高质量的对话数据,对基座模型进行监督微调
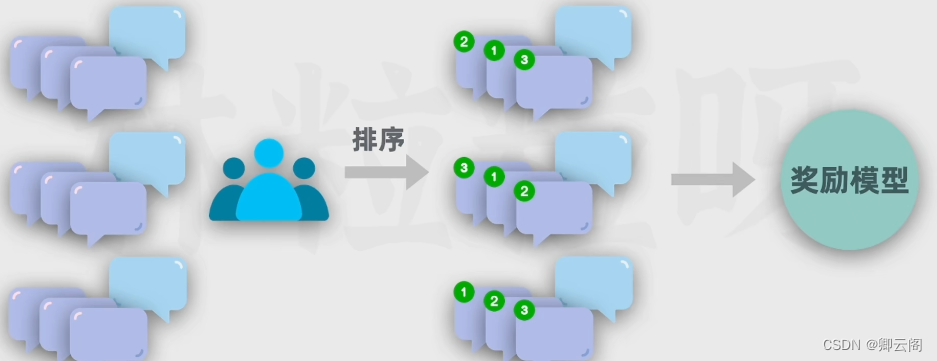
用问题和多个对应回答的数据让人类进行高质量的排序,制作评分预测的奖励数据
用奖励模型给回答进行评分,利用评分进行反馈进行强化学习训练。






















本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!