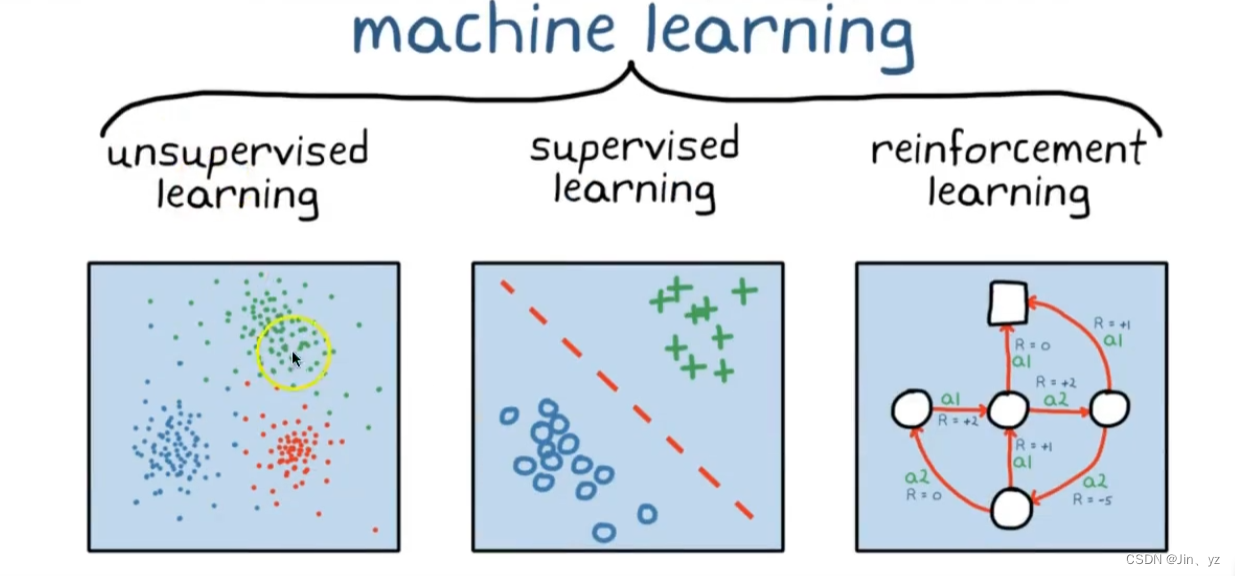
有监督学习、无监督学习、半监督学习和强化学习
有监督学习
训练数据有标签
无监督学习
数据是没有标签的
聚类的思想:通过计算空间中的距离来判断是否属于同一类
强化学习
和环境交互,从环境中学习? ?
三者对比
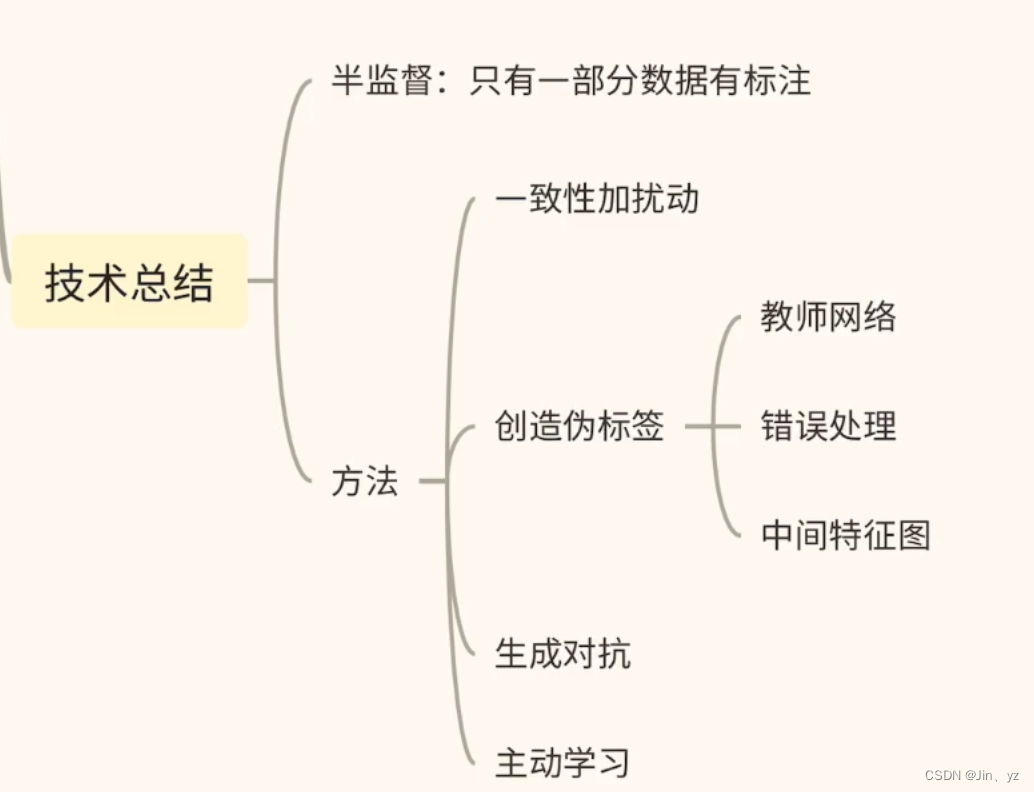
半监督学习
少量有标注,大量无标注
三个假设
1.连续性/平滑性假设:相近的数据点可能有相同的标签

2.集群假设:在分类问题中,数据往往被组织成高密度的集群,同一集群的数据点可能具有相同的标签。因此,决策边界不应该位于密集的数据点区域;相反,它应该位于高密度区域之间,将它们分离成不连续的群组。

3. 流形假设:高维数据分布可以在一个嵌入式的低维空间中表示。这个低维空间被称为数据流形。(在这里,我们的聚类和连续性假设更加可靠,我们可以根据学到的表征对—个数据点进行分类。)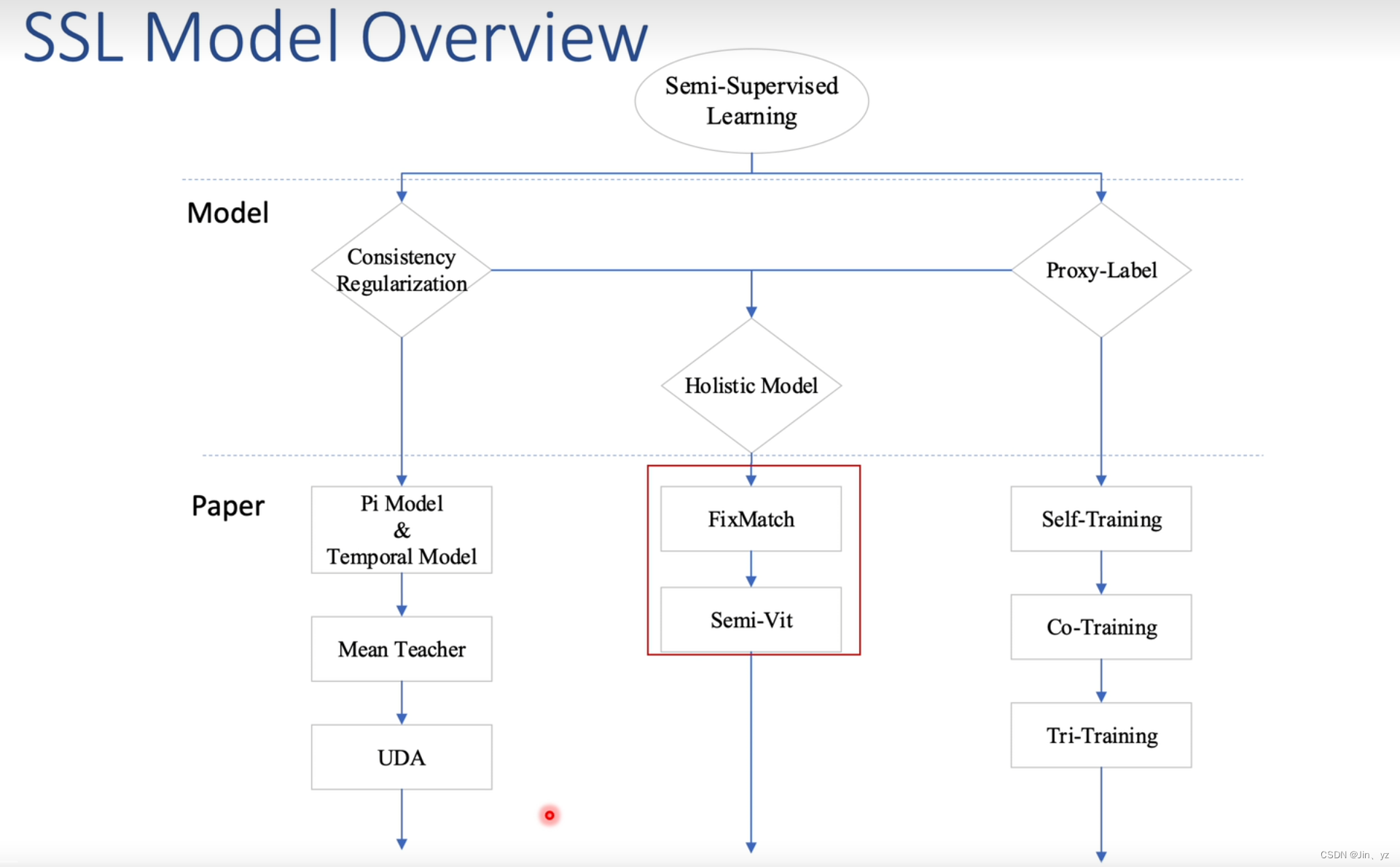
一致性正则化模型
利用连续性和集群假设。
具体操作:对于一个给定的特征x,我们的模型应该对潜在Augment(x)半径内的所有数据点做出类似的预测。即,加扰动不影响输出。
Semi-SupervisedS emantic Segmentation with Cross-Consistency Training

加扰动输入到不同解码器,降低与主解码器的输出差距,优化编码器的表示
?Semi-supervised Semantic Seg mentation with Directional Context-aware Consistency

保持“相同身份、不同背景”的特征的一致性
伪标签模型(Procy-Label Model)
核心动机:把半监督问题转换成全监督
具体操作:想办法预测得到伪标签。eg.教师网络、全监督网络


Semi-Supervised Semantic Segmentation via Adaptive EqualizationLearning

设置信心库,表现不佳的类别重复训练
Semi-supervised Semantic Segmentationwith Error Localization Network

一种处理伪标签错误的方法
Semi-Supervised Medical lmage Segmentation viaCross Teaching between CNN and Transformer
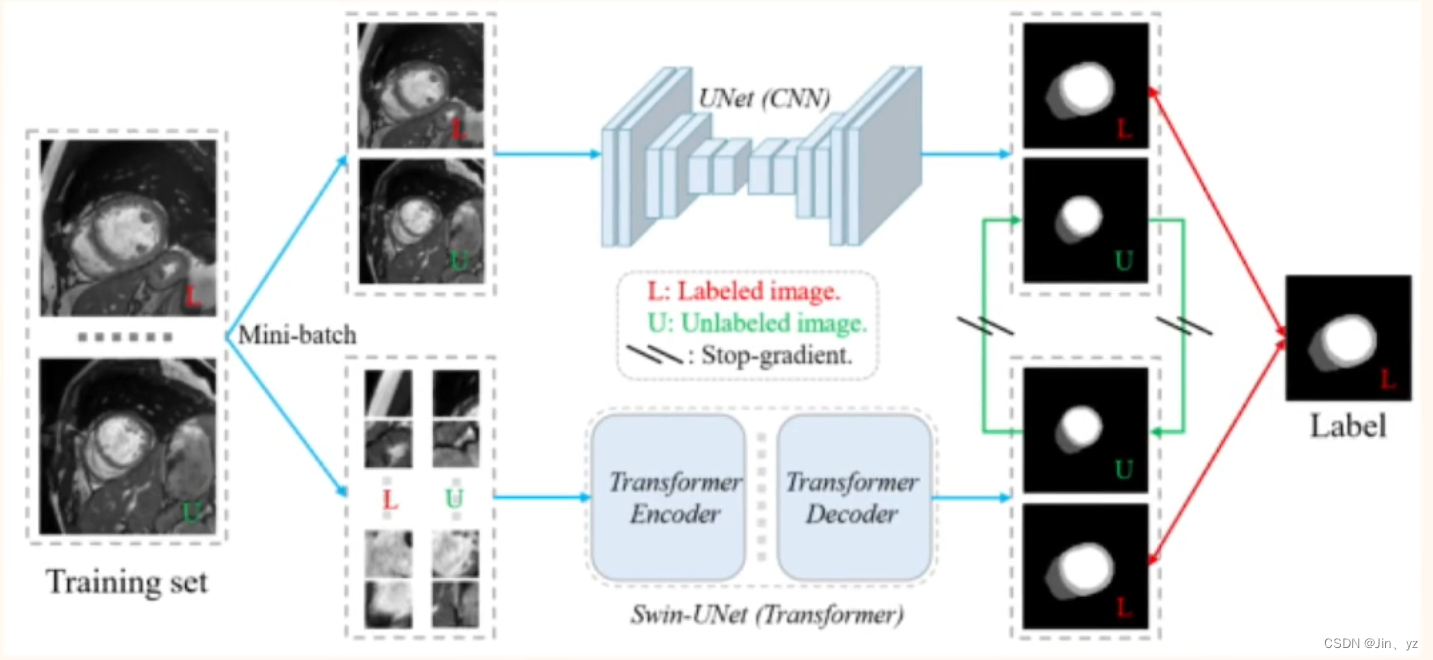
用对方的输出作为自己的伪标签
Semi-Supervised Semantic Segmentation via Gentle Teaching Assistant

降低错误伪标签对网络的影响
Multi-Layer Pseudo-Supervision for HistopathologyTissue Semantic Segmentation using Patch-level Classification Labels
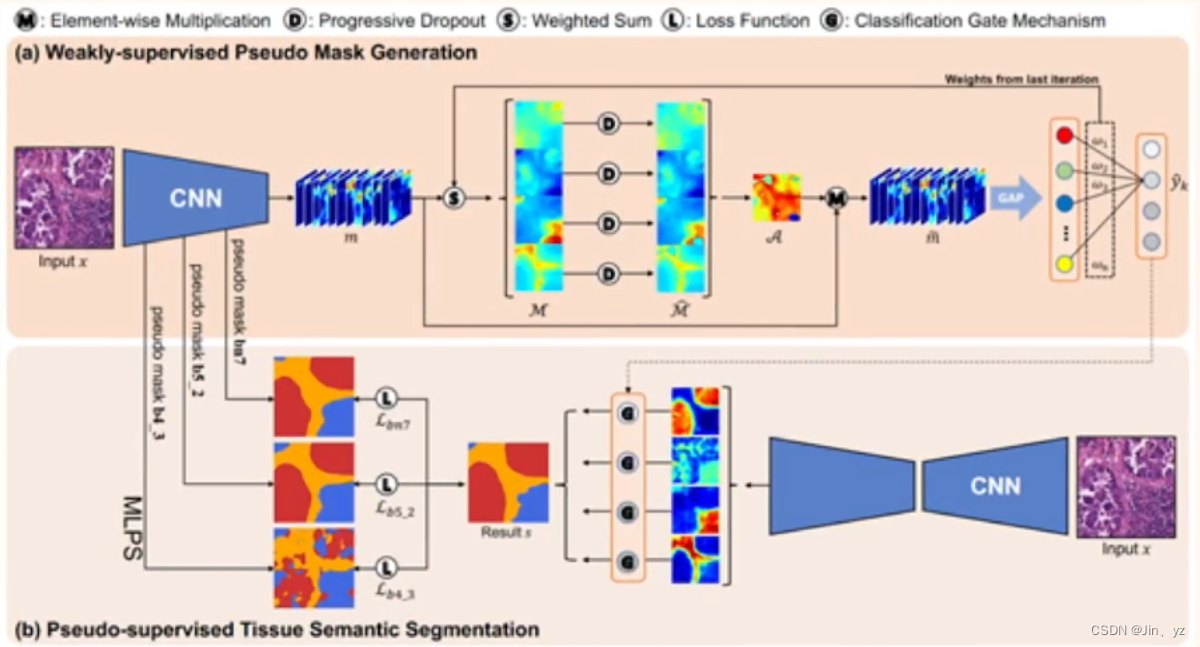
用patch级别的分类标签做分割监督
?生成对抗网络
核心动机:用鉴别器(discriminator)找到值得信赖的区域
Adversarial Learning for Semi-Supervised Semantic Segmentation
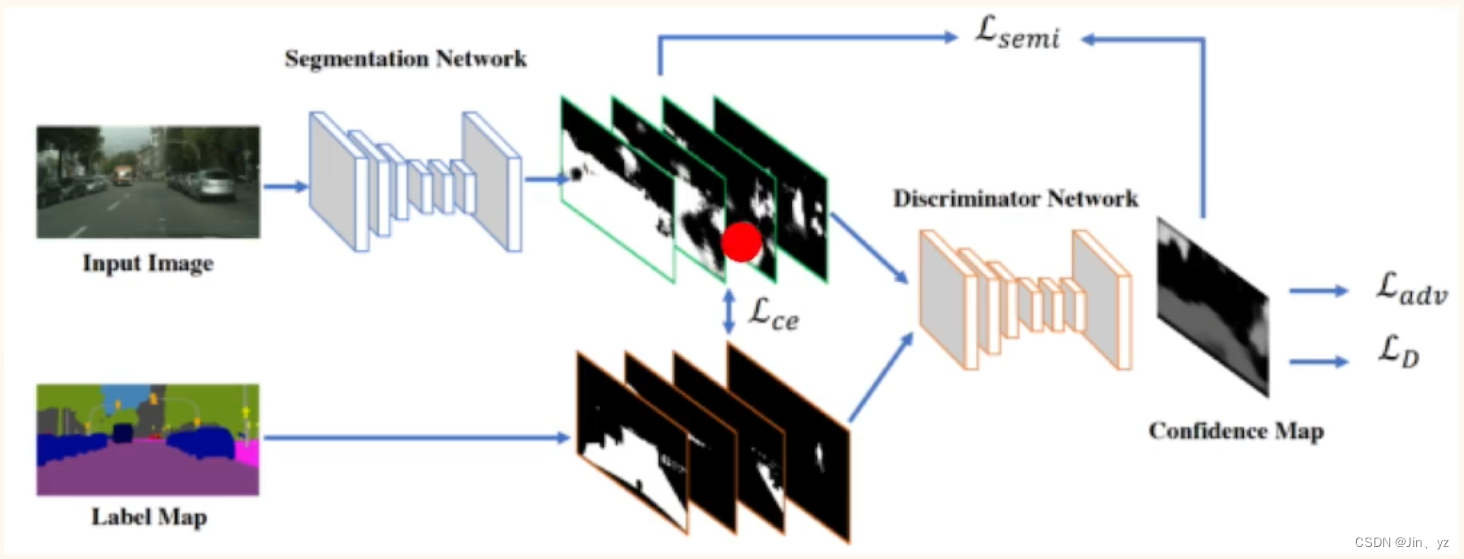
引入discriminator计算信心图,并将它作为监督信号
主动学习
核心动机:识别哪些未标记的点是最有价值的,由人类在循环中进行标记。
Towards FewerAnnotations: Active Learning viaRegion lmpurityand PredictionUncertainty for Domain Adaptive Semantic Segmentation
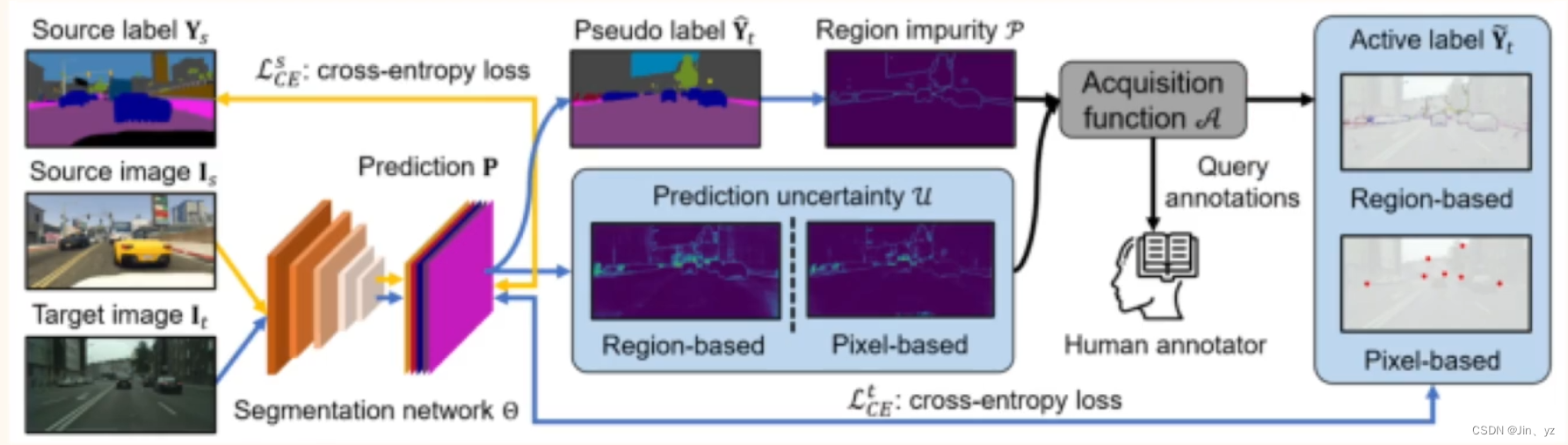
用不同方式选区域,然后人工标注
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!