基于亚马逊云科技Amazon SageMaker的多模态模型训练、推理及批量表征提取
背景
?随着大语言模型(LLM)的发展,视觉语言模型(VLM)的应用及落地也在越来越多的场景中被关注及提出。相比于传统的检测类的图像单一模态模型,图文多模态模型对于图像信息有着更好的理解,主要体现在其与人类理解的对齐能力上,本文通过Amazon SageMaker展示其对多模态大模型的训练及推理基础设施所带来的简化。同时我们发现在较多线上业务场景(如内容、电商)的实践中,非结构化数据如文本、图像可以使用其向量表征使其信息得到更充分的挖掘和利用,因此本文同时针对跨模态表征在Amazon SageMaker的批量抽取提供了示例,使得其可以快速接入不同场景进一步帮助业务提效。
?主流跨模态生成的原理概要
?以下用实际场景中使用较多的两类模型范式为例来进行简要的介绍。
?BLIP2
?BLIP2提出了一种利用已经预训练好的视觉和文本单独模态的基础大模型,来进行多模态对齐训练的方法。其设计了Querying Transformer(Q-Former),用于桥接视觉和文本两种表征,使得image encode得以和LLM进行交互,同时也是整个管道中唯一可训练的模块。

?针对这种模型管道,BLIP2提出了两阶段预训练策略:
?Stage1,使用3个并行任务来跨模态的对齐:
-
Image-Text Contrastive Learning——单图表征及单文表征的对比学习任务
-
Image-grounded Text Generation——单向图生文任务
-
Image-Text Matching——利用交互表征来进行图文匹配的二分类任务
?Stage2,引入LLM。使用Stage1中的图生文任务的输出,与输入文本一起送入LLM。并直接利用LLM的目标及Loss来进一步更新Q-Former参数。
?生成(推理)时,BLIP2 整体流程包括三个阶段:
-
使用ViT作为图像编码器,生成图片的视觉表征(向量)
-
利用提出的Querying Transformer(Q-Former),将1中的单视觉表征将转化为对齐文本后的交叉表征
-
将2中的交叉表征,叠加提示词(Prompt)并送入LLM,使用LLM来生成视觉相关的文本。这可以是单纯Caption、或是Prompt中的Question
?LLaVA
?自然语言处理领域的指令微调(Instruction Tuning)可以帮助LLM理解多样化的指令并生成比较详细的回答。LLaVA首次尝试构建图文相关的指令微调数据集来将LLM拓展到多模态领域。具体方法为:基于MSCOCO数据集,每张图有5个较简短的基准真相描述(Ground Truth)和包括类别和位置的识别矩形框(Object BBox)序列,并将这些作为Text-Only GPT4的输入,通过提示词(Prompt)的形式让GPT4生成3种类型的文本:1)关于图像中对象的对话;2)针对图片的详细描述;3)和图片相关的复杂的推理过程。注意,这三种类型都是GPT4在不看到图片的情况下根据输入的文本生成的,为了让GPT4理解这些意图,作者额外人工标注了一些样例用于语境学习(In-Context Learning)。其模型结构上,采用CLIP的ViT-L/14作为视觉编码器,LLaMA作为文本解码器,通过一个简单的线性映射层将视觉编码器的输出映射到文本解码器的词嵌入空间,如下图所示:
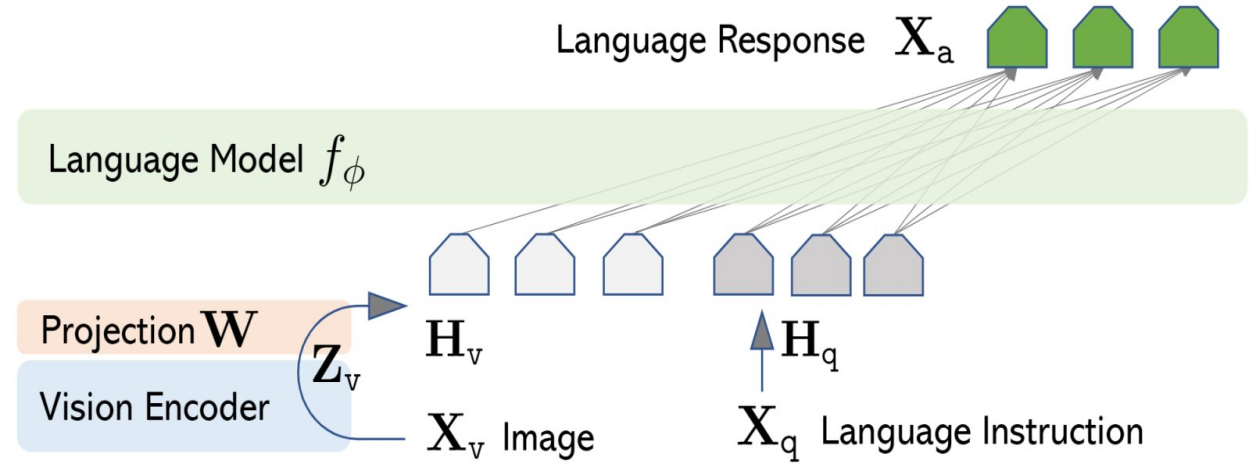
?模型训练分为两阶段:
?Stage1,跨模态对齐预训练,从CC3M中通过限制caption中名词词组的最小频率过滤出595k图文数据,冻住视觉编码器和文本解码器,只训练线性映射层;
?Stage2,第二阶段进行指令微调,一版针对多模态聊天机器人场景,采用自己构建的158k多模态指令数据集进行微调;另一版针对Science QA数据集进行微调。微调阶段,线性层和文本解码器(LLaMA)都会进行训练并进行参数更新。
?小结
?从以上两类模型的设计上可以看出,多模态的模型架构从原理上都是相似的,均是多阶段管道的形式,其中核心的还是将vis & lan的表征进行统一,并通过管道中位于下游的LLM来进行理解。这个统一表征的过程可以通过BLIP2中的Q-Former来实现,或者LLaVA中的线性投影(Linear Projection)来实现。对于此类模型,其训练也根据不同的管道的构成分为了不同的阶段。比如BLIP2的预训练1/2 Stage,其中差异点主要在于参数冻结(Freeze)的部分,这也是影响训练成本上主要因素之一。
?在Amazon SageMaker上使用LAVIS BLIP2
?以LAVIS BLIP2为例,来演示如何基于Amazon SageMaker进行模型训练,及交叉表征提取。
?模型训练
?很多企业具有特有场景定制化调优和私域数据保护的需求,因此相对于模型即服务(MaaS)类型产品更倾向于通过模型微调来提高应用效果。而Salesforce对于BLIP2的构建是直接整合在其LAVIS框架中的,其一定程度上封装了训练或推理过程中的相对繁琐的配置过程。其模型中间结果、训练图片以及训练标注的加载,均可在配置文件中统一配置。
?重载其build_datasets()方法,在训练实例当前节点的主进程中,利用s5cmd加速拷贝,从Amazon S3持久化存储将训练数据集(包括image及caption)拷贝至训练实例的NVMe存储。这里,Lavis框架帮助我们封装了Multi-GPU训练的进程判断逻辑,因此可以直接使用is_main_process()来替代if 0==LOCAL_RANK等条件判断。
?将训练数据存放位置调整为前序拷贝至的NVMe目标路径,并将模型输出存放位置调整为/opt/ml/model/,SageMaker在完成训练后将该路径下的文件拷贝至如下Estimator启动器中预设的S3持久化存储路径。
?如果在.yaml配置文件中开启evaluation,其所使用到的pycocoevalcap库需要依赖JAVA Runtime(JRE)运行环境,因此需要在预置镜像的基础上新增安装。
?最后通过SageMaker Estimator的estimator.fit()启动训练。对于垂直域图文训练集来说,BLIP2官方建议从Stage2预训练开始可以获得更好的效果,其实践方式与以上微调配置过程完全一致。
?模型推理
?LAVIS框架提供了封装好的推理接口,如LAVIS/examples/blip2_instructed_generation.ipynb中提供的Captioning/VQA任务的推理示例。
?可以使用SageMaker Endpoint及LMI(Large Model Inference)容器根据LAVIS提供的推理接口进行快速部署。基于线上业务的推理,可以根据不同推理延迟以及推理负载大小(payload)的需求,选择SageMaker的Real-time或Async Endpoint。离线批量推理任务除了SageMaker Batch Transform之外,从灵活性的角度,如下展示如何用SageMaker Training所提供的按需集群来进行批量推理。
?交叉表征提取
?多模态模型除了在构建跨模态的应用上,其中间态的交叉表征也可以作为对图文物料的多模态理解(即经过蒸馏的优势特征)用于其他类型的场景如排序等。对于生产场景中无论是线上的实时推理或离线的预生成,批量(多图)推理的能力是必须具备的。本节以批量特征抽取为例进行说明。
?在推理代码中,首先对payload的注入形式进行简单的调整,使多个图片编码合并为一个list tensor。
?此时得到一个tensor shape是[batch_size,3,364,364]的img_batch。第0维为该batch的大小,其他维度分别为图片的通道数及图片原始尺寸。同时构建相同batch size的text caption,并传入模型。
?推理结束后可以得到一个tensor shape是[batch_size,32,768]的推理结果,其中第0维仍为该batch的大小,而第1、2维度则是经过Q-Former编码之后得到的一个对应单图32*768的tensor表征。直接针对该第1维进行mean pooling。
?可以得到一个[batch_size,768]维的tensor,此时将每张图片都有了一个包含图文cross信息的新dense表征。
?这里可以将该向量表征直接推送至SageMaker Online Feature Store的InMemory tier,其底层封装了Amazon ElastiCache for Redis服务,可以提供亚毫秒级延迟并支持集合类型的特征(包括Vector类型),适用于线上如Feeds Ranking等其他模型的推理。同时,SageMaker Feature Store天然具备了online/offline的同步机制,可以使用Amazon Athena对离线特征进行分析、拼接等处理。
?配置及任务启动
?如,配置常规的SageMaker Estimator,首先需要将输入图片拷贝到集群,或直接存储于Amazon FSx for Lustre并mount进行读取。如采用前者传输方式,考虑到输入为图片类型的小文件集合,建议使用s5cmd的并发能力对传输过程进行加速。此外,需要在主进程上将上游训练任务保存的checkpoint文件从S3拉取至算力集群。
?同时在配置文件中LAVIS/lavis/configs/models/blip2/blip2_coco.yaml,写入以上checkpoint在SageMaker按需实例上的本地路径。
?最后通过estimator.fit()来启动该批量特征生成任务。
?效果评估
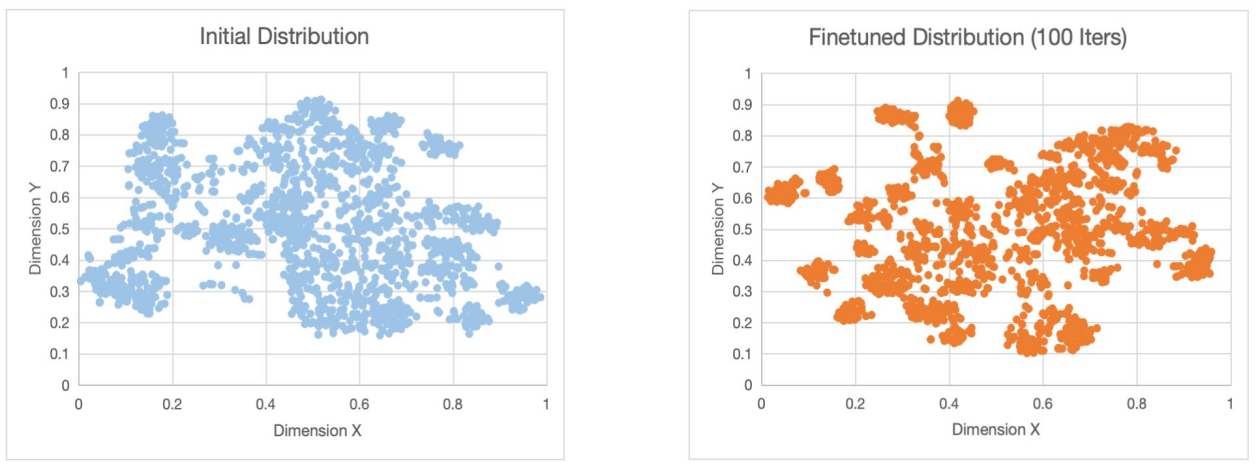
?根据上述基于Amazon SageMaker平台的训练及批量表征提取过程,这里使用coco2014数据集训练100个iteration并使用finetune后的checkpoint进行批量表征提取,作为效果展示。对2000个样本所获取的[2000,768]维数据点使用t-SNE降至2维进行可视化如下,可以看出Q-Former产生的向量表征可以较明显地体现出finetune 100个iteration后其分布发生的变化。
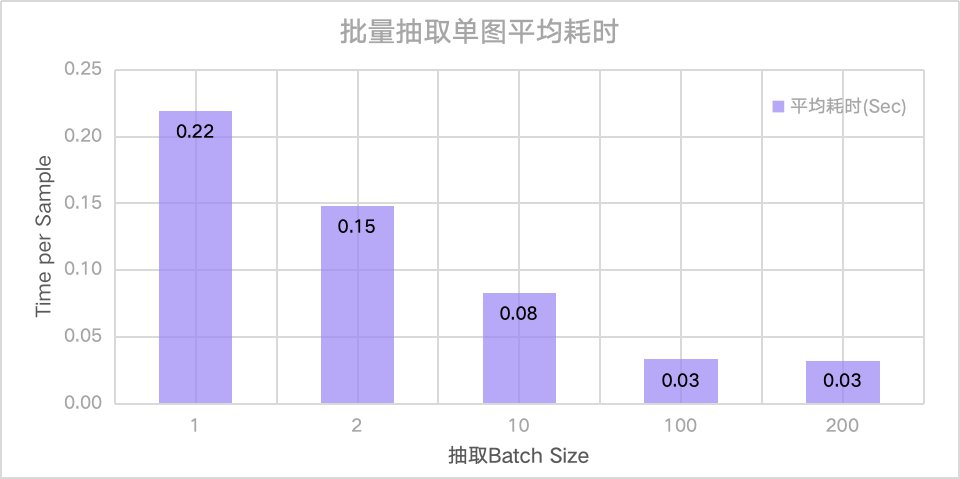
?同时,我们针对以上2000个样本对批量抽取的性能进行了评估(使用Amazon SageMaker Training所提供的按需临时集群/实例,1台单卡A10 GPU ml.g5.4xlarge实例进行测试)。
?并通过测量整体耗时最终计算得到单条样本的平均抽取耗时。可以看出通过调整原始推理接口并进行批量推理,使得单个样本的推理耗时及成本有了较明显的降低。
?总结
?BLIP2除了作为首个“unlock the capability of zero-shot instructed image-to-text generation”的模型范式之外,该类型的模型pipeline设计范式可能与生产场景的一般诉求更加匹配,原因总结如下:
-
本质上是一个通过Q-Former链接的松耦合训练范式,可以自由对Image Encoder以及LLM模块进行插拔
-
预训练和微调阶段均不需要调整LLM参数,训练成本相对低
-
训练过程中LLM模块冻结,因此得到的中间Q-Former直觉上对于跨模态的理解更加充分(对比LLAVA的LLM non-frozen训练范式,一方面其中间的MLP表达能力是天然有限的,一方面由于LLM参数是可更新的,两方面均会使得LLM承载一定的跨模态理解能力),因此其生成的Embebedding更适合作为表征,可以更好的迁移至其他场景进而提升其他场景的模型性能
?本文以LAVIS BLIP2为例,展示了其在Amazon SageMaker平台上的训练及推理过程。同时通过对原有推理接口进行简单的调整及适配,使得LAVIS BLIP2可以在Amazon SageMaker所托管的基础设施之上,快速进行批量的图文对粒度的特征抽取以赋能更多算法场景。查看本文相关代码与引用案例,请查看https://aws.amazon.com/cn/blogs/china/multimodal-model-training-inference-and-batch-representation-extraction-based-on-amazon-sagemaker/原发内容。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!