GPT-4V with Emotion:A Zero-shot Benchmark forMultimodal Emotion Understanding
GPT-4V with Emotion:A Zero-shot Benchmark forMultimodal Emotion Understanding
GPT-4V情感:多模态情感理解的zero-shot基准
1.摘要
最近,GPT-4视觉系统(GPT-4V)在各种多模态任务中表现出非凡的性能。然而,它在情感识别方面的功效仍然是个问题。本文定量评估了GPT-4V在多通道情感理解方面的能力,包括面部情感识别、视觉情感分析、微表情识别、动态面部情感识别和多通道情感识别等任务。我们的实验表明,GPT-4V表现出令人印象深刻的多模态和时间理解能力,甚至在某些任务中超过了监督系统。尽管取得了这些成就,GPT-4V目前是为一般领域定制的。它在需要专业知识的微表情识别中表现不佳。本文的主要目的是呈现GPT-4V在情绪理解方面的量化结果,并为未来的研究建立一个zero-shot基准。代码和评测结果可在:https://github . com/zero qiaoba/GPT 4v-emotion获取。
GPT-4V:
????????虽然在多模态任务上表现良好,但情感识别方面仍有提升潜力。
????????GPT-4V的优点:多模态和时间理解能力优秀,甚至在某些任务中超过了监督系统
????????GPT-4V的不足:在需要专业知识的微表情识别中表现不佳
多模态情感理解任务:?
????????面部情感识别、视觉情感分析、微表情识别、动态面部情感识别和多通道情感识别等
本文的目的:呈现GPT-4V在情绪理解方面的量化结果,并为未来的研究建立一个zero-shot基准。
zero-shot就可以被定义为:利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集;期间需要借助类别的描述,来建立训练集和测试集之间的联系,从而使得模型有效。【摘自:Zero-shot(零次学习)简介-CSDN博客】
2.背景及研究意义
- 多模态情感理解任务旨在整合多模态信息(即图像、视频、音频和文本)来理解情绪。
- 为每项任务选择有限数量的样本,对GPT-4V的性能进行定性评估,当前GPT-4V请求限制100+左右。
- 目前的GPT-4V只支持图像和文本,对于音频,我们试图转换成梅尔频谱图,以捕捉副语言信息。然而,GPT-4V拒绝承认梅尔光谱图。因此,我们的评估主要集中在图像、视频和文本上。
创新性:
????????这是第一个定量评估GPT-4V在情绪任务中表现的工作。我们希望我们的工作可以为后续研究建立一个zero-shot基准,并启发情感计算的未来方向。
评估对象:
????????GPT 4 API(GPT-4-1106-preview)
GPT-4对请求有三个限制:
????????每分钟令牌数(TPM)、每分钟请求数(RPM)和每天请求数(RPD)
????????为了满足RPM和RPD,我们遵循以前的工作[7]并采用批量输入。
?面部表情识别为例:
提示:请扮演一个面部表情分类专家的角色。我们提供20张图片。
请忽略说话者的身份,专注于面部表情。
对于每幅图像,请根据与输入的相似性从高到低对提供的类别进行排序。
以下是可选的类别:[快乐、悲伤、愤怒、恐惧、厌恶、惊讶、中性]。
每个图像的输出格式应该是{'name ':,' result ':}。
Prompt:
Please play the role of a facial expression classification expert.We provide 20 images.
Please ignore the speaker’s identity and focus on the facial expression.
For each image,please sort the provided categories from high to low according to the similarity with the input.
Here are the optional categories:[happy,sad,angry,fearful,disgusted,surprised,neutral].
The output format should be {’name’:,’result’:}for each image.
总结:
? ? ? ? 实验专注于:图像、视频和文本模态
????????评估的模型:GPT 4 API(GPT-4-1106-preview),为了满足RPM和RPD,我们遵循以前的工作[7]并采用批量输入。
????????创新性:第一个定量评估GPT-4V在情绪任务中表现的工作。目标为后续研究建立一个zero-shot基准,并启发情感计算的未来方向。?
3.实验和结果
在本文中,我们评估了GPT-4V在五个任务中的zero-shot性能
表1 2总结了数据集统计和标注方法:
- 表1:五类基本情感理解任务及数据集信息:(面部情感识别、视觉情感分析、微表情识别、动态面部情感识别和多通道情感识别)
????????面部情绪识别识别:对于视频的处理:提取每个序列的最后三帧用于情感识别。
????????????????????????????????????????提取关键帧,包括各种头部姿势、遮挡和光照
????????视觉情感分析:旨在识别由图像引起的情感,而不要求图像以人为中心
????????????????????????????????为了与之前的作品进行公平的比较,我们将这些标签重新映射为积极和消极的情绪。
????????微表情识别:微表情持续时间短,强度低,并且出现在稀疏的面部动作单元中[28]
??????????????????????????????使用apex框架评估GPT-4V对微表情的识别
????????动态面部情绪识别:将分析扩展到图像序列或视频。需要进一步利用时态信息。
????????????????????????????????????????评价指标包括未加权平均召回率(UAR)和加权平均召回率(WAR)
????????多模态情绪识别情绪:整合不同来源的信息
????????????????????????????????????????????本文主要研究否定/肯定分类任务。分别为< 0分和> 0分分配正类和负类。
- 表2:数据集及采用的情感标签信息。
对于视觉情感分析(见表4),GPT-4V优于监督系统,表明其在从视觉内容理解情感方面的强大能力。然而,GPT-4V在微表情识别方面表现不佳(见表5),这表明GPT-4V目前用于一般领域。它不适合需要专业知识的领域
表6-7显示了GPT-4V和监督系统在视频理解方面的差距。值得注意的是,由于每个视频只采样三帧,一些关键帧可能会被忽略,从而导致性能受限。
对色彩空间的稳健性在表3中,GPT-4V在CK+和FERPlus上表现稍差。由于两个数据集都有灰度图像,一个合理的假设出现了:当面对灰度图像时,GPT-4V的表现会更差吗?为了探索这种可能性,我们将RAF-DB中的所有RGB图像转换为灰度图像,并将结果报告在表8中。有趣的是,GPT-4V在不同的颜色空间表现出非常相似的性能。这种对色彩空间变化的弹性表明GPT-4V在这方面具有内在的鲁棒性。
时间理解能力为了降低评估成本,我们对每个视频统一采样三帧。在本节中,我们将进一步研究不同采样数的影响。如表9所示,当采样帧数从3减少到2时,性能明显下降。这突出了在未来工作中增加采样帧数的重要性。
多模态情感理解:表10报告了三个基准数据集上的单峰和多峰结果。
观察到多模态结果优于单峰结果,证明了GPT-4V整合和利用多模态信息的能力。但是对于CMU-MOSI,我们在多模态结果中观察到轻微的性能下降。这个数据集主要依赖于词汇信息[77],视觉信息的加入可能会给GPT-4V理解情绪带来一些困惑。









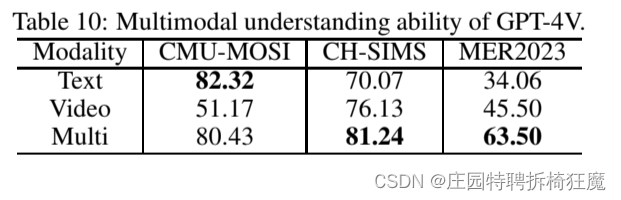
总结:
- 对于视觉情感分析,GPT-4V优于监督系统,其在从视觉内容理解情感方面的强大能力。
- GPT-4V在微表情识别方面表现不佳,GPT-4V目前用于一般领域。不适合需要专业知识的领域
- GPT-4V和监督系统在视频理解方面的差距。由于每个视频只采样三帧,一些关键帧可能会被忽略,从而导致性能受限。
- GPT-4V在不同的颜色空间表现出非常相似的性能。这种对色彩空间变化的弹性表明GPT-4V在这方面具有内在的鲁棒性。
- 多模态结果优于单峰结果
4.结论
本文做了什么:提供了对GPT-4V在五个不同任务中的多模态情绪理解性能的评估
结论是什么:GPT-4V在理解视觉内容的情感方面有很强的能力,甚至超过了监督系统。然而,它在需要专业领域知识的微表情识别中表现不佳
本文还做了什么:为后续研究的zero-shot基准
本文还能做什么:
- 由于GPT-4V API成本较高,本文对视频输入统一采样3帧。未来的工作将探索更高采样率下的性能。
- 整合更多与情感相关的任务和数据集,以提供对GPT-4V的全面评估
5.读后感
1.本文的价值在哪里?
????????对于最新的模型,GPT4的情感识别能力进行了第一次全方位评估。
2.本文的对于情感的可解释性做了哪些阐释?
? ? ? ? 将模型的情感理解能力体现为以下任务的性能:面部情感识别、视觉情感分析、微表情识别、动态面部情感识别和多通道情感识别——【情感分类任务】
3.如何理解其作为zero-shot基准?
????????本文工作希望为后续研究的zero-shot基准, 其目标在于让计算机模拟人类的情感推理方式,来识别从未见过的新事物的情感。
? ? ? ? 其在大量的情感任务及数据集上做了初次尝试。
4.接下来的工作可能从哪些方面开展?
? ? ? ? 视频更好的采样来观测性能变化
? ? ? ? 收集更多的情感数据集评估GPT-4情感能力。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!