机器学习——决策树(三)
2023-12-26 13:02:38
【说明】文章内容来自《机器学习——基于sklearn》,用于学习记录。若有争议联系删除。
1、案例一
决策树用于是否赖床问题。
采用决策树进行分类,要经过数据采集、特征向量化、模型训练和决策树可视化4个步骤。
赖床数据链接:https://pan.baidu.com/s/1mi7Is8YyGVbtrkxnHytlVA?
提取码:cndl
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn import tree
from sklearn.model_selection import train_test_split
#pandas读取CSV文件,header= None,表示不将首行作为列标签
data = pd.read_csv('laichuang.csv', header = None)
#指定列
data.columns = ['season', 'after 8:00', 'wind', 'lay bed']
vec = DictVectorizer(sparse = False)#对字典进行向量化,FALSE表示不产生稀疏矩阵
feature = data[['season', 'after 8:00', 'wind']]
x_train = vec.fit_transform(feature.to_dict('records'))
#打印各个变量
print('show feature\n', feature)
print('show vector\n', x_train)
print('show vector name\n', vec.get_feature_names_out())【运行结果】
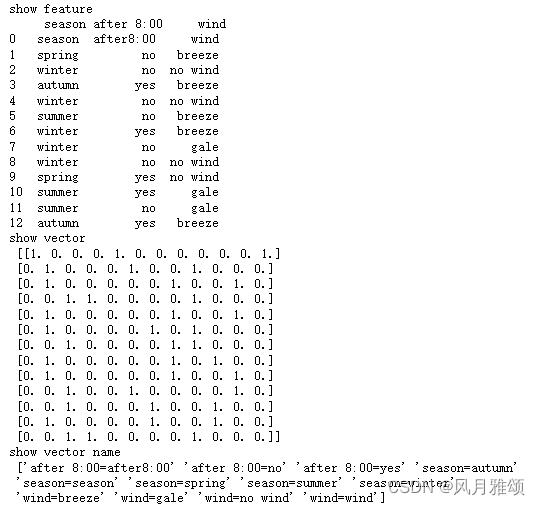
#划分数据集
x_trian, x_test, y_train, y_test = train_test_split(x_train, feature, test_size = 0.3)
#训练决策树
clf = tree.DecisionTreeClassifier(criterion = 'gini')
clf.fit(x_train, feature)
#决策树可视化,保存DOT文件
with open('d:lay.dot', 'w') as f:
f = tree.export_graphviz(clf, out_file = f, feature_names = vec.get_feature_names_out())【运行结果】
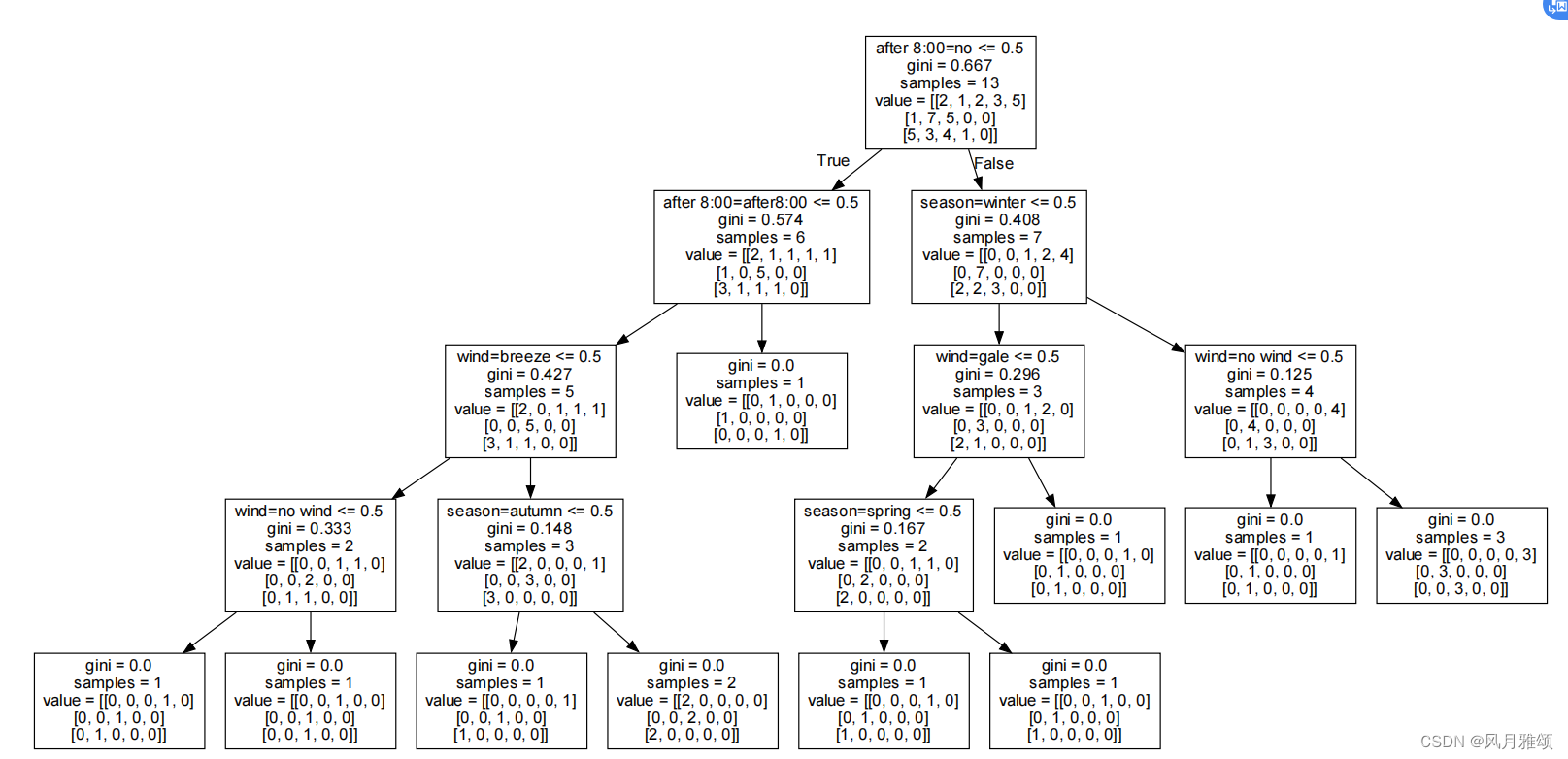
2、决策树可视化
2.1 Graphviz
????????Graphviz是一款来自AT&T Research实验窒和Lucent Bell 实验室的开源的可视化图形工具,可以绘制结构化的图形网络,支持多种格式输出。Graphviz将 Python 代码生成的dot 脚本解析为树状图。
Graphviz的安装及配置步骤如下:
1:访问网址http://www.graphviz.org/,下载Graphviz 软件安装包graphviz


2:双击该安装包,运行安装程序,将Graphviz安装到C盘,选择添加到环境变量中。
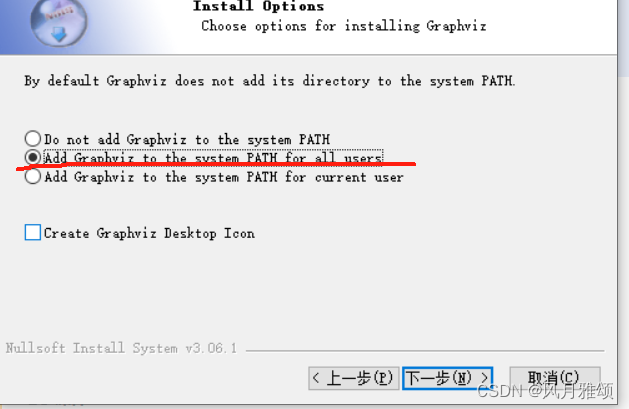
3:使用pip安装 graphviz,命令如下:
pip install graphviz
2.2 DOT
????????DOT是一种文本图形描述语言,用于描述图表的组成元素及其关系。DOT 文件通常以.gv或.dot为扩展名。DOT 与 Graphviz的关系可以类比 HTML 和浏览器的关系。打开.cmd窗口,进人out.dot所在目录,此处为D盘根目录,运行dot命令,如图所示。
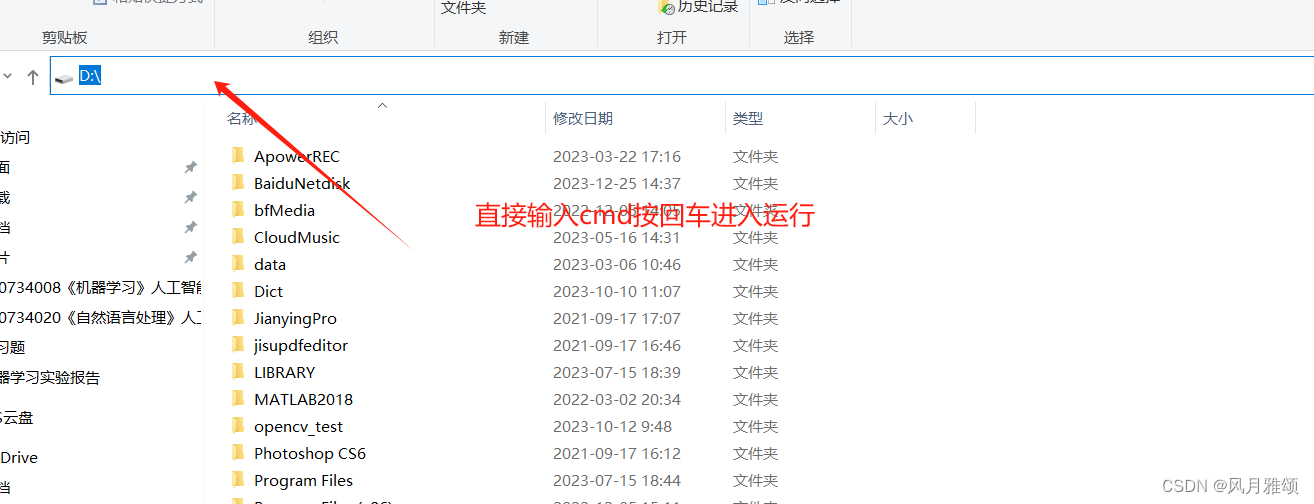
dot out.dot - T paf -o out.pdf

打开PDF文件显示。

3、案例二
波士顿房价
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
import pandas as pd
import numpy as np
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
x = data
y = target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.25,
random_state = 33)
#特征预处理,对训练数据和测试数据标准化
ss_x = StandardScaler()
x_train = ss_x.fit_transform(x_train)
x_test = ss_x.transform(x_test)
ss_y = StandardScaler()
y_train = ss_y.fit_transform(y_train.reshape(-1,1))
y_test = ss_y.transform(y_test.reshape(-1,1))
#使用回归树进行训练和预测,初始化KNN回归模型,使用平均回归算法进行预测
dtr = DecisionTreeRegressor()
#训练
dtr.fit(x_train, y_train)
#预测,保存预测结果
dtr_y_predict = dtr.predict(x_test)
#模型评估
print('回归树的默认评估值为:', dtr.score(x_test, y_test))
print('回归树的R_squared值为:', r2_score(y_test, dtr_y_predict))
# print('回归树的均方误差为:',mean_squared_error(ss_y.inverse_transform(y_test),
# ss_y.inverse_transform(dtr_y_predict)))
# print('回归树的平均绝对误差为:', mean_absolute_error(ss_y.inverse_transform(y_test),
# ss_y.inverse_transform(dtr_y_predict)))【运行结果】
![]()
文章来源:https://blog.csdn.net/qq_41566819/article/details/135214416
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!