Java爬虫之Jsoup
1.Jsoup相关概念
Jsoup很多概念和js类似,可参照对比理解
Document :文档对象。每份HTML页面都是一个文档对象,Document 是 jsoup 体系中最顶层的结构。
Element:元素对象。一个 Document 中可以着包含着多个 Element 对象,可以使用 Element 对象来遍历节点提取数据或者直接操作HTML。
Elements:元素对象集合,类似于List。
Node:节点对象。标签名称、属性等都是节点对象,节点对象用来存储数据。
类继承关系:Document 继承自 Element(class Document extends Element) ,Element 继承自 Node(class Element extends Node)。
2.从URL中加载文档对象(常用)
使用 Jsoup.connect(String url).get()方法获取(只支持 http 和 https 协议)

connect(String url)方法创建一个新的 Connection并通过.get()或者.post()方法获得数据。如果从该URL获取HTML时发生错误,便会抛出 IOException,应适当处理。
Connection 接口还提供一个方法链来解决特殊请求,我们可以在发送请求时带上请求的头部参数,具体如下: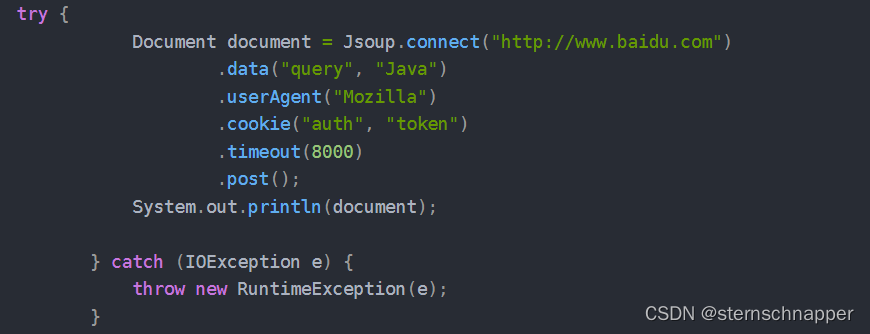
3.从本地文件中加载文档对象
可以使用静态的Jsoup.parse(File in, String charsetName) 方法从文件中加载文档。其中in表示路径,charsetName表示编码方式,示例代码:

4.从字符串文本中加载文档对象
使用静态的Jsoup.parse(String html) 方法可以从字符串文本中获得文档对象 Document ,示例代码:

5.从片断中获取文档对象
使用Jsoup.parseBodyFragment(String html)方法
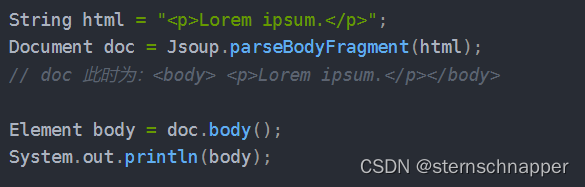
parseBodyFragment 方法创建一个新的文档,并插入解析过的HTML到body元素中。假如你使用正常的 Jsoup.parse(String html) 方法,通常也能得到相同的结果,但是明确将用户输入作为 body 片段处理是个更好的方式。
Document.body() 方法能够取得文档body元素的所有子元素,与 doc.getElementsByTag(“body”)相同。
6.定位选择元素
DOM方式
可以利用dom结构的方式,通过标签,id,class等查找到下属元素
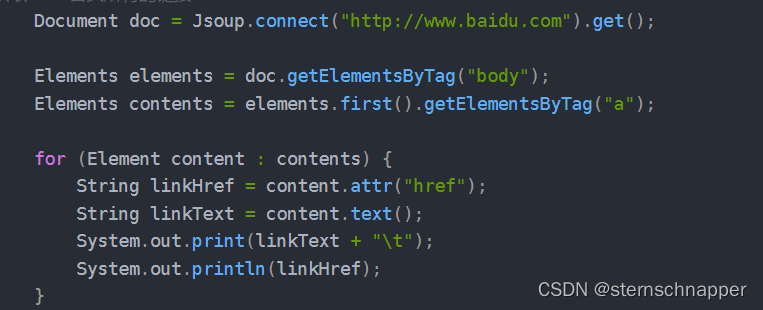
查找元素-下列方法返回的是Element或Elements
getElementById(String id):通过id来查找元素
getElementsByTag(String tag):通过标签来查找元素
getElementsByClass(String className):通过类选择器来查找元素
getElementsByAttribute(String key) :通过属性名称来查找元素,例如查找带有href元素的标签。
siblingElements():获取兄弟元素。如果元素没有兄弟元素,则返回一个空列表。
firstElementSibling():获取第一个兄弟元素。
lastElementSibling():获取最后一个兄弟元素。
nextElementSibling():获取下一个兄弟元素。
previousElementSibling():获取上一个兄弟元素。
parent():获取此节点的父节点。
children():获取此节点的所有子节点。
child(int index):获取此节点的指定子节点。
CSS选择器方式
也可以使用类似于CSS选择器的语法来查找和操作元素,常用的方法为select(String selector)。
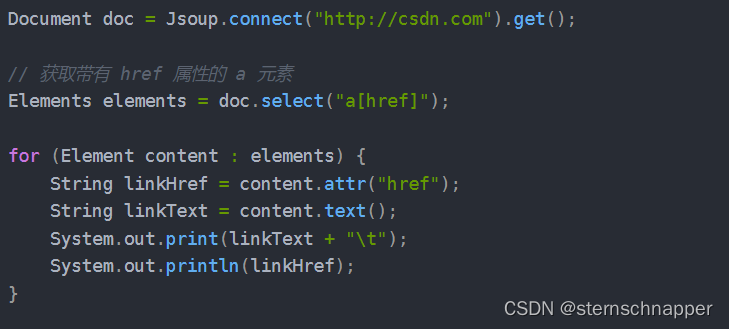
select()方法在Document、Element或Elements对象中都可以使用,而且是上下文相关的,因此可实现指定元素的过滤,或者采用链式访问。
select() 方法将返回一个Elements集合,并提供一组方法来抽取和处理结果。
select(String selector)方法参数简介
tagname: 通过标签查找元素,例如通过"a"来查找< a >标签。
#id: 通过ID查找元素,比如通过#logo查找< p id=“logo”>
.class: 通过class名称查找元素,比如通过.titile查找< p class=“titile”>
ns|tag: 通过标签在命名空间查找元素,比如使用 fb|name 来查找 < fb:name>
[attribute]: 利用属性查找元素,比如通过[href]查找< a href=“…”>
[ ^attribute]: 利用属性名前缀来查找元素,比如:可以用[^data-] 来查找带有HTML5 dataset属性的元素
[ attribute=value]: 利用属性值来查找元素,比如:[ width=500]
[attribute^=value], [attribute$=value], [attribute*=value]: 利用匹配属性值开头、结尾或包含属性值来查找元素,比如通过[href*=/path/]来查找
[attribute~=regex]: 利用属性值匹配正则表达式来查找元素,比如通过 img[src~=(?i).(png|jpe?g)]来匹配所有的png或者jpg、jpeg格式的图片
*: 通配符,匹配所有元素
参数属性组合使用
例如:Elements elements = doc.select(“div.css_tr_event”);
el#id: 元素+ID,比如: div#logo
el.class: 元素+class,比如: div.masthead
el[attr]: 元素+class,比如 a[href]匹配所有带有 href 属性的 a 元素。
任意组合,比如:a[href].highlight匹配所有带有 href 属性且class="highlight"的 a 元素。
ancestor child: 查找某个元素下子元素,比如:可以用.body p 查找在"body"元素下的所有 p元素,中间有一个空
parent > child: 查找某个父元素下的直接子元素,比如:可以用div.content > p 查找 p 元素,也可以用body > * 查找body标签下所有直接子元素
siblingA + siblingB: 查找在A元素之前第一个同级元素B,比如:div.head + div
siblingA ~ siblingX: 查找A元素之前的同级X元素,比如:h1 ~ p
el, el, el:多个选择器组合,查找匹配任一选择器的唯一元素,例如:div.masthead, div.logo
特殊参数:伪选择器
:lt(n): 查找哪些元素的同级索引值(它的位置在DOM树中是相对于它的父节点)小于n,比如:td:lt(3) 表示小于三列的元素
:gt(n):查找哪些元素的同级索引值大于n``,比如: div p:gt(2)表示哪些div中有包含2个以上的p元素
:eq(n): 查找哪些元素的同级索引值与n相等,比如:form input:eq(1)表示包含一个input标签的Form元素
:has(seletor): 查找匹配选择器包含元素的元素,比如:div:has§表示哪些div包含了p元素
:not(selector): 查找与选择器不匹配的元素,比如: div:not(.logo) 表示不包含 class=logo 元素的所有 div 列表
:contains(text): 查找包含给定文本的元素,搜索不区分大不写,比如: p:contains(jsoup)
:containsOwn(text): 查找直接包含给定文本的元素
:matches(regex): 查找哪些元素的文本匹配指定的正则表达式,比如:div:matches((?i)login)
:matchesOwn(regex): 查找自身包含文本匹配指定正则表达式的元素
注意:上述伪选择器索引是从0开始的,也就是说第一个元素索引值为0,第二个元素index为1等
7.获取数据
获取元素数据
attr(String key):获取单个属性值
attributes():获取所有属性值
attr(String key, String value):设置属性值
text():获取文本内容
text(String value):设置文本内容
html():获取元素内的HTML内容
html(String value):设置元素内的HTML内容
outerHtml():获取元素外HTML内容
data():获取数据内容(例如:script和style标签)
id():获得id值(例:
衣服
)
className():获得第一个类选择器值
classNames():获得所有的类选择器值
tag():获取元素标签
tagName():获取元素标签名(如:、等)
操作HTML文本
- append(String html):在末尾追加HTML文本
- prepend(String html):在开头追加HTML文本
- html(String value):在匹配元素内部添加HTML文本。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!