改进的A*算法的路径规划(1)
引言
近年来,随着智能时代的到来,路径规划技术飞快发展,已经形成了一套较为 成熟的理论体系。其经典规划算法包括 Dijkstra 算法、A*算法、D*算法、Field D* 算法等,然而传统的路径规划算法在复杂的场景的表现并不如人意,例如复杂的越 野环境。针对越野环境规划问题以及规划算法的优劣性,根据第三章和第四章节获 取越野环境的路面信息与障碍物信息,选择改进A*算法来进行越野环境路径规划 通过越野栅格环境建模、通行方向变化惩罚、局部区域复杂度惩罚和路径平滑的方 法对传统 A*算法进行改进,以满足复杂越野环境下,不同类型的智能车辆和不同任务的安全行驶、高效通行综合要求。
传统 A*算法
在启发式搜索算法中, A* 算法是其中最为典型的代表,它在全局路径规划算 法中,具有快速、高效和准确的优点,因此在智能车辆和工业机器人的路径规划问 题上得到了广泛的应用。针对规划路径的需求和任务的要求,许多学者对传统A*算法进行改进,例如:路径的长度、规划效率和拐点数等方面。
算法原理
许多寻找两点之间最短路径的算法,最早提出的解决方案之一是Dijkstra 算法, Dijkstra 算法总是访问距离起始节点最近的未访问节点,因此搜索不指向目标节点。 广度优先搜索 BFS,? 在某种程度上,与 Dijkstra 算法相反,它不是总是选择离起始? 节点最近的节点,而是选择离目标节点最近的节点。A* 算法结合了Dijkstra算法和?? 广度优先搜索BFS,? 保证能找到两个最优解,就像Dijkstra 算法一样,因为它是由? 启发式引导到目标节点的,像广度优先搜索BFS, 它不会像 Dijkstra算法访问那么? 多的节点。
全局代价函数是A* 算法的核心所在,全局代价函数中包含两个代价值, 一个 是从起点到当前节点的代价 G,? 称为真实代价;另一个是当前节点到终点的代价 H, 称为预估代价。传统的 A* 算法的全局代价函数一般表示为:
式中:f(n) 为全局代价函数, g(n) 为真实代价函数, h(n)为启发函数,(x,,yy,)为
#转弯代价
if minF.father==None:
turn_cost=1
else:
main_angle=self.Angle(minF.father.point,minF.point)#主方向
angle_son=self.Angle(minF.point, currentPoint)#当前方向
#转弯代价
turn_cost=self.constant (main_angle,angle_son)
if turn_cost>1.8:
turn_cost=1000
step=step*turn_cost
#print(step)当前节点坐标, (xg,ya)为终点坐标。
在全局代价函数中,启发函数设计尤为重要,因为启发函数设计的优劣直接影 响 A*算法规划路线的长度和搜寻效果。当预估代价h(n) 低于真实代价g(n)? 时,则 算法寻找的节点数量增多,但可以确保获得最短路线;当预测代价h(n)超过真实 代价g(n)时,需要寻找的节点数量大大减少,但无法确保获得最短路线。所以, 想要计划出最短路线并确保效率高效,则应使h(n)尽量等于g(n)。正如我们已经 提到的,A*算法使用的启发式部分h(n)是它与 Dijkstra 算法的区别之处,它将搜 索引导到目标节点。如果启发式函数是可接受的(意味着它永远不会高估目标的最 小代价),那么A* 也像 Dijkstra一样,保证能找到最短、最便宜的路径。使用尽可 能少地低估最小成本的启发式方法也有很大的优势,因为这将导致被检查的节点 更少。理想的启发式总是返回达到目标的实际最小成本。目前最为普遍的三种启发 函数有:对角线距离启发式,适用于使用8邻接的启发式;曼哈顿距离启发式,适 用于使用4邻接的启发式;第三种也是常用的启发式是欧几里德距离启发式。
(1)曼哈顿距离启发式
曼哈顿启发式是通过将x?和y 分量的差值相加来计算的,如下图5-1?所示,使用这种启发式的优点是计算成本低,具体为:
式中:(x?,y,)为当前节点坐标,(xg,yg)为终点坐标。曼哈顿启发式的主要缺点 是它倾向于高估目标的实际最小成本,即会使得预估代价h(n)大于真实代价 g(n),???? 虽然效率高,但所找到的路径可能不是最优解决方案。
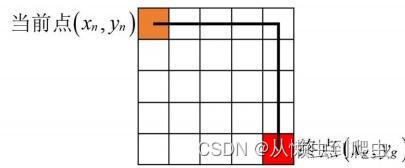
?两点之间的曼哈顿距离
(2)欧氏距离启发式
欧几里德启发式是最为常用的启发式距离,如图5-2所示。欧几里德距离启发式在计算上也比曼哈顿启发式更昂贵,因为它额外涉及两个乘法运算和取平方根:
? ? ? 缺点是通常会大大低估实际成本,搜索效率低,可能会访问太多不必要的节点,从而增加了寻找道路的时间,但是能找到最短路径。
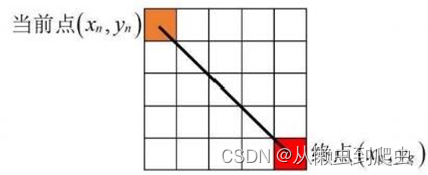
对角线距离启发式
对角线距离启发式结合了曼哈顿启发式和欧几里德启发式的两个方面。它的 优点是总是给出目标的实际可能的最小代价,不再需要取平方根,从而使其计算效 率略高于欧几里德距离启发式。启发式值由对角线和直线两部分组成。为求可采取的对角线步数,可使用下列公式:
从曼哈顿距离减去两倍的对角线步数的原因是,1个对角线步数等于2个直线 步数。如果我们假设对角线步骤的代价是2,水平步骤的代价是1,那么下面的公式产生了这个启发式的h(n)值:
h(n)=num? S S+√2*num D? s? ?
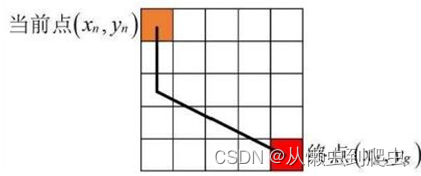
两点之间的对角距离
本文采用的为对角距离。
A* 算法原理实现的一个重要组成部分是开链表OPEN? 和闭链表 CLOSE。? 开放 列表包含已经到达但尚未访问和扩展的所有节点。关闭列表包含所有已访问和展 开的节点。A* 通过从潜在的后续节点列表,即f(n)?? 值最低的节点中选择最有希望 的节点移动到后续节点。A* 算法的寻路过程可以简单概括为:
Step1: 如图5-5所示,起始点S, 终 点T, 黑色方框为障碍物。从起始点S 开 始,并把它加入到开链表 OPEN 中。现在开链表 OPEN 里只有一项为起始点 S??? 后面会慢慢加入更多的项。开链表 OPEN? 里的格子是路径可能会是沿途经过的,也有可能不经过。
Step2: 查看与起点 S 相邻的节点(忽略其中障碍物所占领的节点),把那些节 点加入到开链表 OPEN 中,把起点S 设置为这些节点的父节点。并把起始点 S 从 开链表OPEN 中移除,加入到闭链表 CLOSE 中,闭链表 CLOSE 中的每个节点不 需要再关注。
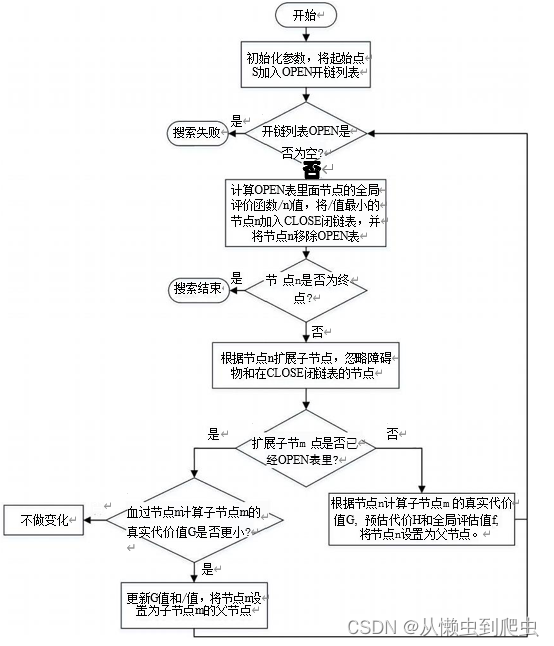
?传统 A*算法流程图
Step3:? 计算开链表 OPEN 中所有节点的真实代价 G,?? 预估代价 H,? 全局评估 值 f; 选 择 最 小 全 局 评 估 值f 的 节 点n,? 把 它 从 开 链 表 OPEN?? 里 取 出 , 放 到 闭 链 表 CLOSE 中。检查所有与它相邻的节点,忽略在闭链表CLOSE 中或障碍物的节点。
#方向标签
def Angle(self,point_father,point_son):
if point_son.x-point_father.x==0 and point_son.y-point_father.y==-1:
angle=1
return angle
if point_son.x-point_father.x==1 and point_son.y-point_father.y==-2:
angle=2
return angle
if point_son.x-point_father.x==1 and point_son.y-point_father.y==-1:
angle=3
return angle
if point_son.x-point_father.x==2 and point_son.y-point_father.y==-1:
angle=4
return angle
if point_son.x-point_father.x==1 and point_son.y-point_father.y==0:
angle=5
return angle
if point_son.x-point_father.x==2 and point_son.y-point_father.y==1:
angle=6
return angle
if point_son.x-point_father.x==1 and point_son.y-point_father.y==1:
angle=7
return angle
if point_son.x-point_father.x==1 and point_son.y-point_father.y==2:
angle=8
return angle
if point_son.x-point_father.x==0 and point_son.y-point_father.y==1:
angle=9
return angle
if point_son.x-point_father.x==-1 and point_son.y-point_father.y==2:
angle=10
return angle
if point_son.x-point_father.x==-1 and point_son.y-point_father.y==1:
angle=11
return angle
if point_son.x-point_father.x==-2 and point_son.y-point_father.y==1:
angle=12
return angle
if point_son.x-point_father.x==-1 and point_son.y-point_father.y==0:
angle=13
return angle
if point_son.x-point_father.x==-2 and point_son.y-point_father.y==-1:
angle=14
return angle
if point_son.x-point_father.x==-1 and point_son.y-point_father.y==-1:
angle=15
return angle
if point_son.x-point_father.x==-1 and point_son.y-point_father.y==-2:
angle=16
return angle
Step4:如果那些节点不在开链表OPEN? 中,则把它们加入到开链表OPEN 中,
根据节点n 计算那些节点的真实代价G,?? 预估代价H,?? 全局评估值f;?? 把节点n 设置为那些节点的父节点。
Step5: 如果那些节点已经在开链表 OPEN 中,则根据节点n 计算那些节点的 真实代价G, 判断从新计算的 G 是小于原本的G, 是则更新那些节点真实代价 G,?? 预估代价 H,?? 全局评估值f,?? 把节点 n 设置为那些节点的父节点;否则不做操作。
Step6:?? 循环以上步骤,直至将终点T?加入开链表?OPEN,? 循环结束,将终点
T加入闭链表CLOSE。
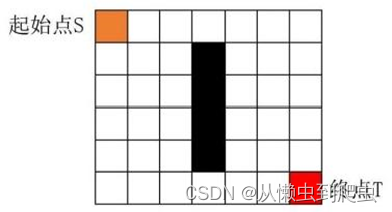
Step7: 反向遍历闭链表CLOSE,? 从终点 T 求得其父节点 T 父节点,在求 T 又节点 的父节点直至到初始点S,?? 这些节点即为路径节点。相应流程图如图5-4所示。
传统A*算法缺点分析
虽然传统的A*算法在一些简单的场景具有一定的有效性,但是实际的用途中, 环境复杂性对于算法实时的要求,传统的A*算法并无法满足要求。只有对传统算 法的局限性进行深入了解分析才能更好的在传统方法之上进行更进一步的改进,
因此本小节深入分析传统 A*算法的局限性和不足,具体有:
(1)栅格地图建模的不足:
首先要意识到的是处理的是离散数据,而不是现实世界中的“连续”地形。采样 的数字地形图像是真实地形的近似值,应该在一个理想的高分辨率采样。数字地形 图像的分辨率越高,对真实地形的描述越逼真,寻径精度也越高。然而,在分辨率 上存在一个上限,超过这个上限后,道路就不再更加精确,并且会不必要地增加寻 径算法的运行时间。而且传统的建模方式只限定为可行驶区域和障碍物区域,然而 现实世界环境是及其复杂的,例如可行驶区域可区分为不同道路,沙地、草地、土质路面等等;障碍物也区分有树、行人、车辆建筑物等等。
(2)邻域节点选择不足:
为了找到从起始节点到目标节点的路径,我们必须定义一种选择后续节点的 方式。我们可以从一个给定的位置移动到哪里?在现实世界中, 一个人可以朝着喜 欢的任何方向前进,但在数字地形图上,我们的选择更受限制。传统的A* 算法中。有两种常见的方法:4个邻接和8个邻接。4个邻接限制移动在北、南、西、东四个主要风向。8邻接的移动更自由,因为它除了4邻接的方向外,还可以在东北、西北、西南和东南方向移动。
#障碍物分布
def obstacle_dis(self,minF):
if minF.father==None:
return 1
angle=self.Angle(minF.father.point,minF.point)#主方向
#print(angle)
if angle==1:
x_left=minF.point.x-2
x_right=minF.point.x+2
y_up=minF.point.y-5
if x_left<0:
x_left=0
if x_right>(w-1):
x_right=(w-1)
if y_up<0:
y_up=0
N=0#障碍物数
s=0#总网格数
for i in range(x_left,x_right+1):
for j in range(y_up,minF.point.y+1):
s=s+1
N=N+map2d[i][j]
P0=N/s#障碍率
#print(P0)
#print(N)
#print(s)(3)算法无法自适应满足不同任务要求:
在不同的任务要求中,有的任务要保证路径的最短,则设计预估代价小于真实 代价,但是效率低下;有的任务要保证效率的高效,设计预估代价大于真实代价,但是规划的路径不是最优。
(4)对于大地图算法计算效率不足:
对于现实的环境场景,可能寻找道路的搜索空间非常大,这意味着必须采取措 施确保内存不会耗尽,或者搜索不会花费过多的时间运行。即使是一个相对较小的300×300像素的地形图也有9万个节点的搜索空间。
5.3 越野环境下的A* 算法
5.3.1 越野环境建模
传统的A*算法的构建方式中最普遍应用的是栅格法,其基本的思路是把智能 车辆的工作空间分割为尺寸一致的网格,并通过数据矩阵来记录环境数据。常规的 栅格算法把物理环境严格区分为自由区域和障碍物区域,从而使得数值矩阵能够 简化为0-1 矩阵,0 为自由空间,1 为障碍物空间。如假设智能车的工作空间为
R×C,M?? 为数值矩阵,R 表示所有的环境信息,则常规的环境模型可以表示为。

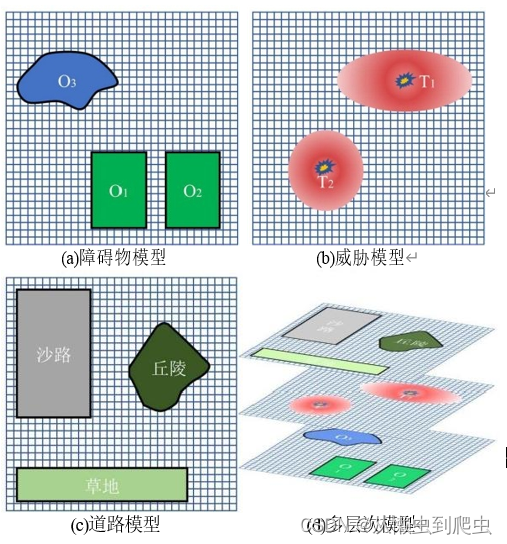
很明显,常规的栅格模型是无法模拟出真实复杂的越野环境,因此本文研究越 野环境的真实场景,建立多层次栅格模型,将越野环境模型细分为障碍物模型,威
胁模型和道路模型,如图5-6所示。
if angle==5:
x_right=minF.point.x+5
y_up=minF.point.y-2
y_dowm=minF.point.y+2
if x_right>(w-1):
x_right=(w-1)
if y_up<0:
y_up=0
if y_dowm>(h-1):
y_dowm=(h-1)
N=0#障碍物数
s=0#总网格数(1)障碍物模型:
障碍物模型即为越野环境中智能车辆无法驶过的区域,如建筑物、森林、山地 等。如图5-6(a)所示,在越野环境中存在障碍物O1-O3, 障碍物之外为安全通行区。
之后的步骤还将添加安全距离,保证智能车能够和障碍物保存一定距离。障碍物模型表示为:
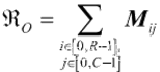
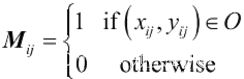
?式中:织。障碍物模型,O障碍物区域,(xy,y;)为越野栅格模型的坐标点
?多层次越野模型
威胁模型:
威胁模型指的是越野环境中可能对智能车造成破坏损伤的存在,如地雷和敌 军等。威胁模型的范围取决于威胁物的风险程度,本文设置威胁等级H 为1~5,则威胁范围为威胁等级 H 的威胁物向外均匀减少至0所覆盖的范围,例: H=3,则威胁范围半径 r 为[3,2,1,0.8,0.6,0.4,0.2,0],每步间隔一个栅格。威胁模型表示
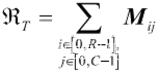
为:
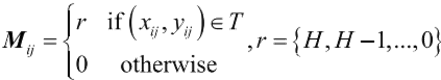
式中:R, 为威胁模型,T 为威胁物,H 为威胁等级,r 为威胁范围半径。如图1(b) 所示,越野环境中存在威胁物 T?,T?,????? 威胁范围沿着威胁物向外扩散直至减少为0。
if angle==9:
x_left=minF.point.x-2
x_right=minF.point.x+2
y_dowm=minF.point.y+5
if x_left<0:
x_left=0
if x_right>(w-1):
x_right=(w-1)
if y_dowm>(h-1):
y_dowm=(h-1)
N=0#障碍物数
s=0#总网格数
for i in range(x_left,x_right+1):
for j in range(minF.point.y,y_dowm+1):
s=s+1
N=N+map2d[i][j]
P0=N/s#障碍率
return P0(3)越野道路模型
道路模型即为越野环境中智能车辆可安全行驶的区域,在越野环境中,可行驶区域大致可分为:硬质路面、土路、草地和沙地等,这些不同的地表具有不同的属 性,对智能车辆具有不同的通行影响。本文参照轮式智能车辆的实验数据和专家经
验值,将不同的地表按照属性设置相应的通过系数,如表所示。
本文根据表5.1,将不同地表属性对车辆的通行影响进行量化,则可以将道路
模型可表示为:
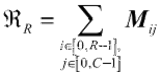
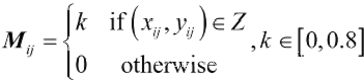
式中: R 为道路模型, Z 越野道路,k为道路通行系数。如图1(c)中所示,越野环 境中存在3处越野道路,例:灰色区域的沙路,在越野栅格模型中的数据值为0.7。?
# 如果在关闭表中,就忽略
currentPoint = Point(minF.point.x + offsetX, minF.point.y + offsetY)#节点位置
if self.pointInCloseList(currentPoint):
return
# 设置单位花费
if offsetX == 0 or offsetY == 0:
step = 10#横向代价为10
if abs(offsetX )== 1 and abs(offsetY )== 1:
step = 14#斜向代价为14
if abs(offsetX )== 2 or abs(offsetY )== 2:
step = 22#大斜向代价为22
最后,得到障碍物模型、威胁模型和道路模型后,融合三个层次的模型,获得 最终的越野栅格模型: R=R 。+R?+R? 。 值得注意的是,三个模型的优先级为:威 胁模型、障碍物模型、道路模型,当融合模型重叠时,优先考虑优先级高的模型以及模型数据值高的栅格。
QQ767172261本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!