了解spark计算模型
简介
????????在集群背后,有一个非常重要的分布式数据架构,即弹性分布式数据集(resilient distributed dataset,RDD),它是逻辑集中的实体,在集群中的多台机器上进行了数据分区。通过对多台机器上不同RDD分区的控制,就能够减少机器之间的数据重排(datashuffling)。Spark提供了“partitionBy”运算符,能够通过集群中多台机器之间对原始RDD进行数据再分配来创建一个新的RDD。RDD是Spark的核心数据结构,通过RDD的依赖关系形成Spark的调度顺序。通过对RDD的操作形成整个Spark程序。
(1)RDD的两种创建方式
????????1)从Hadoop文件系统(或与Hadoop兼容的其他持久化存储系统,如Hive、Cassandra、Hbase)输入(如HDFS)创建。
????????2)从父RDD转换得到新的RDD。
(2)RDD的两种操作算子
对于RDD可以有两种计算操作算子:Transformation(变换)与Action(行动)。
????????1)Transformation(变换)。Transformation操作是延迟计算的,也就是说从一个RDD转换生成另一个RDD的转换操作不是马上执行,需要等到有Actions操作时,才真正触发运算。
????????2)Action(行动)Action算子会触发Spark提交作业(Job),并将数据输出到Spark系统。
(3)RDD的重要内部属性
????????1)分区列表。
????????2)计算每个分片的函数。
????????3)对父RDD的依赖列表。
????????4)对Key-Value对数据类型RDD的分区器,控制分区策略和分区数。
????????5)每个数据分区的地址列表(如HDFS上的数据块的地址)
RDD与分布式共享内存的异同
????????RDD是一种分布式的内存抽象,表1-1列出了RDD与分布式共享内存(Distributed Shared Memory,DSM)的对比。在DSM系统中,应用可以向全局地址空间的任意位置进行读写操作。DSM是一种通用的内存数据抽象,但这种通用性同时也使其在商用集群上实现
有效的容错性和一致性更加困难。RDD与DSM主要区别在于,不仅可以通过批量转换创建(即“写”)RDD,还可以对任意内存位置读写。RDD限制应用执行批量写操作,这样有利于实现有效的容错。特别是,由于RDD可以使用Lineage(血统)来恢复分区,基本没有检查点开销。失效时只需要重新计算丢失的那些RDD分区,就可以在不同节点上并行执行,而不需要回滚(Roll Back)整个程序。

????????通过备份任务的复制,RDD还可以处理落后任务(即运行很慢的节点),这点与MapReduce类似,DSM则难以实现备份任务,因为任务及其副本均需读写同一个内存位置的数据。与DSM相比,RDD模型有两个优势。第一,对于RDD中的批量操作,运行时将根据数据存放的位置来调度任务,从而提高性能。第二,对于扫描类型操作,如果内存不足以缓存整个RDD,就进行部分缓存,将内存容纳不下的分区存储到磁盘上。另外,RDD支持粗粒度和细粒度的读操作。RDD上的很多函数操作(如count和collect等)都是批量读操作,即扫描整个数据集,可以将任务分配到距离数据最近的节点上。同时,RDD也支持细粒度操作,即在哈希或范围分区的RDD上执行关键字查找。后续将算子从两个维度结合在3.3节对RDD算子进行详细介绍。
????????1)Transformations(变换)和Action(行动)算子维度。
????????2)在Transformations算子中再将数据类型维度细分为:Value数据类型和Key-Value对数据类型的Transformations算子。Value型数据的算子封装在RDD类中可以直接使用,KeyValue对数据类型的算子封装于PairRDDFunctions类中,用户需要引入import org.apache.spark.SparkContext._才能够使用。进行这样的细分是由于不同的数据类型处理思想不太一样,同时有些算子是不同的。
?
Spark的数据存储
????????Spark数据存储的核心是弹性分布式数据集(RDD)。RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的。逻辑上RDD的每个分区叫一个Partition。在Spark的执行过程中,RDD经历一个个的Transfomation算子之后,最后通过Action算子进行触发操作。逻辑上每经历一次变换,就会将RDD转换为一个新的RDD,RDD之间通过Lineage产生依赖关系,这个关系在容错中有很重要的作用。变换的输入和输出都是RDD。RDD会被划分成很多的分区分布到集群的多个节点中。分区是个逻辑概念,变换前后的新旧分区在物理上可能是同一块内存存储。这是很重要的优化,以防止函数式数据不变性(immutable)导致的内存需求无限扩张。有些RDD是计算的中间结果,其分区并不一定有相应的内存或磁盘数据与之对应,如果要迭代使用数据,可以调cache()函数缓存数据。
RDD数据管理模型

?图中的RDD_1含有5个分区(p1、p2、p3、p4、p5),分别存储在4个节点(Node1、node2、Node3、Node4)中。RDD_2含有3个分区(p1、p2、p3),分布在3个节点(Node1、Node2、Node3)中。在物理上,RDD对象实质上是一个元数据结构,存储着Block、Node等的映射关系,以及其他的元数据信息。一个RDD就是一组分区,在物理数据存储上,RDD的每个分区对应的
就是一个Block,Block可以存储在内存,当内存不够时可以存储到磁盘上。
????????每个Block中存储着RDD所有数据项的一个子集,暴露给用户的可以是一个Block的迭代器(例如,用户可以通过mapPartitions获得分区迭代器进行操作),也可以就是一个数据项(例如,通过map函数对每个数据项并行计算)。本书会在后面章节具体介绍数据管理的底层实现细节。
如果是从HDFS等外部存储作为输入数据源,数据按照HDFS中的数据分布策略进行数据分区,HDFS中的一个Block对应Spark的一个分区。同时Spark支持重分区,数据通过Spark默认的或者用户自定义的分区器决定数据块分布在哪些节点。例如,支持Hash分区(按照数据项的Key值取Hash值,Hash值相同的元素放入同一个分区之内)和Range分区(将属于同一数据范围的数据放入同一分区)等分区策略。
Spark算子分类及功能
????????1.Saprk算子的作用
? ? ? ? 下图描述了Spark的输入、运行转换、输出。在运行转换中通过算子对RDD进行转换。

????????1)输入:在Spark程序运行中,数据从外部数据空间(如分布式存储:textFile读取HDFS等,parallelize方法输入Scala集合或数据)输入Spark,数据进入Spark运行时数据空间,转化为Spark中的数据块,通过BlockManager进行管理。
? ? ? ? 代码演示(使用parallelize方法读取数据的一个简单案例)
from pyspark.sql import SparkSession
import os
os.environ['JAVA_HOME'] = "/jdk/jdk1.8.0_144"
spark = SparkSession.builder \
.appName("TextFile") \
.master('spark://10.0.0.102:7077') \
.getOrCreate()
data = [1, 10]
data_rdd = spark.sparkContext.parallelize(data)
demo=data_rdd.count()
print(demo)

????????2)运行:在Spark数据输入形成RDD后便可以通过变换算子,如fliter等,对数据进行操作并将RDD转化为新的RDD,通过Action算子,触发Spark提交作业。如果数据需要复用,可以通过Cache算子,将数据缓存到内存。
? ? ? ? 3)输出:程序运行结束数据会输出Spark运行时空间,存储到分布式存储中(如saveAsTextFile输出到HDFS),或Scala数据或集合中(collect输出到Scala集合,count返回Scala int型数据)。
????????Spark的核心数据模型是RDD,但RDD是个抽象类,具体由各子类实现,如MappedRDD、ShuffledRDD等子类。Spark将常用的大数据操作都转化成为RDD的子类。
????????2.算子的分类
大致可以分为三大类算子。
????????1)Value数据类型的Transformation算子,这种变换并不触发提交作业,针对处理的数
据项是Value型的数据。
????????2)Key-Value数据类型的Transfromation算子,这种变换并不触发提交作业,针对处理
的数据项是Key-Value型的数据对。
????????3)Action算子,这类算子会触发SparkContext提交Job作业。
这些算子,可以通俗的理解为就是函数,用于对源数据进行处理的函数。而三类算子再泛而论之,可以分为转换算子(Transformation)和动作算子(Action)。触发SparkContext提交Job的是动作算子,因为动作算子会触发实际的计算并返回结果给Driver程序或保存结果到外部存储系统。
????????通过调用sparkContext创建spark会话,在rdd.之后还能看到很多算子,也就是我们通俗理解的函数,这里例举一些作为展示

????????本文不再对其算子的功能一一列出,感兴趣的读者可自行对其算子进行代码演练,以加深印象。?
算子代码示例
from pyspark.sql import SparkSession
import os
os.environ['JAVA_HOME'] = "/jdk/jdk1.8.0_144"
# 创建 Spark 会话
spark = SparkSession.builder \
.appName("text") \
.master("spark://10.0.0.102:7077") \
.getOrCreate()
# 创建一个简单的RDD
data = [1, 2, 3, 4, 5]
rdd = spark.sparkContext.parallelize(data)
print("Original RDD: {}".format(rdd.collect()))
# 转换算子:对每个元素进行平方操作
squared_rdd = rdd.map(lambda x: x**2)
print("Squared RDD: {}".format(squared_rdd.collect()))
# 转换算子:过滤出偶数
even_rdd = rdd.filter(lambda x: x % 2 == 0)
print("Even Numbers RDD: {}".format(even_rdd.collect()))
# 动作算子:计算平方后的RDD的和
sum_squared = squared_rdd.reduce(lambda x, y: x + y)
print("Sum of Squared RDD: {}".format(sum_squared))
# 动作算子:将结果收集到本地
collected_data = squared_rdd.collect()
print("Collected Data: {}".format(collected_data))
# 停止 Spark 会话
spark.stop()
??Actions算子
????????本质上在Actions算子中通过SparkContext执行提交作业的runJob操作,触发了RDD DAG的执行。以下简单例举三个Actions算子,作为讲解。
????????(1)foreach
对RDD中的每个元素都应用f函数操作,不返回RDD和Array,而是返回Uint。
????????(2)saveAsTextFile
函数将数据输出,存储到HDFS的指定目录。
???????(3)saveAsObjectFile ?
saveAsObjectFile将分区中的每10个元素组成一个Array,然后将这个Array序列化,映
射为(Null,BytesWritable(Y))的元素,写入HDFS为SequenceFile的格式。
? ? ? ? 注:在学习spark过程,博主认为不需要过度去研究算子的分类,博客列举出来,只为让各位做一个了解。后续更多还是会例举实战应用给大家讲一讲spark在生产中的应用优势。
?
Spark执行机制总览
????????Spark应用提交后经历了一系列的转换,最后成为Task在每个节点上执行。Spark应用转换:RDD的Action算子触发Job的提交,提交到Spark中的Job生成RDD DAG,由DAGScheduler转化为Stage DAG,每个Stage中产生相应的Task集合,TaskScheduler将任务分发到Executor执行。每个任务对应相应的一个数据块,使用用户定义的函数处理数据块。

????????Spark执行的底层实现原理,如下图所示。在Spark的底层实现中,通过RDD进行数据的管理,RDD中有一组分布在不同节点的数据块,当Spark的应用在对这个RDD进行操作时,调度器将包含操作的任务分发到指定的机器上执行,在计算节点通过多线程的方式执行任务。一个操作执行完毕,RDD便转换为另一个RDD,这样,用户的操作依次执行。Spark为了系统的内存不至于快速用完,使用延迟执行的方式执行,即只有操作累计到Action(行动),算子才会触发整个操作序列的执行,中间结果不会单独再重新分配内存,而是在同一个数据块上进行流水线操作。在集群的程序实现上,有一个重要的分布式数据结构,即弹性分布式数据集(Resilient Distributed Dataset,RDD)。Spark实现了分布式计算和任务处理,并实现了任务的分发、跟踪、执行等工作,最终聚合结果,完成Spark应用的计算。对RDD的块管理通过BlockManger完成,BlockManager将数据抽象为数据块,在内存或者磁盘进行存储,如果数据不在本节点,则还可以通过远端节点复制到本机进行计算。?

????????在计算节点的执行器Executor中会创建线程池,这个执行器将需要执行的任务通过线程
池并发执行。?
?
spark应用的概念
????????Spark应用(Application)是用户提交的应用程序。执行模式有Local、Standalone、YARN、Mesos。根据Spark Application的Driver Program是否在集群中运行,Spark应用的运行方式又可以分为Cluster模式和Client模式。图4-3为Application包含的组件。应用的基本组件如下。
????????·Application:用户自定义的Spark程序,用户提交后,Spark为App分配资源,将程序转换并执行。
????????·Driver Program:运行Application的main()函数并创建SparkContext。
????????·RDD Graph:RDD是Spark的核心结构,可以通过一系列算子进行操作(主要有Transformation和Action操作)。当RDD遇到Action算子时,将之前的所有算子形成一个有向无环图(DAG),也就是图中的RDD Graph。再在Spark中转化为Job,提交到集群执行。一个App中可以包含多个Job。
????????·Job:一个RDD Graph触发的作业,往往由Spark Action算子触发,在SparkContext中通过runJob方法向Spark提交Job。
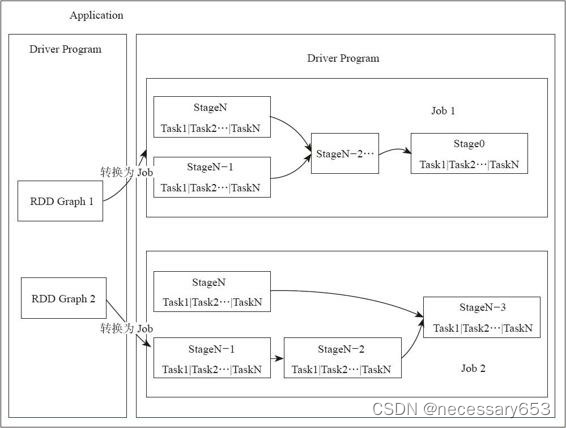
????????Stage:每个Job会根据RDD的宽依赖关系被切分很多Stage,每个Stage中包含一组相同的Task,这一组Task也叫TaskSet。
????????·Task:一个分区对应一个Task,Task执行RDD中对应Stage中包含的算子。Task被封装好后放入Executor的线程池中执行。?
应用提交与执行方式
????????应用的提交包含以下两种方式。
????????·Driver进程运行在客户端,对应用进行管理监控。
????????·主节点指定某个Worker节点启动Driver,负责整个应用的监控。
Driver进程是应用的主控进程,负责应用的解析、切分Stage并调度Task到Executor执行,包含DAGScheduler等重要对象。下面具体介绍这两种方式的原理。
Driver在客户端运行

????????用户启动客户端,之后客户端运行用户程序,启动Driver进程。在Driver中启动或实例化DAGScheduler等组件。客户端的Driver向Master注册。Worker向Master注册,Master命令Worker启动Exeuctor。Worker通过创建ExecutorRunner线程,在ExecutorRunner线程内部启动ExecutorBackend进程。ExecutorBackend启动后,向客户端Driver进程内的SchedulerBackend注册,这样Driver进程就能找到计算资源。Driver的DAGScheduler解析应用中的RDD DAG并生成相应的Stage,每个Stage包含的TaskSet通过TaskScheduler分配给Executor。在Executor内部启动
线程池并行化执行Task。?
Driver在Worker运行?
????????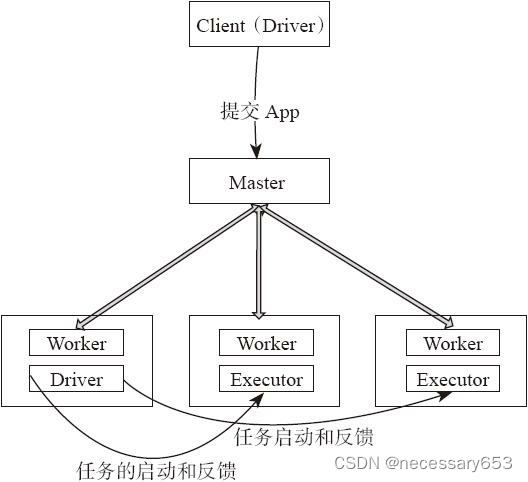
????????1)用户启动客户端,客户端提交应用程序给Master。
?????????2)Master调度应用,针对每个应用分发给指定的一个Worker启动Driver,即SchedulerBackend。Worker接收到Master命令后创建DriverRunner线程,在DriverRunner线程内创建SchedulerBackend进程。Driver充当整个作业的主控进程。Master会指定其他Worker启动
Exeuctor,即ExecutorBackend进程,提供计算资源。流程和上面很相似,Worker创建
ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程。
????????3)ExecutorBackend启动后,向Driver的SchedulerBackend注册,这样Driver获取了计算资源就可以调度和将任务分发到计算节点执行。SchedulerBackend进程中包含DAGScheduler,它会根据RDD的DAG切分Stage,生成TaskSet,并调度和分发Task到Executor。对于每个Stage的TaskSet,都会被存放到TaskScheduler中。TaskScheduler将任务分发到Executor,执行多线程并行任务。?
????????博主认为作为初学spark,了解运行原理可以帮助后期排错,更有帮助。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!