最新版ES8的client API操作 Elasticsearch Java API client 8.0
作者:ChenZhen
本人不常看网站消息,有问题通过下面的方式联系:
- 邮箱:1583296383@qq.com
- vx: ChenZhen_7
我的个人博客地址:https://www.chenzhen.space/🌐
版权:本文为博主的原创文章,本文版权归作者所有,转载请附上原文出处链接及本声明。📝
如果对你有帮助,请给一个小小的star?🙏
Elasticsearch Java client 8.0
Elasticsearch:使用最新的 Elasticsearch Java client 8.0 来创建索引并搜索
我们在学习ES客户端时,一直使用的都是Java High Level Rest Client,在浏览官网时,发现官方给出的警告是:Java REST 客户端已被弃用,取而代之的是 Java API client 客户端,ES 8.x 新版本中,Type 概念被弃用,所以新版 JavaAPI 也相应做出了改变,使用更加简便。ES 官方从 7.15 起开始建议使用新的 JavaAPI
如何使用最新的 Elasticsearch Java client 8.0 来创建索引并进行搜索。最新的 Elasticsearch Java client API 和之前的不同。在es7的一些教程中,经常使用 High Level API 来进行操作。但在官方文档中,已经显示为 deprecated。
Java API Client
官网为啥又推出一个新的客户端接口呢,这是为了统一管理,官网给出的回应是:将来只对这个客户端进行维护改进,这也接口会更加的清晰明了,可读性更高,更易于上手,更简单!代码看着更加简洁了!
无论是ElasticsearchTemplate类还是ElasticsearchRepository接口,都是对ES常用的简单功能进行封装,在实际使用时,复杂的查询语法还是依赖ElasticsearchClient和原生的API封装;
更详细内容参考官网API文档:https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/current/package-structure.html
开始
本文将指导您完成 Java 客户端的安装过程,向您展示如何实例化客户端,以及如何使用它执行基本的 Elasticsearch 操作。
安装
在项目的 pom.xml 中,添加以下存储库定义和依赖项:
<project>
<dependencies>
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.10.4</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.3</version>
</dependency>
</dependencies>
</project>
你可以使用API密钥和Elasticsearch端点来连接到Elastic 。
-
RestClient这个类主要是用作于与服务端IP以及端口的配置,在其的builder()方法可以设置登陆权限的账号密码、连接时长等等。总而言之就是服务端配置。 -
RestClientTransport这是Jackson映射器创建传输。建立客户端与服务端之间的连接传输数据。这是在创建ElasticsearchClient需要的参数,而创建RestClientTransport就需要上面创建的RestClient。 -
ElasticsearchClient这个就是Elasticsearch的客户端。调用Elasticsearch语法所用到的类,其就需要传入上面介绍的RestClientTransport。
// URL和API密钥
String serverUrl = "https://localhost:9200";
String apiKey = "VnVhQ2ZHY0JDZGJrU...";
// 创建低级别客户端
RestClient restClient = RestClient
.builder(HttpHost.create(serverUrl))
.setDefaultHeaders(new Header[]{
new BasicHeader("Authorization", "ApiKey " + apiKey)
})
.build();
// 使用Jackson映射器创建传输
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
// 然后创建API客户端
ElasticsearchClient client = new ElasticsearchClient(transport);
得到API客户端对象client ,你就可以进行Elasticsearch的基本操作,以下是一些最基本的操作。
简单操作
创建索引
下面的代码片段显示了如何使用 indices 命名空间客户端创建索引(lambda 语法在下面进行了说明):
// 创建索引products
client.indices().create(c -> c.index("products"));
判断索引是否存在并创建索引(构建器写法与lambda写法)
lambda写法:
// 获取【索引客户端对象】
ElasticsearchIndicesClient indexClient = client.indices();
boolean flag = indexClient.exists(req -> req.index(iName)).value();
//CreateIndexResponse createIndexResponse = null;
boolean result = false;
if (flag) {
// 目标索引已存在
log.info("索引【" + iName + "】已存在!");
} else {
// 不存在
result = indexClient.create(req -> req.index(iName)).acknowledged();
if (result) {
log.info("索引【" + iName + "】创建成功!");
} else {
log.info("索引【" + iName + "】创建失败!");
}
}
构建器写法
// 获取【索引客户端对象】
ElasticsearchIndicesClient indexClient = client.indices();
//1、构建【存在请求对象】
ExistsRequest existsRequest = new ExistsRequest.Builder().index(indexName).build();
//2、判断目标索引是否存在
boolean flag = indexClient.exists(existsRequest).value();
if (flag) {
// 目标索引已存在
log.info("索引【" + iName + "】已存在!");
} else {
//1. 获取【创建索引请求对象】
CreateIndexRequest createIndexRequest = new CreateIndexRequest.Builder().index(indexName).build();
//2. 创建索引,得到【创建索引响应对象】
CreateIndexResponse createIndexResponse = indexClient.create(createIndexRequest);
createIndexResponse = indexClient.create(req -> req.index(indexName));
//System.out.println("创建索引响应对象:" + createIndexResponse);
boolean result= indexName.acknowledged();
if (result) {
log.info("索引【" + indexName + "】创建成功!");
} else {
log.info("索引【" + indexName + "】创建失败!");
}
}
可以看到构建器写法在简洁度上完全不如lambda表达式,接下来所有例子均只采用lambda写法
查询索引
Map<String, IndexState> result = client.indices().get(req -> req.index("indexName")).result();
查询全部索引
Set<String> all = client.indices().get(req -> req.index("*")).result().keySet();
删除索引
Boolean isDelete = client.indices().delete(req -> req.index("indexName")).acknowledged();
if(isDelete ) {
log.info("删除索引成功");
} else {
log.info("删除索引失败");
}
插入文档
生成请求的最直接方法是使用流畅的 DSL。在下面的示例中,我们使用产品的 SKU 作为索引中的文档标识符,在产品索引中为products描述编制索引。product对象将使用 Elasticsearch 客户端上配置的对象映射器映射到 JSON。
Product product = new Product("bk-1", "City bike", 123.0);
IndexResponse response = client.index(i -> i
.index("products")
.id(product.getSku())
.document(product)
);
logger.info("Indexed with version " + response.version());
还可以将使用 DSL 创建的对象分配给变量。Java API 客户端类有一个静态of() 方法,它使用 DSL 语法创建一个对象。
Product product = new Product("bk-1", "City bike", 123.0);
IndexRequest<Product> request = IndexRequest.of(i -> i
.index("products")
.id(product.getSku())
.document(product)
);
IndexResponse response = client.index(request);
logger.info("Indexed with version " + response.version());
使用原始 JSON 数据
当您要索引的数据来自外部源时,对于半结构化数据,必须创建域对象可能会很麻烦或完全不可能。
您可以使用 withJson() 为任意源的数据编制索引。使用此方法将读取源并将其用于索引请求的document属性。
Reader input = new StringReader(
"{'@timestamp': '2022-04-08T13:55:32Z', 'level': 'warn', 'message': 'Some log message'}"
.replace('\'', '"'));
IndexRequest<JsonData> request = IndexRequest.of(i -> i
.index("logs")
.withJson(input)
);
IndexResponse response = client.index(request);
logger.info("Indexed with version " + response.version());
批量请求:多个文档
批量请求允许在一个请求中发送多个与文档相关的操作到 Elasticsearch。当你有多个文档需要导入时,这比分别发送每个文档的请求更有效率。
一个批量请求可以包含多种类型的操作:
- 创建一个文档,在确保它不存在后进行索引
- 索引一个文档,如果需要则创建它,如果已经存在则替换它
- 更新一个已经存在的文档,可以使用脚本或部分文档
- 删除一个文档
一个批量请求包含一系列操作,每个操作都是一种类型,有几个变种。为了创建这个请求,最方便的方法是使用主请求的构建器对象以及每个操作的流畅式 DSL。
下面的示例展示了如何索引一个应用程序对象列表。
List<Product> products = fetchProducts();
BulkRequest.Builder br = new BulkRequest.Builder();
for (Product product : products) {
br.operations(op -> op
.index(idx -> idx
.index("products")
.id(product.getSku())
.document(product)
)
);
}
BulkResponse result = client.bulk(br.build());
// Log errors, if any
if (result.errors()) {
logger.error("Bulk had errors");
for (BulkResponseItem item: result.items()) {
if (item.error() != null) {
logger.error(item.error().reason());
}
}
}
批量的脚本操作:
for (ProductDTO productDTO : Optional.ofNullable(productResult.getData()).orElse(Collections.emptyList())) {
Map<String, JsonData> params = new HashMap<>(16);
params.put("buys", JsonData.of(productDTO.getBuys()));
params.put("views", JsonData.of(productDTO.getViews()));
params.put("comments", JsonData.of(productDTO.getComments()));
br.operations(op -> op
.update(u -> u
.id(String.valueOf(productDTO.getId()))
.index(searchProperties.getProductIndexName())
.action(a -> a
.script(s -> s
.inline(i -> i
.source("ctx._source.buys = params.buys;" +
"ctx._source.views = params.views;" +
"ctx._source.comments = params.comments;")
.params(params))))
)
);
}
查询文档
Elasticsearch主要用于搜索,但你也可以直接访问文档,通过id 。
下面的示例从"products"索引中读取id "bk-1"的文档。
get请求有两个参数:
- 第一个参数是实际请求,使用DSL构建
- 第二个参数是我们希望将文档的JSON映射到的类。
GetResponse<Product> response = client.get(g -> g
.index("products")
.id("bk-1"),
Product.class
);
if (response.found()) {
Product product = response.source();
logger.info("产品名称 " + product.getName());
} else {
logger.info("未找到产品");
}
这个get请求包括索引名称和标识符。
目标类,在这里是
Product。
如果你的索引包含半结构化数据,或者如果你没有对象的定义,你也可以将文档作为原始JSON数据来读取。
原始JSON数据只是另一个类,你可以将其用作get请求的结果类型。在下面的示例中,我们使用了Jackson的ObjectNode。我们也可以使用任何可以由与ElasticsearchClient关联的JSON映射器反序列化的JSON表示。
GetResponse<ObjectNode> response = client.get(g -> g
.index("products")
.id("bk-1"),
ObjectNode.class
);
if (response.found()) {
ObjectNode json = response.source();
String name = json.get("name").asText();
logger.info("产品名称 " + name);
} else {
logger.info("未找到产品");
}
1.目标类是一个原始的JSON对象。
修改文档
UpdateResponse updateResponse = client.update(u -> u
.doc(textBook)
.id(id),
TextBook.class
删除文档
DeleteResponse deleteResponse = client.delete(d -> d
.index(index)
.id(id)
);
命名空间
在REST API文档中,数量众多API是按照特性(feature)来分组的,如下图:
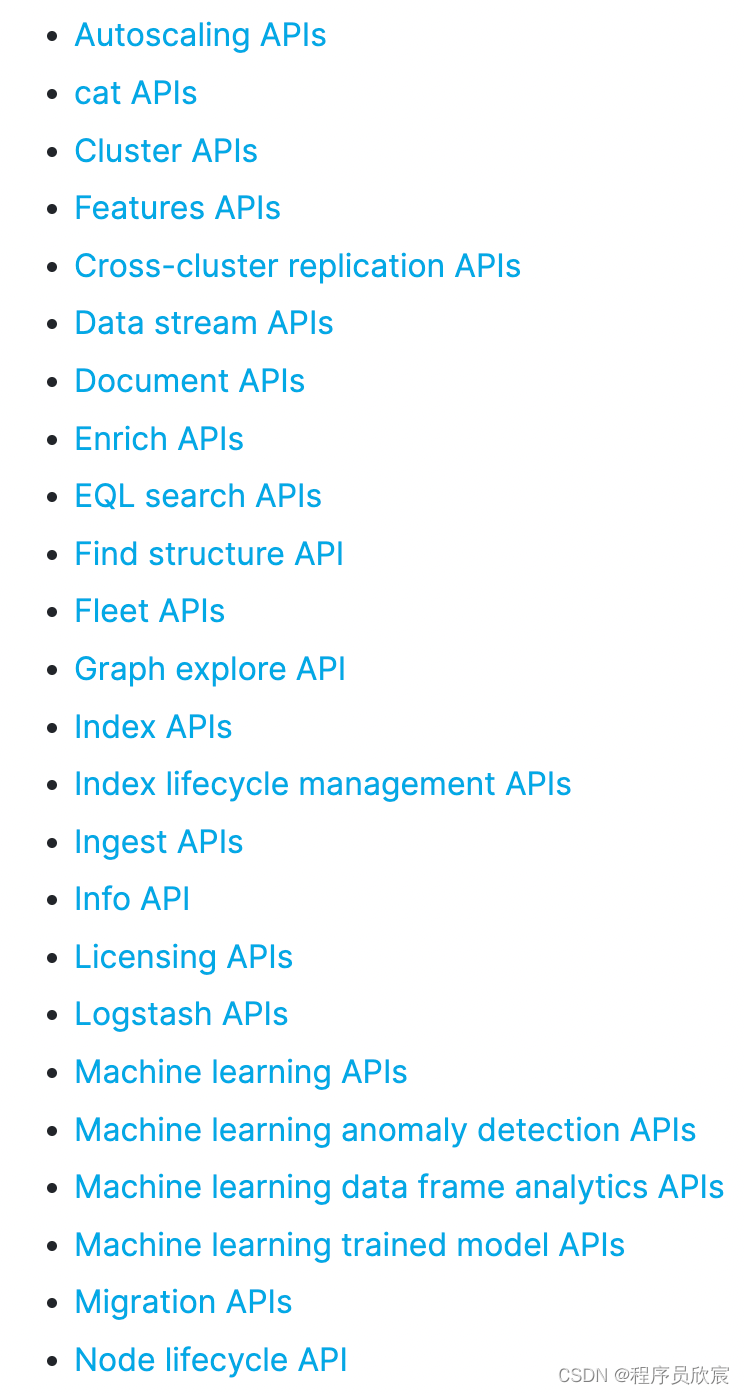
在ES的Java库Java API Client中,上图中的各种feature被称为namespace
在ES的Java库Java API Client中,与REST API对应的的类和接口都在统一的包名co.elastic.clients.elasticsearch之下,然后再通过下一级package进行分类,这个分类与上图的feature相对应。例如索引相关的,在REST API中的feature是Index APIs,那么在Java API Client中,完整的package就是co.elastic.clients.elasticsearch.indices,这里面有索引操作所需的请求、响应、服务等各种类.
每一个namespace(也就是REST API中的feature),都有自己的client,例如索引相关的操作都有索引专用的client类负责,client.indices()返回的是ElasticsearchIndicesClient对象,这是索引操作专用的实例
ElasticsearchClient client = ......
client.indices().create(c -> c.index("products"));
展开上述代码的indices()方法,看看其内部实现,如下所示,每次调用indices方法,都会创建一个ElasticsearchIndicesClient对象,对于其他namespace,例如ingest、license亦是如此,都会创建新的实例
每个namespace都有自己的client,但也有例外,就是search和document,它们的代码不在search或者document这样的package下面,而是在core下面,而且可以直接通过ElasticsearchClient来操作,如下:
插入一条文档:
Product product = new Product("bk-1", "City bike", 123.0);
IndexResponse response = client.index(i -> i
.index("products")
.id(product.getSku())
.document(product)
);
logger.info("Indexed with version " + response.version());
构建 API 对象
1.构建器模式
ElasticsearchClient client = ......
CreateIndexResponse createResponse = client.indices().create(
new CreateIndexRequest.Builder()
.index("my-index")
.aliases("foo",
new Alias.Builder().isWriteIndex(true).build()
)
.build()
);
2.lambda 表达式
虽然这效果很好,但必须实例化构建器类并调用 build() 方法有点冗长。因此,Java API 客户端中的每个属性设置器也接受一个 lambda 表达式,该表达式将新创建的构建器作为参数,并返回填充的构建器。上面的片段也可以写成:
ElasticsearchClient client = ......
CreateIndexResponse createResponse = client.indices()
.create(createIndexBuilder -> createIndexBuilder
.index("my-index")
.aliases("foo", aliasBuilder -> aliasBuilder
.isWriteIndex(true)
)
);
这种方法允许更简洁的代码,并且还避免了导入类(甚至记住它们的名称),因为类型是从方法参数签名推断出来的。建议大家这样去写,非常简洁快速,后面的各种操作我也会用这种方式来书写。
生成器 lambda 对于复杂的嵌套查询(如下所示)特别有用
{
"query": {
"intervals": {
"field": "my_text",
"all_of": [
{
"ordered": true,
"intervals": [
{
"match": {
"query": "my favorite food",
"max_gaps": 0,
"ordered": true
}
}
]
},
{
"any_of": {
"intervals": [
{
"match": {
"query": "hot water"
}
},
{
"match": {
"query": "cold porridge"
}
}
]
}
}
]
}
}
}
对应的代码如下:
SearchResponse<SomeApplicationData> results = client
.search(b0 -> b0
.query(b1 -> b1
.intervals(b2 -> b2
.field("my_text")
.allOf(b3 -> b3
.ordered(true)
.intervals(b4 -> b4
.match(b5 -> b5
.query("my favorite food")
.maxGaps(0)
.ordered(true)
)
)
.intervals(b4 -> b4
.anyOf(b5 -> b5
.intervals(b6 -> b6
.match(b7 -> b7
.query("hot water")
)
)
.intervals(b6 -> b6
.match(b7 -> b7
.query("cold porridge")
)
)
)
)
)
)
),
SomeApplicationData.class
);
复杂查询
搜索查询
有许多类型的搜索查询可以组合使用。我们将从简单的文本匹配查询开始,在products索引中搜索自行车。我们在这里选择匹配查询(全文搜索)
- 搜索结果具有
hits属性,其中包含与查询匹配的文档以及有关索引中存在的匹配项总数的信息。 - 总值带有一个关系,该关系指示总值是精确的(eq — 相等)还是近似的(gte — 大于或等于)。
- 每个返回的文档都附带其相关性分数以及有关其在索引中的位置的其他信息。
String searchText = "自行车";
SearchResponse<Product> response = client.search(s -> s
.index("products")
.query(q -> q
.match(t -> t
.field("name")
.query(searchText)
)
),
Product.class
);
TotalHits total = response.hits().total();//total可以获取结果的总数
boolean isExactResult = total.relation() == TotalHitsRelation.Eq;
if (isExactResult) {
logger.info("找到 " + total.value() + " 个结果");
} else {
logger.info("找到超过 " + total.value() + " 个结果");
}
List<Hit<Product>> hits = response.hits().hits();
for (Hit<Product> hit: hits) {
Product product = hit.source();
logger.info("找到产品 " + product.getSku() + ",得分 " + hit.score());
}
与获取操作类似,您可以使用相应的目标类而不是 Product(如 JSON-P 的 JsonValue 或 Jackson 的 ObjectNode)将匹配查询的文档作为原始 JSON 获取.
bool查询
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepTextBook() throws IOException {
SearchResponse<TextBook> boolSearch = client.search(s -> s
.index(index)
.query(q -> q
.bool(b -> b
.must(m -> m
.term(t -> t
.field("author")
.value("老坛")
)
)
.should(sh -> sh
.match(t -> t
.field("bookName")
.query("老坛")
)
)
)
),
TextBook.class);
for (Hit<TextBook> hit: boolSearch.hits().hits()) {
TextBook pd = hit.source();
System.out.println(pd);
}
}
}
对应了ES的bool查询,它等价的ES语法就是:
GET textbook/_search
{
"query":{
"bool":{
"should":{
"match":{
"bookName":"老坛"
}
},
"must":{
"term":{
"author":"老坛"
}
}
}
}
}
嵌套搜索查询
在下面的示例中,我们将搜索最高价格为 200 的自行车。
Java API 客户端Query类有一个静态of() 方法,它使用 DSL 语法创建一个对象。
String searchText = "自行车";
double maxPrice = 200.0;
// 根据产品名称搜索
Query byName = MatchQuery.of(m -> m
.field("name")
.query(searchText)
)._toQuery();
// 根据最高价格搜索
Query byMaxPrice = RangeQuery.of(r -> r
.field("price")
.gte(JsonData.of(maxPrice))
)._toQuery();
// 组合产品名称和价格查询来搜索产品索引
SearchResponse<Product> response = client.search(s -> s
.index("products")
.query(q -> q
.bool(b -> b
.must(byName)
.must(byMaxPrice)
)
),
Product.class
);
List<Hit<Product>> hits = response.hits().hits();
for (Hit<Product> hit : hits) {
Product product = hit.source();
logger.info("找到产品 " + product.getSku() + ",得分 " + hit.score());
}
在大量并发频繁执行各种namespace操作时,会创建大量client对象,这样会影响系统性能吗?
官方说这是轻量级对象(very lightweight),所以,理论上可以放心创建,不必担心其对系统造成的压力
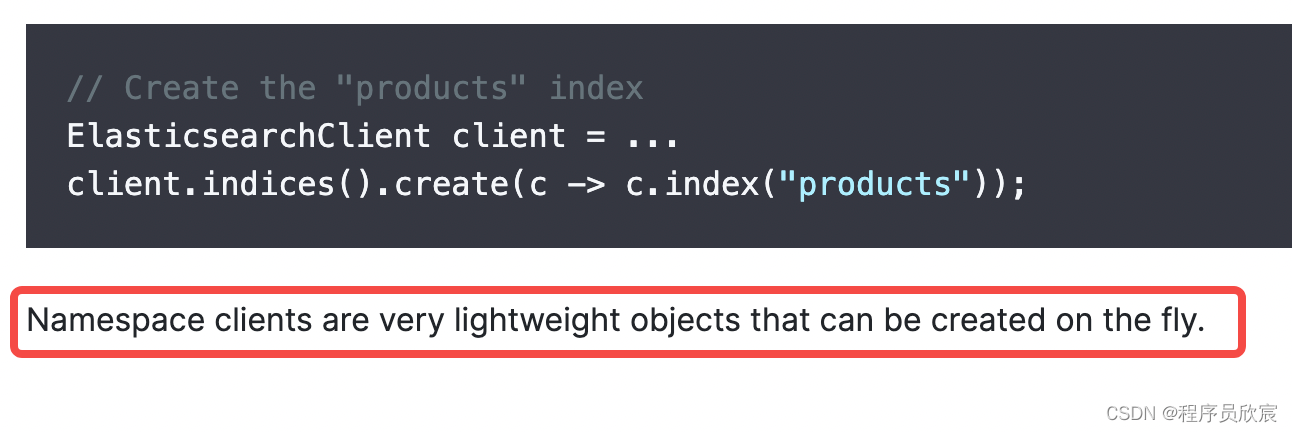
同时,这段代码的目的是为了实现逻辑功能,代码的可读性和维护性通常比微小的内存浪费更重要。如果通过将这段逻辑放在条件块内,来避免不使用的 boolQueryBuilder,可能会使代码更复杂和难以阅读。
拼接查询条件
可以选择性的拼接条件,我们先创建一个SearchRequest.Builder请求对象构建器,然后拼接条件。
// 1. 创建查询构建器
co.elastic.clients.elasticsearch.core.SearchRequest.Builder searchBuilder =
new co.elastic.clients.elasticsearch.core.SearchRequest.Builder();
//设置索引名称
searchBuilder
.index(searchProperties.getProductIndexName());
if (StrUtil.isBlank(request.getKey())) {
Query query = Query.of(q -> q
.bool(b -> b
.must(m -> m.matchAll(m1 -> m1))));
} else {
Query query = Query.of(q -> q
.bool(b1 -> b1
.should(s -> s
.matchPhrase(m1 -> m1
.field("productName").query(request.getKey()).boost(3f)))
.should(s1 -> s1
.matchPhrase(m2 -> m2
.field("shopName").query(request.getKey())))
.should(s2 -> s2
.matchPhrase(m3 -> m3
.field("brandName").query(request.getKey())))
));
//根据条件拼接不同query
searchBuilder
.query(query);
//查询
co.elastic.clients.elasticsearch.core.SearchRequest searchRequest = searchBuilder.build();
SearchResponse<ProductDocument> response = client.search(searchRequest, ProductDocument.class);
term查询
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepTextBook() throws IOException {
SearchResponse<TextBook> termSearch = client.search(s -> s
.index(index)
.query(q -> q
.term(t -> t
.field("bookName")
.value("老坛")
)
),
TextBook.class);
for (Hit<TextBook> hit: termSearch.hits().hits()) {
TextBook pd = hit.source();
System.out.println(pd);
}
}
}
对应了ES的term查询,它等价的ES语法就是:
GET textbook/_search
{
"query": {
"term": {
"bookName":"老坛"
}
}
}
terms查询
List<Long> skuIds = new ArrayList<>();
skuIds.add(1L);
skuIds.add(2L);
skuIds.add(3L);
// 创建 "skuIds" 条件tems查询
TermsQuery bySkuIds = TermsQuery.of(t -> t
.field("skuIds")
.terms(t2 -> t2
.value(skuIds.stream().map(FieldValue::of).collect(Collectors.toList())))
);
//查询命令
SearchResponse<ActivityDocument> search = client.search(s -> s
.index("activity")
.query(q -> q
.terms(bySkuIds)
)
, ActivityDocument.class);
对应了ES的terms查询,它等价的ES语法就是:
{
"query": {
"terms": {
"skuIds ": [1,2,3]
}
}
}
match_phrase查询
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepTextBook() throws IOException {
SearchResponse<TextBook> matchPhraseSearch = client.search(s -> s
.index(index)
.query(q -> q
.matchPhrase(m -> m
.field("bookName")
.query("老坛")
)
),
TextBook.class);
for (Hit<TextBook> hit: matchPhraseSearch.hits().hits()) {
TextBook pd = hit.source();
System.out.println(pd);
}
}
}
对应了ES的match_phrase查询,它等价的ES语法就是:
GET textbook/_search
{
"query": {
"match_phrase": {
"bookName":"老坛"
}
}
}
multi_match查询
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepTextBook() throws IOException {
SearchResponse<TextBook> multiMatchSearch = client.search(s -> s
.index(index)
.query(q -> q
.multiMatch(m -> m
.query("老坛")
.fields("author", "bookName")
)
),
TextBook.class);
for (Hit<TextBook> hit: multiMatchSearch.hits().hits()) {
TextBook pd = hit.source();
System.out.println(pd);
}
}
}
对应了ES的multi_match查询,它等价的ES语法就是:
GET textbook/_search
{
"query": {
"multi_match": {
"query": "老坛",
"fields": ["author","bookName"]
}
}
}
fuzzy查询
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepTextBook() throws IOException {
SearchResponse<TextBook> fuzzySearch = client.search(s -> s
.index(index)
.query(q -> q
.fuzzy(f -> f
.field("bookName")
.fuzziness("2")
.value("老坛")
)
),
TextBook.class);
for (Hit<TextBook> hit: fuzzySearch.hits().hits()) {
TextBook pd = hit.source();
System.out.println(pd);
}
}
}
对应了ES的fuzzy查询,它等价的ES语法就是:
GET textbook/_search
{
"query": {
"fuzzy": {
"bookName":{
"value":"老坛",
"fuzziness":2
}
}
}
}
range查询
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepTextBook() throws IOException {
SearchResponse<TextBook> rangeSearch = client.search(s -> s
.index(index)
.query(q -> q
.range(r -> r
.field("bookName")
.gt(JsonData.of(20))
.lt(JsonData.of(20))
)
),
TextBook.class);
for (Hit<TextBook> hit: rangeSearch.hits().hits()) {
TextBook pd = hit.source();
System.out.println(pd);
}
}
}
对应了ES的range查询,它等价的ES语法就是:
GET textbook/_search
{
"query": {
"range": {
"bookName": {
"gt":20,
"lt":30
}
}
}
}
高亮查询
实现很简单,请注意,我们定义 HighlightField 即hf,即我们要突出显示的字段。
在这个 HighlightField 中,我们还定义了参数,包括numberOfFragments和fragmentSize。
参数可以设置在highlight的下一级,此时为全局设置(如下面的fragmentSize(50)和numberOfFragments(5)),也可以设置在字段的下一级,此时为字段设置。单个字段的设置优先级高于全局设置。
var response = client.search(s -> s
.index("product")
.query(q -> q.multiMatch(m -> m.fields(List.of("title", "description")).query("Aliens and predator")))
.highlight(h -> h
.type(HighlighterType.Unified)
.fields("title",hf -> hf
.numberOfFragments(0))
.fields("description",hf -> hf
.numberOfFragments(4).fragmentSize(50))
.fragmentSize(50)
.numberOfFragments(5)
)
, Movie.class);
上面的写法等同于:
Map<String, HighlightField> map = new HashMap<>();
map.put("title", HighlightField.of(hf -> hf.numberOfFragments(0)));
map.put("description", HighlightField.of(hf -> hf.numberOfFragments(4).fragmentSize(50)));
Highlight highlight = Highlight.of(
h -> h.type(HighlighterType.Unified)
.fields(map)
.fragmentSize(50)
.numberOfFragments(5)
);
var response = client.search(s -> s
.index("idx_movies")
.query(q -> q.multiMatch(m -> m.fields(List.of("title", "description")).query("Aliens and predator")))
.highlight(highlight)
, Movie.class);
排序和分页
排序和分页直接像ES的语法一样,体现在和query的平级即可。这里已match为例进行介绍。
@SpringBootTest
@Slf4j
public class ESTest {
@Resource
ElasticsearchClient client;
String index = "textbook";
@Test
public void grepTextBook() throws IOException {
SearchResponse<TextBook> matchSearch = client.search(s -> s
.index(index)
.query(q -> q
.match(t -> t
.field("bookName")
.query("老坛")
)
)
.from(1)
.size(100)
.sort(so -> so // 排序操作项
.field(f -> f // 排序字段规则
.field("num")
.order(SortOrder.Desc)
)
),
TextBook.class);
for (Hit<TextBook> hit: matchSearch.hits().hits()) {
TextBook pd = hit.source();
System.out.println(pd);
}
}
}
这是一个根据num字段进行降序排序的查询,按页容量为100对数据进行分页,取第二页数据。
它等价的ES语法就是:
GET textbook/_search
{
"query":{
"match":{
"bookName":"老坛"
}
},
"from":1,
"size":100,
"sort":{
"num":{
"order":"desc"
}
}
}
聚合
这个示例是一种用于分析的聚合操作,我们不需要使用匹配的文档。用于分析的搜索请求通常的一般模式是将结果大小设置为0,将搜索结果的目标类设置为 Void。
如果同样的聚合用于显示产品和价格直方图作为钻取细分,我们会将大小设置为非零值,并使用 Product 作为目标类来处理结果。
String searchText = "自行车";
Query query = MatchQuery.of(m -> m
.field("name")
.query(searchText)
)._toQuery();
SearchResponse<Void> response = client.search(b -> b
.index("products")
.size(0) // 将匹配文档数量设置为零,因为我们只关心价格直方图
.query(query) // 设置用于过滤要执行聚合的产品的查询
.aggregations("price-histogram", a -> a
.histogram(h -> h
.field("price")
.interval(50.0)
)
),
Void.class
);
在上面的代码中,我们首先创建了一个用于产品名称匹配的查询,然后执行了一个搜索请求,其中包含了一个名为 “price-histogram” 的聚合操作,用于创建价格直方图。我们将结果大小设置为零,因为我们只关心聚合结果,不需要匹配的文档。
响应包含了每个请求中的聚合结果。
List<HistogramBucket> buckets = response.aggregations()
.get("price-histogram")
.histogram()
.buckets().array();
for (HistogramBucket bucket : buckets) {
logger.info("有 " + bucket.docCount() +
"辆自行车的价格低于 " + bucket.key());
}
获取 “price-histogram” 聚合的结果。
将其转换为直方图变体的结果。这必须与聚合定义保持一致。
桶可以表示为数组或映射。这里将其转换为数组变体(默认选项)。
另一个例子
// Creating aggregations
SearchResponse<Void> search3 = client.search( b-> b
.index("products")
.size(0)
.aggregations("price-histo", a -> a
.histogram(h -> h
.field("price")
.interval(20.0)
)
),
Void.class
);
long firstBucketCount = search3.aggregations()
.get("price-histo")
.histogram()
.buckets().array()
.get(0)
.docCount();
System.out.println("doc count: " + firstBucketCount);
}
上面的 aggregation 相当于如下的请求:
GET products/_search
{
"size": 0,
"aggs": {
"price-histo": {
"histogram": {
"field": "price",
"interval": 20
}
}
}
}
我们的 Java 代码的输出结果为:
doc count: 2
上面的聚合,我们可以甚至直接使用 JSON 结构的字符串来进行操作:
String aggstr = "\n" +
" { \n" +
" \"size\": 0, \n" +
" \"aggs\": { \n" +
" \"price-histo\": { \n" +
" \"histogram\": { \n" +
" \"field\": \"price\", \n" +
" \"interval\": 20 \n" +
" } \n" +
" } \n" +
" } \n" +
" } ";
System.out.println("agg is: " + aggstr );
InputStream agg = new ByteArrayInputStream(aggstr.getBytes());
SearchResponse<Void> searchAgg = client
.search(b -> b
.index("products")
.withJson(agg),
Void.class
);
firstBucketCount = searchAgg.aggregations()
.get("price-histo")
.histogram()
.buckets().array()
.get(0)
.docCount();
System.out.println("doc count: " + firstBucketCount);
上面代码显示的结果和之上的结果是一样的:
分组查询
Elasticsearch Java API Client客户端中的分组查询,也是属于聚合查询的一部分,所以同样使用aggregations方法,并使用terms方法来代表分组查询,field传入需要分组的字段,最后通过响应中的aggregations参数来获取,这里需要根据数据的类型来获取最后的分组结果,我这里因为统计的是数字类型,所以调用lterms()使用LongTermsAggregate来获取结果,同理:如果是String类型则调用sterms()使用StringTermsAggregate,最后打印出docCount属性即可。
SearchResponse<Test> response11 = client.search(s -> s
.index("newapi")
.size(100)
.aggregations("ageGroup", a -> a
.terms(t -> t
.field("age")
)
)
, Test.class);
System.out.println(response11.took());
System.out.println(response11.hits().total().value());
response11.hits().hits().forEach(e -> {
System.out.println(e.source().toString());
});
Aggregate aggregate = response11.aggregations().get("ageGroup");
LongTermsAggregate lterms = aggregate.lterms();
Buckets<LongTermsBucket> buckets = lterms.buckets();
for (LongTermsBucket b : buckets.array()) {
System.out.println(b.key() + " : " + b.docCount());
}
过滤器
SourceConfig 提供对包含和排除字段的访问权限。
SearchResponse<ActivityDocument> search = client.search(s -> s
.query(query)
.source(s1 -> s1
.filter(v -> v
.includes("type", "allProdsFlag", "price", "discount", "marketingType", "marketingCalType", "number", "name", "shopId", "pic", "startTime", "endTime", "skuIds", "activityId")
.excludes(null)
)
)
, ActivityDocument.class);
或者使用of来构建
SourceConfig sourceConfig = SourceConfig.of(s -> s
.filter(v -> v
.includes("type", "allProdsFlag", "price", "discount", "marketingType", "marketingCalType", "number", "name", "shopId", "pic", "startTime", "endTime", "skuIds", "activityId")
.excludes(null)
)
);
SearchResponse<ActivityDocument> search = client.search(s -> s
.query(query)
.source(sourceConfig)
, ActivityDocument.class);
参考文章与推荐阅读
java与es8实战之三:Java API Client有关的知识点串讲
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!