大模型训练数据集汇总
LLM数据集总结
GLUE
简介
当前大多数以上词级别的NLU模型都是针对特定任务设计的,而针对各种任务都能执行的通用模型尚未实现。为了解决这个问题,作者提出了GLUE,希望通过这个评测平台促进通用NLU系统的发展。
任务
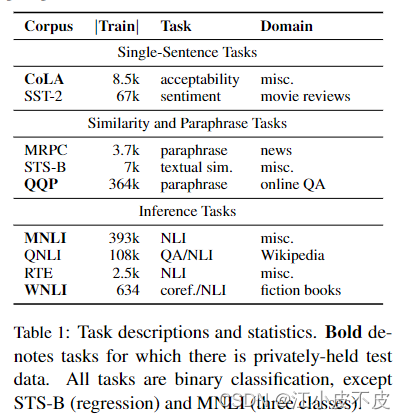
- GLUE基准测试包含9个英语句子理解任务,涵盖广泛的领域和数据规模。这9个任务包括:
- CoLA: 语法可接受性判断,判断一个句子是否符合英语语法
- SST-2: 情感分析,判断电影评论的情感极性
- MRPC: 释义判断,判断两个句子是否在语义上等价
- STS-B: 语义相似度,评价两个句子的语义相似度
- QQP: 释义判断,判断Quora中的问题对是否语义等价
- MNLI: 自然语言推理,判断一个句子是否可以从另一个句子推断出来
- QNLI: 将SQuAD问题回答任务改编为自然语言推理任务
- RTE: 文本蕴含,判断一个文本片段是否可以从另一个文本片段推断出来
- WNLI: 将Winograd Schema Challenge改编为自然语言推理任务
数据集大小
- 任务数据集大小如下:
- CoLA: 8500
- SST-2: 67000
- MRPC: 3700
- STS-B: 7000
- QQP: 364000
- MNLI: 393000
- QNLI: 108000
- RTE: 2500
- WNLI: 634
SQuAD
简介
斯坦福问答数据集(SQuAD),这是一个由众包工作者在维基百科文章上提出的10万多个问题的阅读理解数据集,每个问题的答案都是相应阅读段落的一部分文本。
SQuAD数据集的构建分为三个阶段:1. 筛选文章;2. 通过众包的方式在这些文章上收集问题-答案对;3. 收集额外的答案。首先,作者通过Project Nayuki的内部PageRanks从英语维基百科中获取了前10000篇文章,然后从这些文章中随机抽取了536篇。从这些536篇文章中提取了单独的段落,并去除了图像、图表等。
选择使用维基百科文章作为语料库的原因是,维基百科文章涵盖了广泛的主题,从音乐名人到抽象概念。此外,维基百科内部PageRanks可以帮助获取高质量的文章。通过众包的方式收集问题和答案,可以更快地扩展数据集并增加其多样性。
任务
阅读理解数据集
数据集大小
- 数据集中总共包含:
- 536篇维基百科文章
- 23,215个段落
- 100,000+的问题-答案对
其中80%作为训练集,10%作为开发集,10%作为测试集。
所以数据集大小概览如下:
- 训练集文章数:429篇
- 训练集段落数:18,572
- 训练集问题数:约80,000
- 开发集文章数:53篇
- 开发集段落数:2,321
- 开发集问题数:约10,000
- 测试集文章数:54篇
- 测试集段落数:2,322
- 测试集问题数:约10,000
下载地址
https://data.deepai.org/squad1.1.zip
https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v2.0.json
XSUM
简介
XSum-WebArxiveUrls.txt: XSum 数据集由226,711 篇Wayback 存档的 BBC 文章组成,时间跨度近十年(2010 年至 2017 年),涵盖各个领域(例如新闻、政治、体育、天气、商业、技术、科学、健康、家庭、教育、娱乐和艺术)。
下载地址
https://github.com/EdinburghNLP/XSum/tree/master/XSum-Dataset
持续更新中…
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!