13|代理(下):结构化工具对话、Self-Ask with Search以及Plan and execute代理
13|代理(下):结构化工具对话、Self-Ask with Search以及Plan and execute代理
什么是结构化工具
LangChain 的第一个版本是在 2022 年 11 月推出的,当时的设计是基于 ReAct 论文构建的,主要围绕着代理和工具的使用,并将二者集成到提示模板的框架中。
早期的工具使用十分简单,AgentExecutor 引导模型经过推理调用工具时,仅仅能够生成两部分内容:一是工具的名称,二是输入工具的内容。而且,在每一轮中,代理只被允许使用一个工具,并且输入内容只能是一个简单的字符串。这种简化的设计方式是为了让模型的任务变得更简单,因为进行复杂的操作可能会使得执行过程变得不太稳定。
不过,随着语言模型的发展,尤其是出现了如 gpt-3.5-turbo 和 GPT-4 这样的模型,推理能力逐渐增强,也为代理提供了更高的稳定性和可行性。这就使得 LangChain 开始考虑放宽工具使用的限制。
2023 年初,LangChain 引入了“多操作”代理框架,允许代理计划执行多个操作。在此基础上,LangChain 推出了结构化工具对话代理,允许更复杂、多方面的交互。通过指定 AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION 这个代理类型,代理能够调用包含一系列复杂工具的“结构化工具箱”,组合调用其中的多个工具,完成批次相关的任务集合。
举例来说,结构化工具的示例包括:
- 文件管理工具集:支持所有文件系统操作,如写入、搜索、移动、复制、列目录和查找。
- Web 浏览器工具集:官方的 PlayWright 浏览器工具包,允许代理访问网站、点击、提交表单和查询数据。
下面,我们就以 PlayWright 工具包为例,来实现一个结构化工具对话代理。
先来看一看什么是 PlayWright 工具包。
什么是 Playwright
Playwright 是一个开源的自动化框架,它可以让你模拟真实用户操作网页,帮助开发者和测试者自动化网页交互和测试。用简单的话说,它就像一个“机器人”,可以按照你给的指令去浏览网页、点击按钮、填写表单、读取页面内容等等,就像一个真实的用户在使用浏览器一样。
Playwright 支持多种浏览器,比如 Chrome、Firefox、Safari 等,这意味着你可以用它来测试你的网站或测试应用在不同的浏览器上的表现是否一致。
下面我们先用 pip install playwright 安装 Playwright 工具。
不过,如果只用 pip 安装 Playwright 工具安装包,就使用它,还不行,会得到下面的信息。

因此我们还需要通过 playwright install 命令来安装三种常用的浏览器工具。

现在,一切就绪,我们可以通过 Playwright 浏览器工具来访问一个测试网页。
from playwright.sync_api import sync_playwright
def run():
# 使用Playwright上下文管理器
with sync_playwright() as p:
# 使用Chromium,但你也可以选择firefox或webkit
browser = p.chromium.launch()
# 创建一个新的页面
page = browser.new_page()
# 导航到指定的URL
page.goto('https://langchain.com/')
# 获取并打印页面标题
title = page.title()
print(f"Page title is: {title}")
# 关闭浏览器
browser.close()
if __name__ == "__main__":
run()
这个简单的 Playwright 脚本,它打开了一个新的浏览器实例。过程是:导航到指定的 URL;获取页面标题并打印页面的标题;最后关闭浏览器。
输出如下:
Page title is: LangChain
这个脚本展示了 Playwright 的工作方式,一切都是在命令行里面直接完成。它不需要我们真的去打开 Chome 网页,然后手工去点击菜单栏、拉动进度条等。
下面这个表,我列出了使用命令行进行自动化网页测试的优势。

现在你了解了 Playwright 这个工具包的基本思路,下面我们就开始使用它来作为工具集,来实现结构化工具对话代理。
使用结构化工具对话代理
在这里,我们要使用的 Agent 类型是 STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION。要使用的工具则是 PlayWrightBrowserToolkit,这是 LangChain 中基于 PlayWrightBrowser 包封装的工具箱,它继承自 BaseToolkit 类。
PlayWrightBrowserToolkit 为 PlayWright 浏览器提供了一系列交互的工具,可以在同步或异步模式下操作。
其中具体的工具就包括:
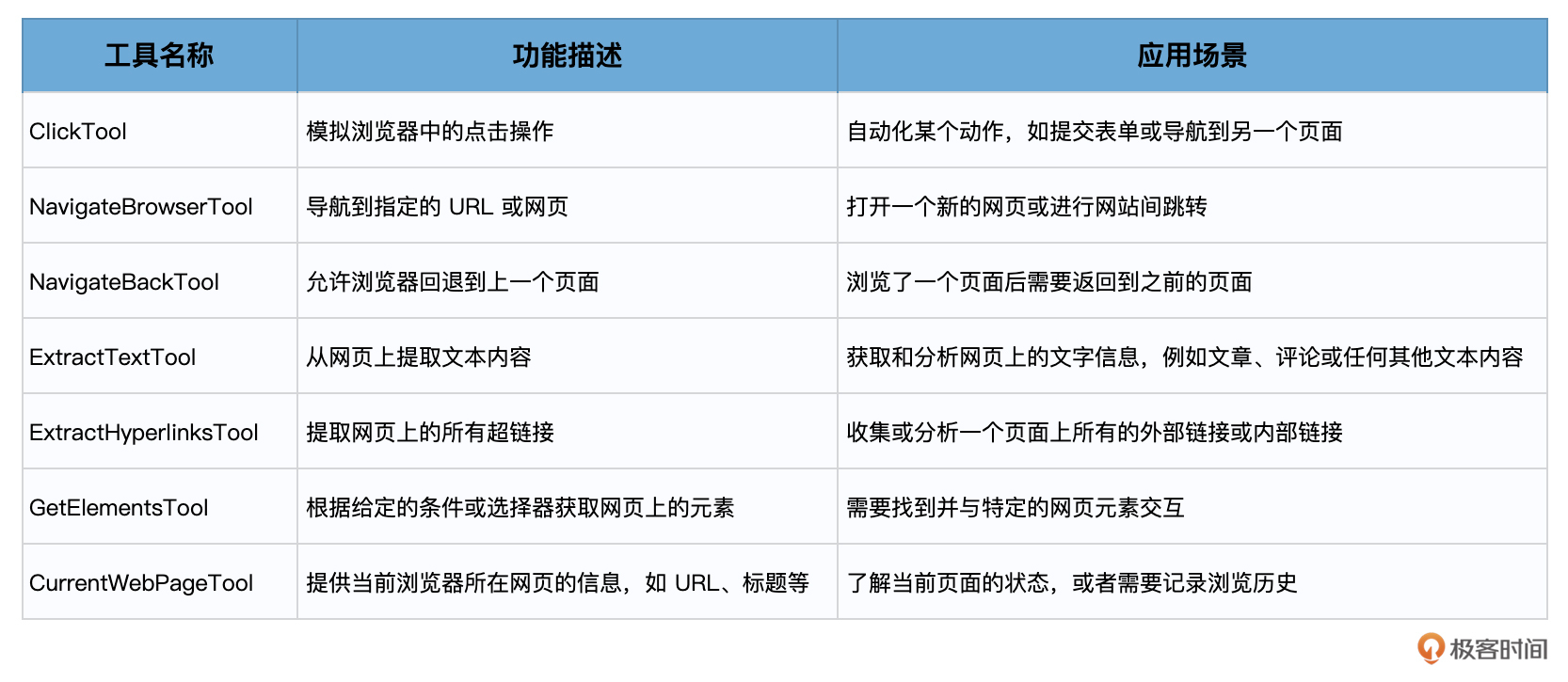
下面,我们就来看看结构化工具对话代理是怎样通过组合调用 PlayWrightBrowserToolkit 中的各种工具,自动完成我们交给它的任务。
from langchain.agents.agent_toolkits import PlayWrightBrowserToolkit
from langchain.tools.playwright.utils import create_async_playwright_browser
async_browser = create_async_playwright_browser()
toolkit = PlayWrightBrowserToolkit.from_browser(async_browser=async_browser)
tools = toolkit.get_tools()
print(tools)
from langchain.agents import initialize_agent, AgentType
from langchain.chat_models import ChatAnthropic, ChatOpenAI
# LLM不稳定,对于这个任务,可能要多跑几次才能得到正确结果
llm = ChatOpenAI(temperature=0.5)
agent_chain = initialize_agent(
tools,
llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
)
async def main():
response = await agent_chain.arun("What are the headers on python.langchain.com?")
print(response)
import asyncio
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
在这个示例中,我们询问大模型,网页 python.langchain.com 中有哪些标题目录?
很明显,大模型不可能包含这个网页的内部信息,因为 ChatGPT 完成训练的那一年(2021 年 9 月),LangChain 还不存在。因此,大模型不可避免地需要通过 PlayWrightBrowser 工具来解决问题。
第一轮思考
代理进入 AgentExecutor Chain 之后的第一轮思考如下:

这里,我对上述思考做一个具体说明。
I can use the “navigate_browser” tool to visit the website and then use the “get_elements” tool to retrieve the headers. Let me do that.
这是第一轮思考,大模型知道自己没有相关信息,决定使用 PlayWrightBrowserToolkit 工具箱中的 navigate_browser 工具。
Action:
{“action”: “navigate_browser”, “action_input”: {“url”: “[https://python.langchain.com](https://python.langchain.com/)”}}
行动:通过 Playwright 浏览器访问这个网站。
Observation: Navigating to https://python.langchain.com returned status code 200
观察:成功得到浏览器访问的返回结果。
在第一轮思考过程中,模型决定使用 PlayWrightBrowserToolkit 中的 navigate_browser 工具。
第二轮思考
下面是大模型的第二轮思考。

还是对上述思考做一个具体说明。
Thought:Now that I have successfully navigated to the website, I can use the “get_elements” tool to retrieve the headers. I will specify the CSS selector for the headers and retrieve their text.
第二轮思考:模型决定使用 PlayWrightBrowserToolkit 工具箱中的另一个工具 get_elements,并且指定 CSS selector 只拿标题的文字。
Action:
{“action”: “get_elements”, “action_input”: {“selector”: “h1, h2, h3, h4, h5, h6”, “attributes”: [“innerText”]}}
行动:用 Playwright 的 get_elements 工具去拿网页中各级标题的文字。
Observation: [{“innerText”: “Introduction”}, {“innerText”: “Get started”}, {“innerText”: “Modules”}, {“innerText”: “Model I/O”}, {“innerText”: “Data connection”}, {“innerText”: “Chains”}, {“innerText”: “Agents”}, {“innerText”: “Memory”}, {“innerText”: “Callbacks”}, {“innerText”: “Examples, ecosystem, and resources”}, {“innerText”: “Use cases”}, {“innerText”: “Guides”}, {“innerText”: “Ecosystem”}, {“innerText”: “Additional resources”}, {“innerText”: “Support”}, {“innerText”: “API reference”}]
观察:成功地拿到了标题文本。
在第二轮思考过程中,模型决定使用 PlayWrightBrowserToolkit 中的 get_elements 工具。
第三轮思考
下面是大模型的第三轮思考。
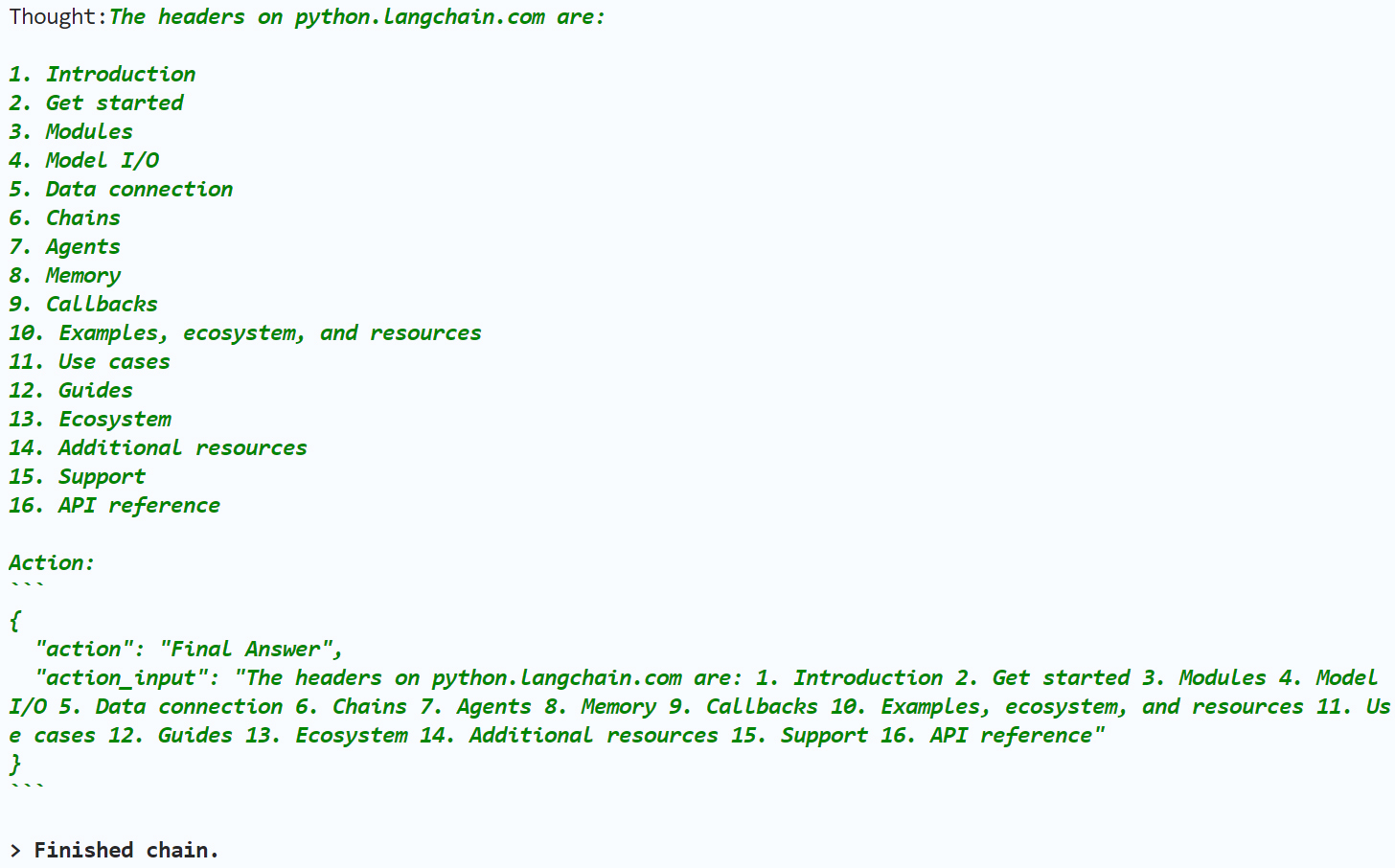
对上述思考做一个具体说明。
Thought:The headers on python.langchain.com are:
- Introduction
- … …
- API reference
第三轮思考:模型已经找到了网页中的所有标题。
Action:
{ "action": "Final Answer", "action_input": "The headers on python.langchain.com are: 1. Introduction 2. Get started 3. Modules 4. Model I/O 5. Data connection 6. Chains 7. Agents 8. Memory 9. Callbacks 10. Examples, ecosystem, and resources 11. Use cases 12. Guides 13. Ecosystem 14. Additional resources 15. Support 16. API reference" }
行动:给出最终答案。
AgentExecutor Chain 结束之后,成功输出 python.langchain.com 这个页面中各级标题的具体内容。

在这个过程中,结构化工具代理组合调用了 Playwright 工具包中的两种不同工具,自主完成了任务。
使用 Self-Ask with Search 代理
讲完了 Structured Tool Chat 代理,我们再来看看 Self-Ask with Search 代理。
Self-Ask with Search 也是 LangChain 中的一个有用的代理类型(SELF_ASK_WITH_SEARCH)。它利用一种叫做 “Follow-up Question(追问)”加“Intermediate Answer(中间答案)”的技巧,来辅助大模型寻找事实性问题的过渡性答案,从而引出最终答案。
这是什么意思?让我通过示例来给你演示一下,你就明白了。在这个示例中,我们使用 SerpAPIWrapper 作为工具,用 OpenAI 作为语言模型,创建 Self-Ask with Search 代理。
from langchain import OpenAI, SerpAPIWrapper
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
llm = OpenAI(temperature=0)
search = SerpAPIWrapper()
tools = [
Tool(
name="Intermediate Answer",
func=search.run,
description="useful for when you need to ask with search",
)
]
self_ask_with_search = initialize_agent(
tools, llm, agent=AgentType.SELF_ASK_WITH_SEARCH, verbose=True
)
self_ask_with_search.run(
"使用玫瑰作为国花的国家的首都是哪里?"
)
该代理对于这个问题的输出如下:

其实,细心的你可能会发现,“使用玫瑰作为国花的国家的首都是哪里?”这个问题不是一个简单的问题,它其实是一个多跳问题——在问题和最终答案之间,存在中间过程。
多跳问题(Multi-hop question)是指为了得到最终答案,需要进行多步推理或多次查询。这种问题不能直接通过单一的查询或信息源得到答案,而是需要跨越多个信息点,或者从多个数据来源进行组合和整合。
也就是说,问题的答案依赖于另一个子问题的答案,这个子问题的答案可能又依赖于另一个问题的答案。这就像是一连串的问题跳跃,对于人类来说,解答这类问题可能需要从不同的信息源中寻找一系列中间答案,然后结合这些中间答案得出最终结论。
“使用玫瑰作为国花的国家的首都是哪里?”这个问题并不直接询问哪个国家使用玫瑰作为国花,也不是直接询问英国的首都是什么。而是先要推知使用玫瑰作为国花的国家(英国)之后,进一步询问这个国家的首都。这就需要多跳查询。
为什么 Self-Ask with Search 代理适合解决多跳问题呢?有下面几个原因。
- 工具集合:代理包含解决问题所必须的搜索工具,可以用来查询和验证多个信息点。这里我们在程序中为代理武装了 SerpAPIWrapper 工具。
- 逐步逼近:代理可以根据第一个问题的答案,提出进一步的问题,直到得到最终答案。这种逐步逼近的方式可以确保答案的准确性。
- 自我提问与搜索:代理可以自己提问并搜索答案。例如,首先确定哪个国家使用玫瑰作为国花,然后确定该国家的首都是什么。
- 决策链:代理通过一个决策链来执行任务,使其可以跟踪和处理复杂的多跳问题,这对于解决需要多步推理的问题尤为重要。
在上面的例子中,通过大模型的两次 follow-up 追问,搜索工具给出了两个中间答案,最后给出了问题的最终答案——伦敦。
使用 Plan and execute 代理
在这节课的最后,我再给你介绍一种比较新的代理类型:Plan and execute 代理。
计划和执行代理通过首先计划要做什么,然后执行子任务来实现目标。这个想法是受到 Plan-and-Solve 论文的启发。论文中提出了计划与解决(Plan-and-Solve)提示。它由两部分组成:首先,制定一个计划,并将整个任务划分为更小的子任务;然后按照该计划执行子任务。
这种代理的独特之处在于,它的计划和执行不再是由同一个代理所完成,而是:
- 计划由一个大语言模型代理(负责推理)完成。
- 执行由另一个大语言模型代理(负责调用工具)完成。
因为这个代理比较新,它隶属于 LangChain 的实验包 langchain_experimental,所以你需要先安装 langchain_experimental 这个包。
pip install -U langchain langchain_experimental
下面我们来使用一下这个代理。在这里,我们创建了 Plan and execute 代理,这个代理和之前看到的代理不同,它有一个 Planner,有一个 Executor,它们可以是不同的模型。
当然,在这个示例中,我们都使用了 ChatOpenAI 模型。
from langchain.chat_models import ChatOpenAI
from langchain_experimental.plan_and_execute import PlanAndExecute, load_agent_executor, load_chat_planner
from langchain.llms import OpenAI
from langchain import SerpAPIWrapper
from langchain.agents.tools import Tool
from langchain import LLMMathChain
search = SerpAPIWrapper()
llm = OpenAI(temperature=0)
llm_math_chain = LLMMathChain.from_llm(llm=llm, verbose=True)
tools = [
Tool(
name = "Search",
func=search.run,
description="useful for when you need to answer questions about current events"
),
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math"
),
]
model = ChatOpenAI(temperature=0)
planner = load_chat_planner(model)
executor = load_agent_executor(model, tools, verbose=True)
agent = PlanAndExecute(planner=planner, executor=executor, verbose=True)
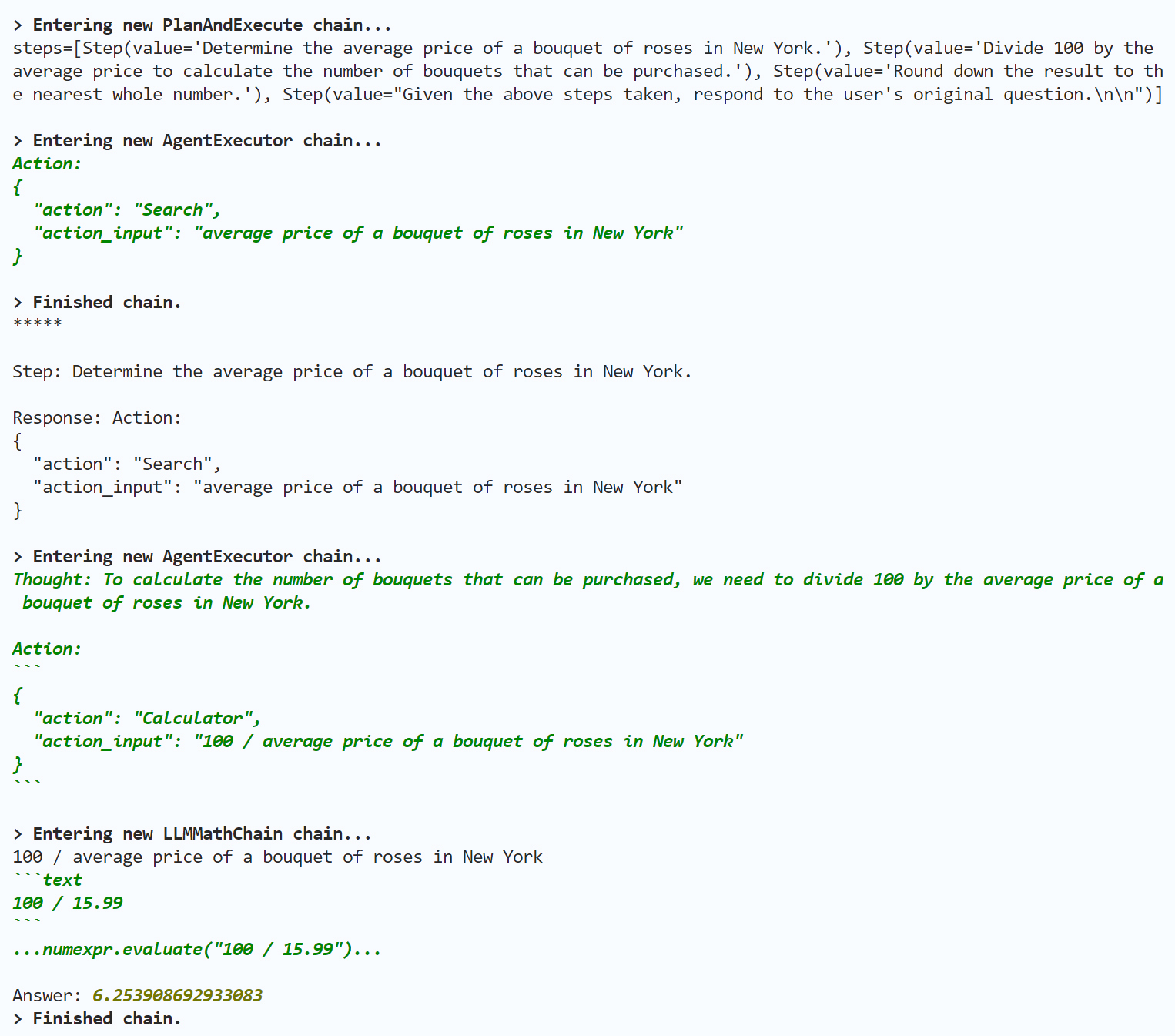
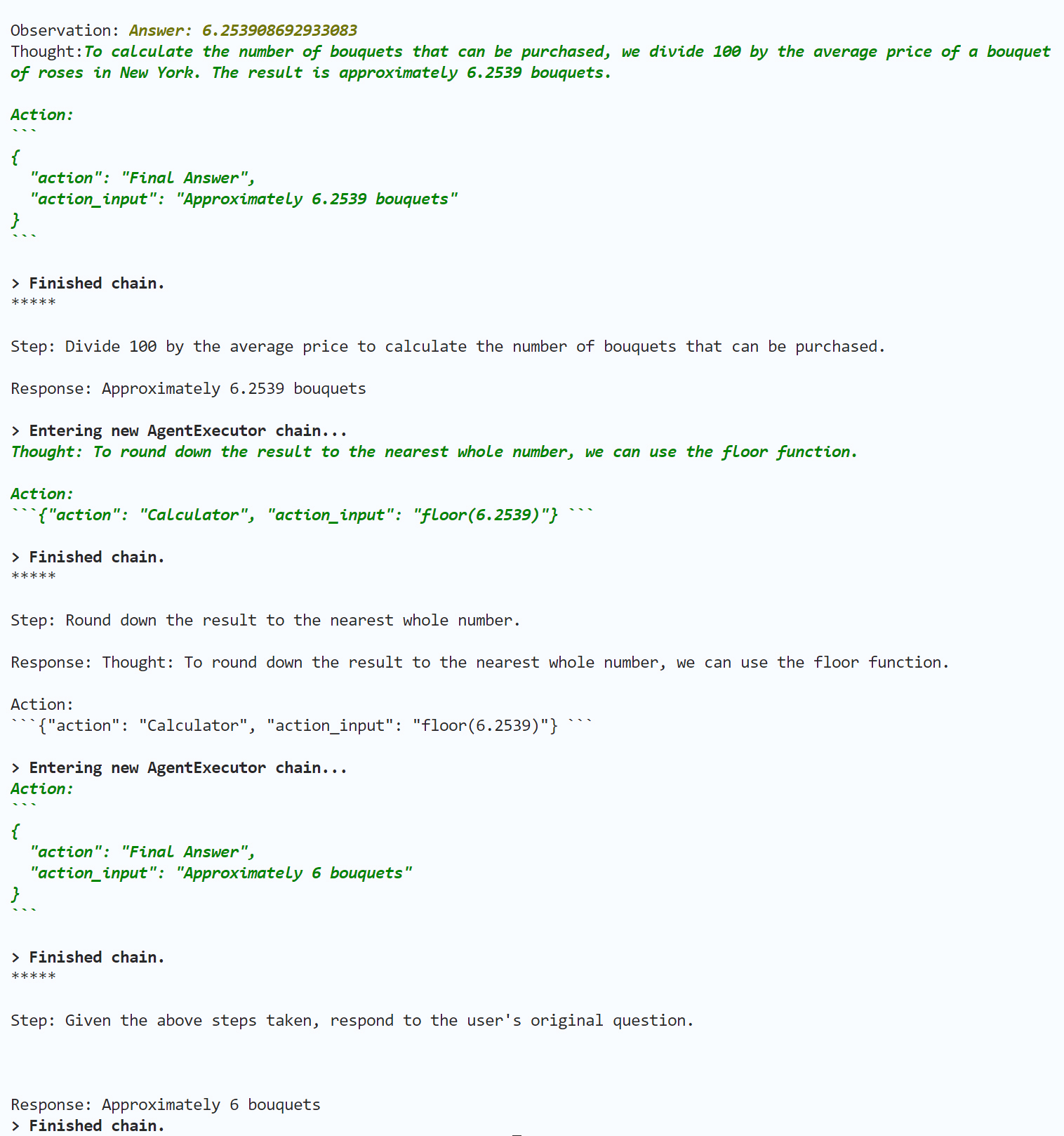
agent.run("在纽约,100美元能买几束玫瑰?")
输出如下:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!