scrapy批量爬取豆瓣电影排行信息
2023-12-18 23:00:29
scrapy批量爬取豆瓣电影排行信息
使用scrapy框架批量爬取豆瓣电影排行信息,首先看到豆瓣电影链接为
https://movie.douban.com/top250
经过分析,一共10页,第二页,第二页,…,第10页的规律是:
分页规律 第N页
https://movie.douban.com/top250?start=25*(N-1)
分析完毕后,下一步开始创建项目
1.创建项目
# 创建一个名为 douban_mv 的 Scrapy 项目
# 在控制台输入命令如下
scrapy startproject douban_mv

然后进入到spiders目录下
cd douban_mv/douban_mv/spiders
在控制台输入命令
scrapy genspider douban https://movie.douban.com/top250

在进行爬取豆瓣电影排行信息之前需要主要两点
- scrapy是遵守robots协议的,如果robots协议禁止爬取的内容,scrapy会默认不去爬取,所以可以把ROBOTSTXT_OBEY=True改为ROBOTSTXT_OBEY=False或者直接注释,这样就无需遵守robots协议,Scrapy就可以不受限制运行。
在settings.py中设置
# Obey robots.txt rules
#ROBOTSTXT_OBEY = True
- 在settings.py中设置USER_AGENT
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
2.编写items
items主要是定义实体类,实体类中定义我们需要的信息
class DoubanMvItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() # 电影名称
ratingNum = scrapy.Field() # 电影评分
commentCount = scrapy.Field() # 评价人数
3.douban.py
在douban.py中进行编写主要的逻辑
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["movie.douban.com"]
start_urls = ["https://movie.douban.com/top250"]
base_url = 'https://movie.douban.com/top250'
page = 1
def parse(self, response):
print("--------------------")
# name = //div[@class="article"]//li//div[@class="hd"]//a/span[1]/text()
# ratingNum = //div[@class="article"]//li//div[@class="bd"]/div[@class="star"]/span[2]/text()
#commentNum = //div[@class="article"]//li//div[@class="bd"]/div[@class="star"]/span[4]/text()
li_list = response.xpath('//div[@class="article"]//li')
for li in li_list:
title = li.xpath('.//div[@class="hd"]//a/span[1]/text()').extract_first()
ratingNum = li.xpath('.//div[@class="bd"]/div[@class="star"]/span[2]/text()').extract_first()
commentCount = li.xpath('.//div[@class="bd"]/div[@class="star"]/span[4]/text()').extract_first()
mv = DoubanMvItem(title=title, ratingNum=ratingNum, commentCount=commentCount)
# 获取一个mv 交给pipeline管道
yield mv
if self.page<=2:
self.page = self.page +1
url = self.base_url+'?start='+str(self.page*25)
# scrapy.Request就是scrapy就是get请求
# url就是请求地址 callback就是回调,也就是要执行的函数 再次调用parse函数
yield scrapy.Request(url=url,callback=self.parse)
4.pipelines.py
在使用前需要在settings.py中,打开管道爬取
ITEM_PIPELINES = {
"douban_mv.pipelines.DoubanMvPipeline": 300,
}
编写管道文件,将爬取下来的数据下载到表格中
class DoubanMvPipeline:
# item就是yield后面的mv对象
df = pd.DataFrame()
def open_spider(self, spider):
print('-----open-----')
def process_item(self, item, spider):
# 返回 item 对象,交给下一个管道处理
series = pd.Series(item)
self.df = self.df.append(series,ignore_index=True)
return item
def close_spider(self, spider):
print('-----close-----')
self.df.to_excel("mv_top250.xlsx")
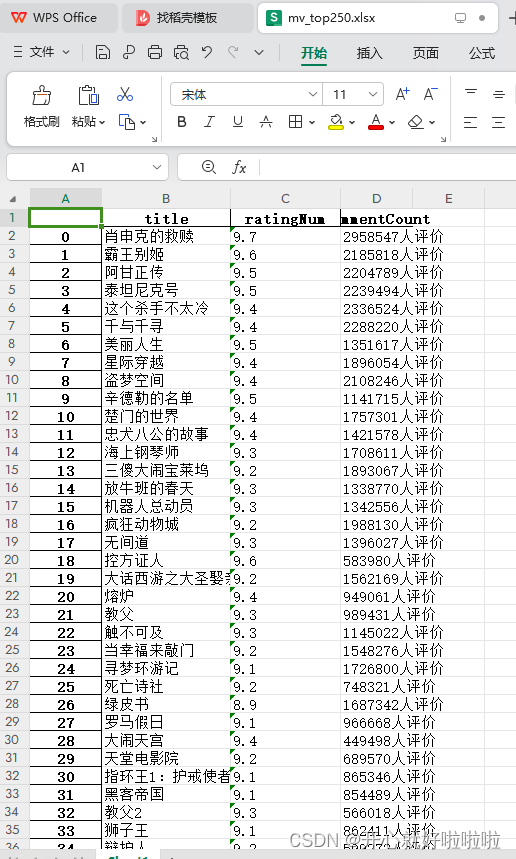
5.爬取得到的文件
爬取得到的文件如下
文章来源:https://blog.csdn.net/qq_44373419/article/details/135068427
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!