Faster RCNN 源码解析
2023-12-14 17:52:38
源码
在Pytorch官网找到源码
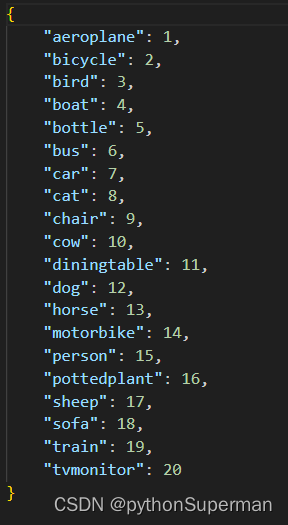
pascal_voc_classes.json:
pascal_voc标签文件。?一个类别对应一个整形数字。在目标检测中“0”是专门留给背景的。
制作自己的voc数据集
加载模型?
# create model num_classes equal background + 20 classes
model = create_model(num_classes=21)transform
import random
from torchvision.transforms import functional as F
class Compose(object):
"""组合多个transform函数"""
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, image, target):
for t in self.transforms:
image, target = t(image, target)
return image, target
class ToTensor(object):
"""将PIL图像转为Tensor"""
def __call__(self, image, target):
image = F.to_tensor(image)
return image, target
class RandomHorizontalFlip(object):
"""随机水平翻转图像以及bboxes"""
def __init__(self, prob=0.5):
self.prob = prob
def __call__(self, image, target):
if random.random() < self.prob:
height, width = image.shape[-2:]
image = image.flip(-1) # 水平翻转图片
bbox = target["boxes"]
# bbox: xmin, ymin, xmax, ymax
bbox[:, [0, 2]] = width - bbox[:, [2, 0]] # 翻转对应bbox坐标信息
target["boxes"] = bbox
return image, target
mask_rcnn的transform
import random
from torchvision.transforms import functional as F
class Compose(object):
"""组合多个transform函数"""
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, image, target):
for t in self.transforms:
image, target = t(image, target)
return image, target
class ToTensor(object):
"""将PIL图像转为Tensor"""
def __call__(self, image, target):
image = F.to_tensor(image)
return image, target
class RandomHorizontalFlip(object):
"""随机水平翻转图像以及bboxes"""
def __init__(self, prob=0.5):
self.prob = prob
def __call__(self, image, target):
if random.random() < self.prob:
height, width = image.shape[-2:]
image = image.flip(-1) # 水平翻转图片
bbox = target["boxes"]
# bbox: xmin, ymin, xmax, ymax
bbox[:, [0, 2]] = width - bbox[:, [2, 0]] # 翻转对应bbox坐标信息
target["boxes"] = bbox
if "masks" in target:
target["masks"] = target["masks"].flip(-1)
return image, target比较
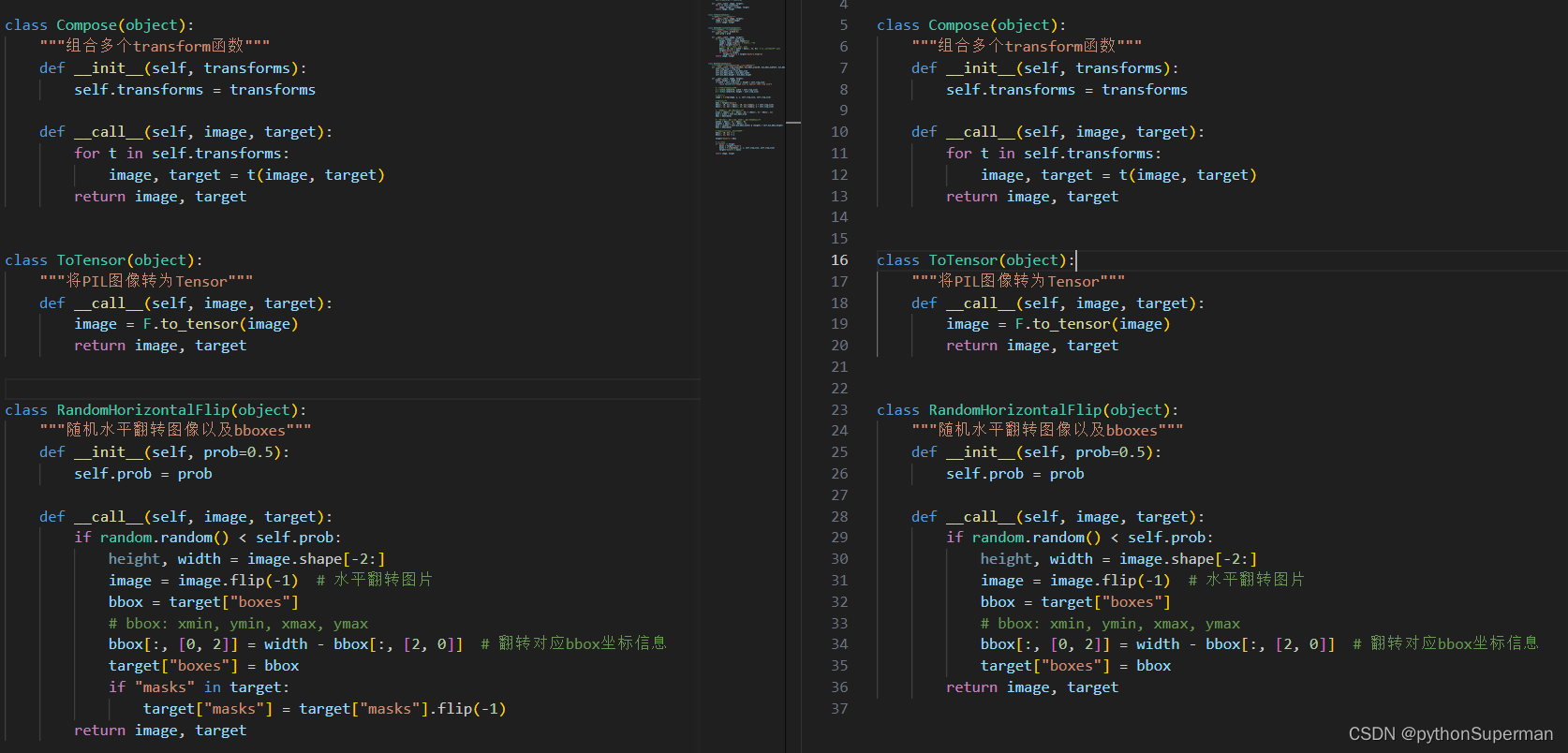
相比之下,mask_rcnn就在随机水平翻转的函数里多了这几行代码
if "masks" in target:
target["masks"] = target["masks"].flip(-1)?predict.py
注意自己的backbone是mobileNetv2还是resNet50+fpn,然后再选择模型创建的代码
def create_model(num_classes):
# mobileNetv2+faster_RCNN
backbone = MobileNetV2().features
backbone.out_channels = 1280
anchor_generator = AnchorsGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'],
output_size=[7, 7],
sampling_ratio=2)
model = FasterRCNN(backbone=backbone,
num_classes=num_classes,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
# resNet50+fpn+faster_RCNN
# 注意,这里的norm_layer要和训练脚本中保持一致
# backbone = resnet50_fpn_backbone(norm_layer=torch.nn.BatchNorm2d)
# model = FasterRCNN(backbone=backbone, num_classes=num_classes, rpn_score_thresh=0.5)
return model
验证并显示待输入的图片
# read class_indict
label_json_path = './pascal_voc_classes.json'
assert os.path.exists(label_json_path), "json file {} dose not exist.".format(label_json_path)
with open(label_json_path, 'r') as f:
class_dict = json.load(f)
category_index = {str(v): str(k) for k, v in class_dict.items()}
# load image
original_img = Image.open("./test.jpg")
# from pil image to tensor, do not normalize image
data_transform = transforms.Compose([transforms.ToTensor()])
img = data_transform(original_img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
model.eval() # 进入验证模式
with torch.no_grad():
# init
img_height, img_width = img.shape[-2:]
init_img = torch.zeros((1, 3, img_height, img_width), device=device)
model(init_img)
t_start = time_synchronized()
predictions = model(img.to(device))[0]
t_end = time_synchronized()
print("inference+NMS time: {}".format(t_end - t_start))
predict_boxes = predictions["boxes"].to("cpu").numpy()
predict_classes = predictions["labels"].to("cpu").numpy()
predict_scores = predictions["scores"].to("cpu").numpy()
if len(predict_boxes) == 0:
print("没有检测到任何目标!")
plot_img = draw_objs(original_img,
predict_boxes,
predict_classes,
predict_scores,
category_index=category_index,
box_thresh=0.5,
line_thickness=3,
font='arial.ttf',
font_size=20)
plt.imshow(plot_img)
plt.show()
# 保存预测的图片结果
plot_img.save("test_result.jpg")
文章来源:https://blog.csdn.net/llf000000/article/details/134908163
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!