算法通关村第十四关—堆能高效解决的经典问题(白银)
???????堆能高效解决的经典问题
一、在数组中找第K大的元素
?LeetCode215 给定整数数组ums和整数k,请返回数组中第k个最大的元素。请注意,你需要找的是数组排序后的第k个最大的元素,而不是第k个不同的元素。
示例1:
输入:[3,2,1,5,6,4]和k=2
输出:5
示例2:
输入:[3,2,3,1,2,4,5,5,6]和K=4
输出:4
?这个题比较好的方法是堆排序法和快速排序法。快速排序在第十关白银挑战已经分析过,这里先看堆排序如何解决问题。
?这个题其实用大堆小堆都可以解决的,但是推荐“找最大用小堆,找最小用大堆,找中间用两个堆”,这样更容易理解,适用范围也更广。构造一个大小只有4的小根堆,为了更好说明情况,我们扩展一下序列[3,2,3,1,2,4,5,1,5,6,2,3]。
?堆满了之后,对于小根堆,并一定所有新来的元素都可以入堆的,只有大于根元素的才可以插入到堆中,否则就直接抛弃。这是一个很重要的前提。另外元素进入的时候,先替换根元素,如果发现左右两个子树都小该怎么办呢?很显然应该与更小的那个比较,这样才能保证根元素一定是当前堆最小的。假如两个子孩子的值一样呢?那就随便选一个。
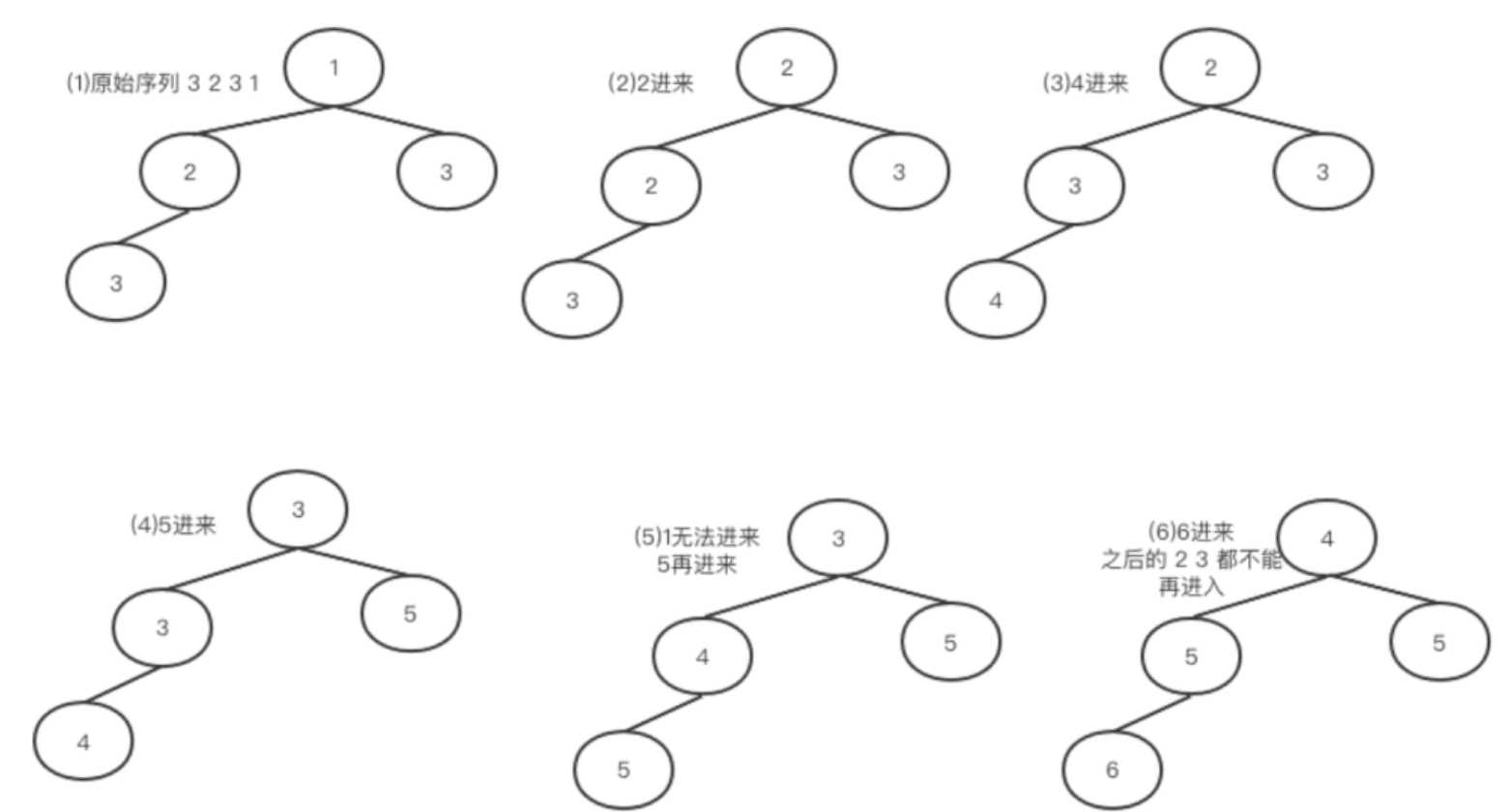
?新元素插入的时候只是替换根元素,然后重新构造成小堆,完成之后,你会神奇的发现此时根的根元素正好是第4大的元素。
?这时候你会发现,不管要处理的序列有多大,或者是不是固定的,根元素每次都恰好是当前序列下的第K大元素。
?堆的代码自己实现是非常困难的,我们可以使用jdk的优先队列来解决,其思路是很简单的。由于找第K大元素,其实就是整个数组排序以后后半部分最小的那个元素。因此,我们可以维护一个有K个元素的最小堆:
1.如果当前堆不满,直接添加;
2.堆满的时候,如果新读到的数小于等于堆顶,肯定不是我们要找的元素,只有新遍历到的数大于堆顶的时候,才将堆顶拿出,然后放入新读到的数,进而让堆自己去调整内部结构。
?说明:这里最合适的操作其实是replace(),即直接把新读进来的元素放在堆顶,然后执行下沉(siftDown()操作。Java当中的PriorityQueue没有提供这个操作,只好先polI()/add()再offer()/remove()。
class Solution {
public int findKthLargest(int[] nums, int k){
PriorityQueue<Integer> queue = new PriorityQueue();
for(int i = 0; i < k; i++){
queue.add(nums[i]);
}
for(int j = k; j < nums.length; j++){
if(nums[j] > queue.peek()){
queue.remove();
queue.add(nums[j]);
}
}
return queue.remove();
}
}
二、堆排序原理
查找:找小用大,找大用小
排序:升序用小,降序用大。
?前面介绍了如何用堆来进行特殊情况的查找,堆的另一个很重要的作用是可以进行排序,那怎么排的呢?
?其实非常简单,我们知道在大顶堆中,根节点是整个结构最大的元素,先将其拿走,剩下的重排,此时根节点就是第二大的元素,我再将其拿走,再排,依次类推。最后堆只剩一个元素的时候,是不是拿走的数据也就排好序了?
?具体来说,建堆结束之后,数组中的数据已经是按照大顶堆的特性来组织的。数组中的第一个元素就是堆顶,也就是最大的元素。我们把它跟最后一个元素交换,那最大元素就放到了下标为的位置。
?这个过程有点类似上面讲的“删除堆顶元素”的操作,当堆顶元素移除之后,我们把下标为的元素放到堆顶,然后再通过堆化的方法,将剩下的一1个元素重新构建成堆。堆化完成之后,我们再取堆顶的元素,放到下标是一1的位置,一直重复这个过程,直到最后堆中只剩下标为1的一个元素,排序工作就完成了。
?当然在上面的过程中,放到最后一个位置的元素就不参与排序和计算了。
?看一个例子,我们对上面第一章的序列[12 23 54 2 65 45 92 47 204 31]进行排序,首先构建一个大顶堆,然后每次我们都让根元素出堆,剩下的继续调整为大顶堆:
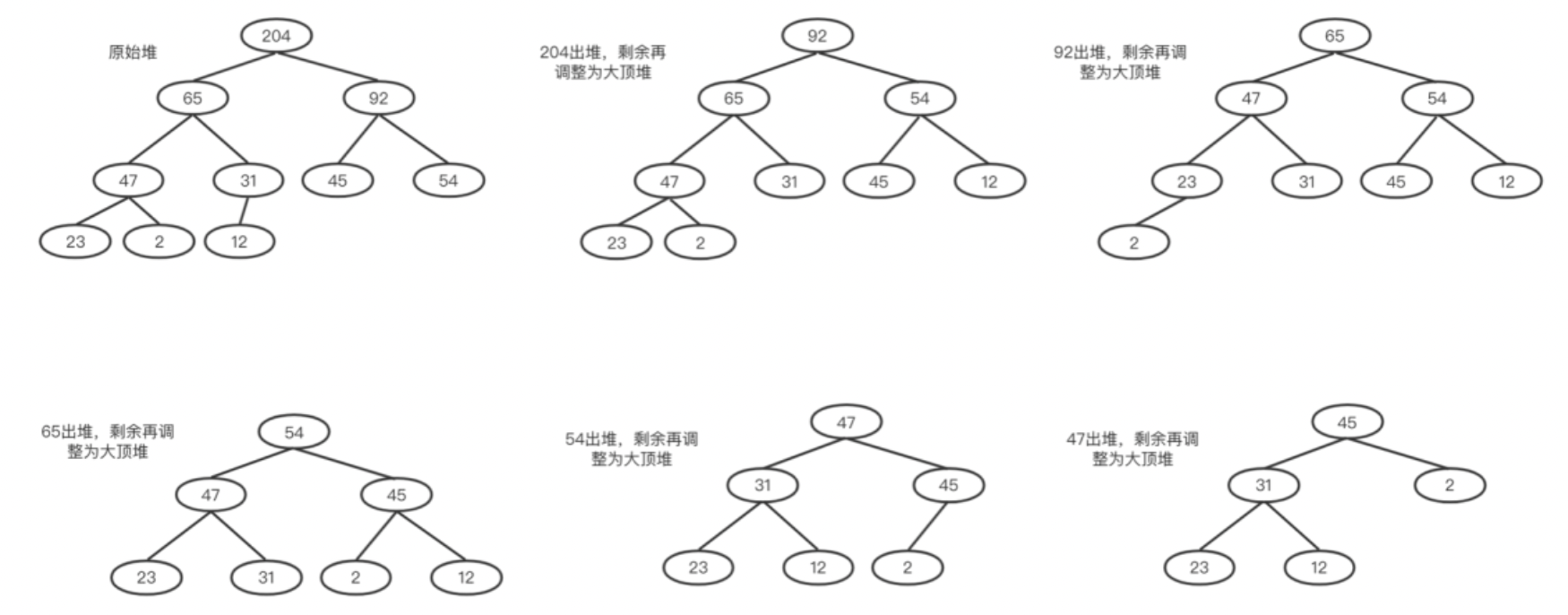
?这时候你会发现出堆的序列刚好是:204、92、65、54、47、45…。也就是刚好是从大到小的顺序排列的。
?所以我们可以明白,如果是一个小顶堆,那自然是升序的。所以在排序的时候:
排序:升序用小,降序用大。
这个与前面的查找是相反的。
明白了这几个堆的特征,再做相关题目就毫无压力了。
三、合并K个排序链表
?Leetcode23. 给你一个链表数组,每个链表都已经按升序排列。请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例1:
输入:1ists=[[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
给了数组,就建立多大的固定堆
给了几个数组,就建立多大的堆,固定大小的
?这个问题五六种方法,我们现在就来看堆排序如何解决。因为每个队列都是从小到大排序的,我们每次都要找最小的元素,所以我们要用小根堆,构建方法和操作与大顶堆完全一样,不同的是每次比较谁更小。使用堆合并的策略是不管几个链表,最终都是按照顺序来的。每次都将剩余节点的最小值加到输出链表尾部,然后进行堆调整,最后堆空的时候,合并也就完成了。
?还有一个问题,这个堆应该定义为多大呢?给了几个链表,堆就定义多大。
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
PriorityQueue<ListNode> queue = new PriorityQueue<>((node1, node2) -> node1.val - node2.val);
//一开始保存每个链表的头结点
for(int i = 0; i < lists.length; i++){
if(lists[i] != null)
queue.add(lists[i]);
}
ListNode dummy = new ListNode(-1);
ListNode cur = dummy;
while(queue.size() > 0){
cur.next = queue.remove();
cur = cur.next;
if(cur.next != null){
queue.add(cur.next);
}
}
return dummy.next;
}
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!