【OpenVINO】使用OpenVINO实现 RT-DETR 模型 INT8量化推理加速
使用OpenVINO实现 RT-DETR 模型 INT8量化推理加速
? RT-DETR是在DETR模型基础上进行改进的,一种基于 DETR 架构的实时端到端检测器,它通过使用一系列新的技术和算法,实现了更高效的训练和推理,在前文我们发表了 《基于 OpenVINO? Python API 部署 RT-DETR 模型 | 开发者实战》、 《基于 OpenVINO? C++ API 部署 RT-DETR 模型 | 开发者实战》以及 《基于 OpenVINO? C# API 部署 RT-DETR 模型 | 开发者实战》,实现了基于OpenVINO? Python 、 C++ API 和C# 凭他向大家展示了的RT-DETR模型的部署流程,并分别展示了是否包含后处理的模型部署流程,为大家使用RT-DETR模型提供了很好的范例。
? 但是经过时间检测,使用OpenVINO? 在CPU平台上运行RT-DETR模型,其推理速度最快可以达到3~4帧左右,但这对于视频数据预测是远远不够的。由于 OpenVINO? 最新发行版2023.1.0在GPU平台对RT-DETR模型算子还不支持,所以在前面文章中我们没有在iGPU平台上进行测试。为了提高推理速度,在本文章中,我们将使用 OpenVINO 实现 RT-DETR 模型 INT8量化,通过模型优化技术实现模型推理加速;并且在 OpenVINO工程师指导下,通过修改OpenVINO 源码,重现编译了官方库,实现了GPU对RT-DETR 模型的支持。
? 项目所使用的全部代码已经在GitHub上开源,并且收藏在OpenVINO-CSharp-API项目里,项目所在目录链接为:
https://github.com/guojin-yan/OpenVINO-CSharp-API/tree/csharp3.0/tutorial_examples
? 也可以直接访问该项目,项目链接为:
https://github.com/guojin-yan/RT-DETR-OpenVINO.git
? 文章首发链接为:使用 OpenVINO? 实现 RT-DETR 模型 INT8 量化推理加速 | 开发者实战
1. 使用 OpenVINO 实现 RT-DETR 模型 INT8量化
? 训练后模型优化是使用无需重新训练或微调的特殊方法,即可将模型转换为对硬件更友好的表示形式。目前最流行和使用最广泛使用的方法是INT8量化,具有以下优点:
- 它易于使用。
- 它不会对准确性造成太大影响。
- 它提供了显著的性能改进。
- 它适合许多库存硬件,因为它们中的大多数都原生支持 8 位计算。
? INT 8量化将模型权重和激活函数的精度降低到 8 位,从而将模型占用空间减少近 4 倍,降低推理所需的吞吐量,并显著提高推理速度,量化过程在实际推理之前离线完成。通过OpenVINO实现模型的量化过程不需要源深度学习框架中的训练数据集或训练代码。
为了让大家更好的复现RT-DETR 模型 INT8量化流程,我们提供了完整的 Notebook文件,使用者可以根据文件操作流程进行一步步操作。使用 OpenVINO 实现 RT-DETR 模型 INT8量化的完整代码已经上传到GitHub中,文章链接为:
https://github.com/guojin-yan/RT-DETR-OpenVINO/blob/master/optimize/openvino-convert-and-optimize-rt-detr.ipynb
? 为了方便大家复现该项目,此处录制了演示视频,已经发布到B站,视频链接为:
https://www.bilibili.com/video/BV11N411T7m5/
使用 OpenVINO 实现 RT-DETR 模型 INT8量化推理加速
1.1 神经网络压缩框架 (NNCF)
? 神经网络压缩框架 (NNCF) 提供了 Python 中提供的训练后量化 API,旨在重用代码进行模型训练或验证,这些代码通常可用于源框架中的模型,例如 PyTorch 或 TensroFlow。NNCF API 是跨框架的,目前支持以下框架中的模型:OpenVINO、PyTorch、TensorFlow 2.x 和 ONNX。目前,OpenVINO中间表示中模型的训练后量化在支持的方法和模型覆盖率方面是最成熟的。

? NNCF API 有两个方式来实现训练后INT 8量化:
- 基本量化:基本量化流程是将INT 8 量化应用于模型的最简单方法,它适用于OpenVINO、PyTorch、TensorFlow 2.x 和 ONNX框架中的模型。在这种情况下,只需要具有代表性的校准数据集进行。
- 具有精度控制的量化:这是高级量化流程,允许将INT 8 量化应用于模型,并通过验证函数控制精度指标。目前只支持OpenVINO框架中的模型。除了校准数据集之外,还需要验证数据集来计算准确性指标。
1.2 准备校准数据集
? 在本实验中,我们只实现基本量化,因此只需要准备校验数据集即可。RT-DETR模型预训练模型是在COCO数据集下训练的,因此我们只需要准备COCO验证数据集即可。为了更容易构建验证数据集,我们此处使用ultralytics框架下的API方法实现。
1.2.1 下载COCO验证数据集
? COCO验证数据集可以通过官网直接下载,也可以通过下面的代码下载:
DATA_URL = "http://images.cocodataset.org/zips/val2017.zip"
LABELS_URL = "https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017labels-segments.zip"
CFG_URL = "https://raw.githubusercontent.com/ultralytics/ultralytics/8ebe94d1e928687feaa1fee6d5668987df5e43be/ultralytics/datasets/coco.yaml"
CACHE_URL = "https://github.com/guojin-yan/RT-DETR-OpenVINO/releases/download/Model2.0/val2017.cache"
OUT_DIR = Path('./datasets')
DATA_PATH = OUT_DIR / "val2017.zip"
LABELS_PATH = OUT_DIR / "coco2017labels-segments.zip"
CFG_PATH = OUT_DIR / "coco.yaml"
CACHE_PATH = OUT_DIR / "coco/labels/val2017.cache"
download_file(DATA_URL, DATA_PATH.name, DATA_PATH.parent)
download_file(LABELS_URL, LABELS_PATH.name, LABELS_PATH.parent)
download_file(CFG_URL, CFG_PATH.name, CFG_PATH.parent)
if not (OUT_DIR / "coco/labels").exists():
with ZipFile(LABELS_PATH , "r") as zip_ref:
zip_ref.extractall(OUT_DIR)
with ZipFile(DATA_PATH , "r") as zip_ref:
zip_ref.extractall(OUT_DIR / 'coco/images')
download_file(CACHE_URL, CACHE_PATH.name, CACHE_PATH.parent)
1.2.2 Validator包装器
? Yolov8模型存储库使用Validator包装器,它表示准确性验证管道。它创建数据加载器和评估度量,并更新数据加载器生成的每个数据批次的度量。除此之外,它还负责数据的预处理和结果的后处理。RT-DETR模型训练集也使用了COCO数据集。为了方便起见,我们使用Yolov8环境来配置此处的数据。
? 对于类初始化,应该提供配置。我们将使用默认设置,但可以用一些参数替代它来测试自定义数据。Yolov8模型模型已经连接了ValidatorClass方法,因此我们通过该模型进行创建验证器类实例。
args = get_cfg(cfg=DEFAULT_CFG)
args.data = str(CFG_PATH)
YOLO_MODEL = "yolov8n"
models_dir = Path('./models')
yolo_model = YOLO(models_dir / f'{YOLO_MODEL}.pt')
det_validator = yolo_model.ValidatorClass(args=args)
det_validator.data = check_det_dataset(args.data)
det_data_loader = det_validator.get_dataloader("./datasets/coco", 1)
det_validator.is_coco = True
det_validator.class_map = ops.coco80_to_coco91_class()
det_validator.names = yolo_model.model.names
det_validator.metrics.names = det_validator.names
det_validator.nc = yolo_model.model.model[-1].nc
1.2.3 转换用于量化的数据集
? 上一步中我们使用Validator包装器创建了验证数据集,但如果能在量化中使用,还需要进行转换,此处OpenVINO提供了API接口nncf.Dataset(),通过该接口读取Validator包装器中的验证数据。··
def transform_fn(data_item:Dict):
input_tensor = det_validator.preprocess(data_item)['img'].numpy()
return input_tensor
quantization_dataset = nncf.Dataset(det_data_loader, transform_fn)
1.3 定义模型精度校验方法
? 为了观测模型量化前后模型预测精度变化,此处自定义了模型精度测试方法:
def sigmoid(z):
return 1/(1+np.exp(-z))
def rtdetr_result(preds_box,preds_score):
results=[]
n=0
for i in range(300):
scores=preds_score[0,i,:]
score=sigmoid(np.max(np.array(scores)))
if(score<0.0001):
continue
result=[]
cx=preds_box[0,i,0]*640.0
cy=preds_box[0,i,1]*640.0
w=preds_box[0,i,2]*640.0
h=preds_box[0,i,3]*640.0
result.append(cx-0.5*w)
result.append(cy-0.5*h)
result.append(cx+0.5*w)
result.append(cy+0.5*h)
result.append(score)
result.append(np.argmax(scores))
results.append(result)
n+=1
return [torch.tensor(results)]
def test(model:ov.Model, core:ov.Core, data_loader:torch.utils.data.DataLoader, validator, num_samples:int = None):
validator.seen = 0
validator.jdict = []
validator.stats = []
validator.batch_i = 1
validator.confusion_matrix = ConfusionMatrix(nc=validator.nc)
compiled_model = core.compile_model(model)
for batch_i, batch in enumerate(tqdm(data_loader, total=num_samples)):
if num_samples is not None and batch_i == num_samples:
break
batch = validator.preprocess(batch)
results = compiled_model(batch["img"])
preds_box = torch.from_numpy(results[compiled_model.output(0)])
preds_score = torch.from_numpy(results[compiled_model.output(1)])
preds=rtdetr_result(preds_box,preds_score)
validator.update_metrics(preds, batch)
stats = validator.get_stats()
return stats
1.4 模型量化
1.4.1 模型量化实现
? 首先我们定义量化接口,nncf.quantize函数为模型量化提供了一个接口,主要输入参数为:OpenVINO模型和量化数据集,实现如下所示:
quantized_det_model = nncf.quantize(
det_ov_model,
quantization_dataset,
preset=nncf.QuantizationPreset.MIXED
)
通过上述方法,便可以实现RT-DETR模型的量化,
1.4.2 量化前后精度测试
? 在前文中我们定义了模型精度测试方法,因此我们在此处进行量化前后的精度检测,通过该方法,在1000张测试集上进行检测,最后打印模型预测精度:
fp_det_stats = test(det_ov_model, core, det_data_loader, det_validator, num_samples=NUM_TEST_SAMPLES)
int8_det_stats = test(quantized_det_model, core, det_data_loader, det_validator, num_samples=NUM_TEST_SAMPLES)
print("FP32 model accuracy")
print_stats(fp_det_stats, det_validator.seen, det_validator.nt_per_class.sum())
print("INT8 model accuracy")
print_stats(int8_det_stats, det_validator.seen, det_validator.nt_per_class.sum())

? 上图中是打印的模型量化前后的预测精度情况,为了更好的查看量化前后精度变化,此处绘制了柱状图,如下图所示,通过该柱状图可以看出,模型在量化前后,模型预测精度存在较小的下降,但也满足我们的模型量化需求。

1.4.3 量化前后速度对比
? OpenVINO? 提供了性能测试工具 Benchmark App ,方便开发者快速测试 OpenVINO? 模型在不同的硬件平台上的性能,此处由于OpenVINO GPU算子对RT-DETR模型还不支持,因此此处我们只进行在CPU平台上测试。
首先测试量化前的模型,只需要输入以下指令即可:
!benchmark_app -m {det_model_path} -d {device.value} -api async -shape "[1,3,640,640]"

? 上图中展示了量化前的模型在CPU平台下的推理速度,可以看到,量化前模型推理速度仅能达到2.67 FPS。接下来测试量化后的模型,只需要输入以下指令即可:
!benchmark_app -m {int8_model_det_path} -d {device.value} -api async -shape "[1,3,640,640]" -t 15

? 上图中展示了量化后的模型在iCPU平台下的推理速度,可以看到,量化前模型推理速度仅能达到8.82 FPS,推理速度提升了3.3倍。
注:上述量化过程只是根据两国或称的几个重点步骤进行了讲解,完整的量化步骤以及实现顺序请参考上文中所指出的Notebook文章。
2. Intel iGPU 推理加速RT-DETR 模型和速度比较
2.1 Intel iGPU 推理加速RT-DETR 模型实现
? 由于当前OpenVINO发行版GPU算子不支持RT-DETR 模型实现,所以我们无法直接进行iGPU加速推理,但为了提升模型推理速度,通过OpenVINO GitHub 提交Issues,对源码进行修改,然后重新编译源码,更新动态链接库引用,便可以实现iGPU加速推理。Issues链接为:
? 大家在使用时,可以参考官方提供的解决方案,对源码进行修改,然后根据OpenVINO源码编译流程,对源码进行编译,获取修改后的动态链接库。
? 此处为了方便大家使用,我们在项目中提供了编译好的Windows的动态链接库,通过下述方式进行下载:
wget https://github.com/guojin-yan/RT-DETR-OpenVINO/releases/download/Model2.0/openvino_new_build.rar
? 通过该方式下载编译好的动态链接库文件后,然后参考上一篇文章《基于 OpenVINO? C++ API 部署 RT-DETR 模型 | 开发者实战》(https://mp.weixin.qq.com/s/L0UtZn_kN2RxuXm_r0MjYA)进行开发,将动态链接库引用替换成此处下载的动态链接库文件,并将设备设置为GPU,然后便可以实现GPU推理。
2.2 CPU与iGPU推理速度对比
? 在上一步中我们实现了基于OpenVINO 在iGPU设备上进行RT-DETR模型的推理加速,并在上一节中我们实现了模型INT8量化,最后我们在此处进行一个对比试验,分别在CPU和iGPU推理设备下,推理FP32和INT8模型,检验模型的推理速度,为了避免偶然性,此处通过推理100次求平均获取最后的推理速度,如下表所示:
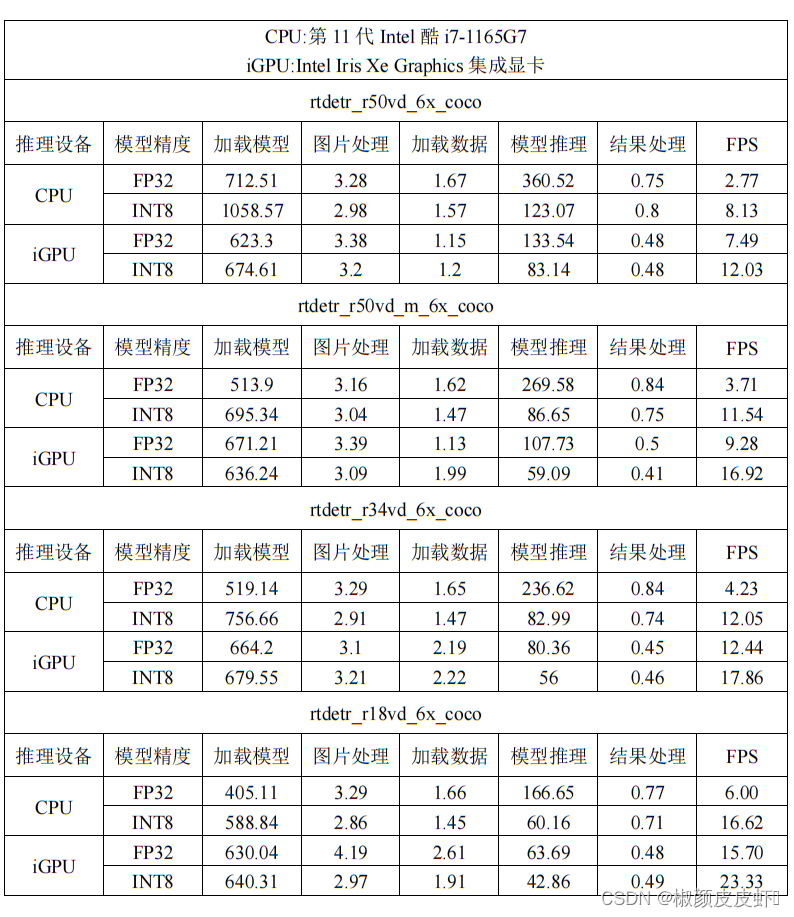
? 测试硬件:CPU处理器为第11代Intel酷i7-1165G7,iGPU为Intel Iris Xe Graphics集成显卡。通过绘制在不同平台、不同精度模型推理时间以及FPS柱状图,可以很明显看出,不管模型是经过量化或者是iGPU 加速,在不同推理设备上,模型推理速度会有1~3倍不同程度的提升。通过测试可以看出最快速度可以实现23帧左右的推理。
3. 总结
? 在本文中,我们基于OpenVINO下的模型优化工具NNCF,实现了RT-DETR模型的INT8量化,并且在损失极少的精度代价下,实现了模型推理速度提升3~4倍左右,模型大小将为原来的1/4,即提升了模型的推理速度,又降低了模型推理占用内存,这对在边缘设备部署具有十分重要的意义。
另外,我们通过OpenVINO Github指导,解决了RT-DETR模型无法在Intel iGPU上推理的困扰,实现了使用OpenVNO 在iGPU设备上的推理加速,使得模型推理速度有了1~3倍的提升。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!