【论文阅读笔记】A Recent Survey of Vision Transformers for Medical Image Segmentation
Khan A, Rauf Z, Khan A R, et al. A Recent Survey of Vision Transformers for Medical Image Segmentation[J]. arXiv preprint arXiv:2312.00634, 2023.
【论文概述】
本文是关于医学图像分割中视觉变换器(Vision Transformers,ViTs)的最新综述。文中详细回顾了ViTs及其与卷积神经网络(CNNs)结合形成的混合视觉Transformers(Hybrid Vision Transformers,HVTs)在医学图像分割方面的最新进展。文中讨论了这些技术如何通过模拟图像中的长距离关系来提高诊断、治疗计划和疾病监测的准确性。同时,还探讨了这些方法在不同医学图像模态(如CT、MRI、X射线等)中的实际应用,以及它们面临的挑战和未来的发展方向。
本文中规中矩,对涉及到的方法只是简单陈列,并没有细致的优缺点探讨,可以作为寻找对应方向论文的一个参考,笔记中对涉及到的方法根据之前读文经历进行简单的优缺点归纳。
【本文模型的分类方法】
- 本文首先对基于ViT的医学图像分割方法进行了全面综述,将其分为两大类:基于ViT的方法(ViT-based methods)和混合视觉Transformers的方法(HVT-based methods)。
- 对于基于ViT的方法,进一步将其细分为以下四类:
-
ViT在编码器(encoder)中的应用。
-
ViT在解码器(decoder)中的应用。
-
ViT在编码器-解码器之间(in between encoder-decoder)的应用。
-
编码器和解码器都采用基于ViT的架构(both the encoder and decoder are ViT-based architectures)。
3.对于混合视觉Transformers(HVT)的方法,提出了一个分类法:
-
基于编码器的集成(encoder-based integration)。
-
基于解码器的集成(decoder-based integration)。
【医学图像分割存在的一些挑战】
1.在医学图像中的对象内发现的尺寸范围很广
2.结构轮廓的模糊性,加上它们的不同纹理变化和复杂形状,这很容易产生不准确的结果
3.当将感兴趣的对象与背景隔离时,低强度对比度带来的挑战
4.没有足够的训练数据集
【4.1 ViT-based Medical Image Segmentation Approaches】
这一部分从四个方面探讨了ViTs在医学图像分割中的应用,包括ViT在编码器(Encoder)、解码器(Decoder)、编码器-解码器中的应用,以及ViT在编码器和解码器之间的应用。以下是对这些部分的总结:
-
ViT in Encoder:
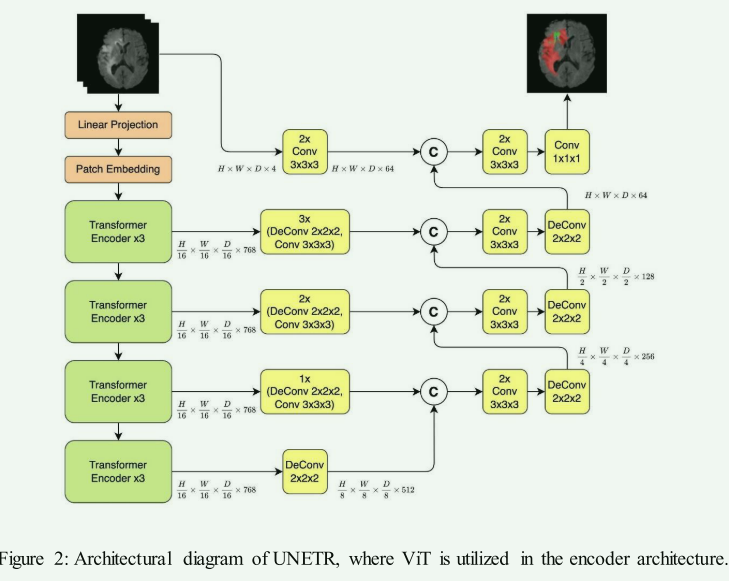
- 优点:通过在编码器中使用ViT,模型能有效捕获全局信息和多尺度特征,从而增强特征提取能力。
- 代表模型:例如UNETR(UNet Transformer),利用ViT作为编码器来有效捕获输入体积的多尺度全球信息。
- 缺点:可能会增加模型的计算复杂性和训练难度。
-
ViT in Decoder:
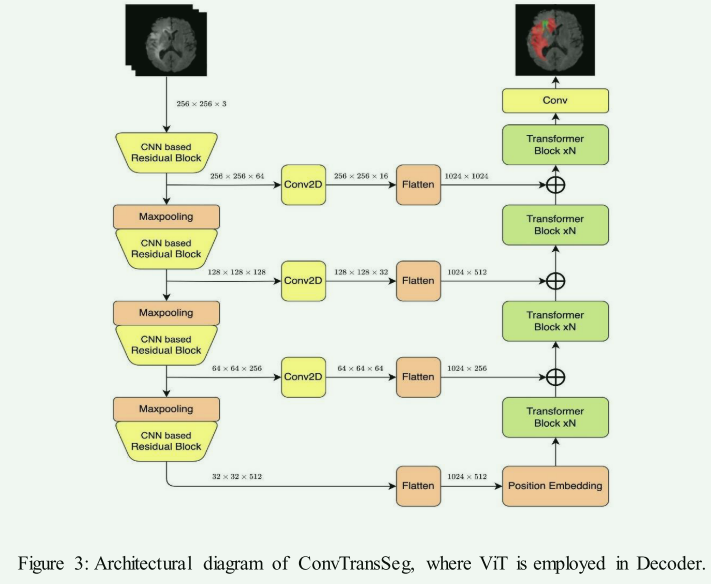
- 优点:将ViT应用于解码器可以提高预测边界精度,并区分背景和兴趣对象。
- 代表模型:如ConvTransSeg,采用CNN编码器和基于ViT的解码器。
- 缺点:解码阶段的全局信息处理可能不如编码阶段有效。
-
ViT in both Encoder-Decoder:
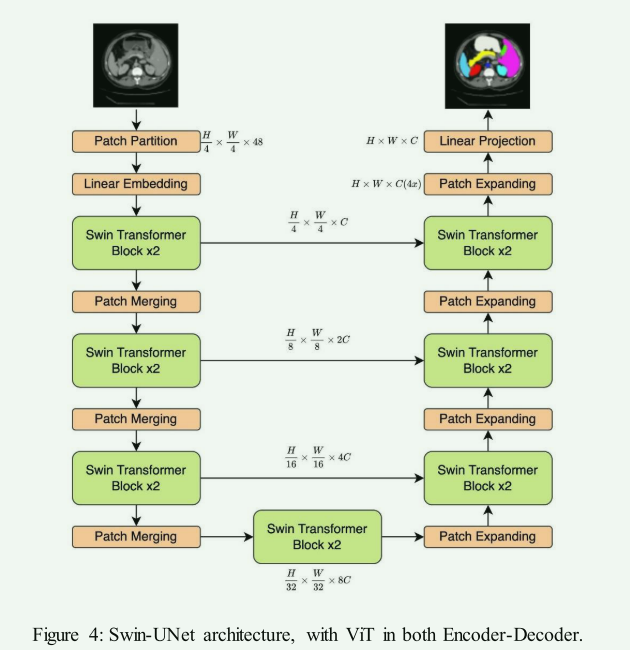
- 优点:在编码器和解码器都使用ViT的架构能全面利用ViT的长距离关注机制。
- 代表模型:例如Swin-Unet和、nnFormer、MISSFormer、TransDeepLab,这些模型在编码器和解码器中都使用ViT结构,以捕获图像的全局和局部特征。
- 缺点:这种方法可能导致更高的计算成本和更复杂的模型结构。
-
ViT in between Encoder-Decoder:
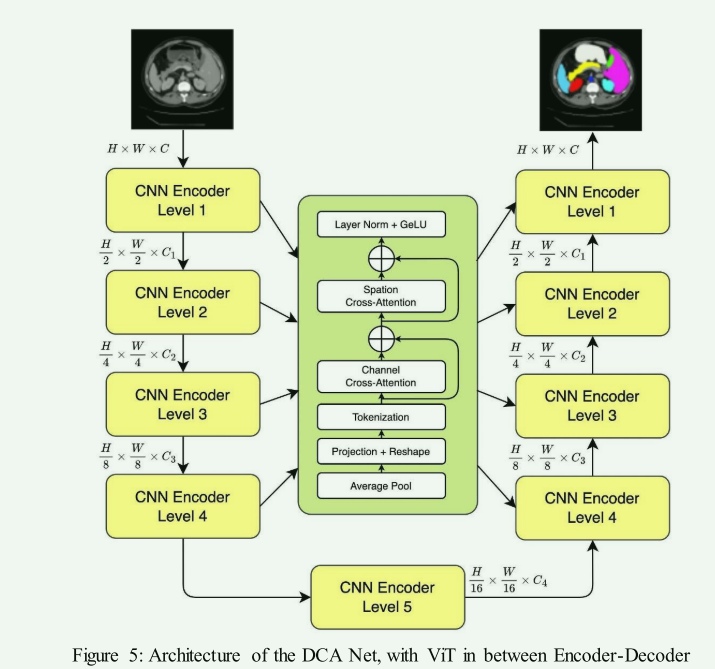
- 优点:此方法通过在编码器和解码器之间引入ViT,可以在局部和全局特征之间建立更有效的连接。
- 代表模型:例如ATTransUNet和DCA(Dual Cross-Attention)、ViT-V-Net,它们在编码器和解码器之间使用ViT,以改善特征融合和上下文建模。
- 缺点:可能需要更复杂的训练策略来优化特征融合。
【4.2. Hybrid ViT-Based Medical Image Segmentation Approaches】
探讨了混合视觉Transformers(Hybrid Vision Transformers, HVTs)在医学图像分割中的应用。这些方法结合了卷积神经网络(CNNs)和视觉变换器(ViTs)的优势,以提高分割性能。以下是对这一部分内容的总结,包括三个主要方面:
-
Hybrid ViT in Encoder:
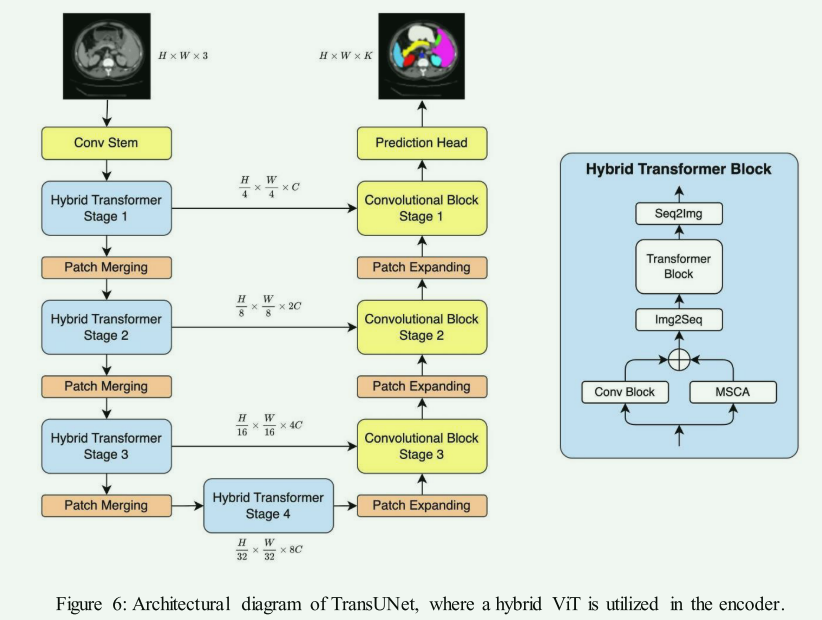
- 优点:通过在编码器中结合HVT,模型能够同时捕获全局和局部特征,提高特征表示的丰富性。
- 代表模型:例如TransUNet,结合了ViT的全局感知能力和U-Net的局部特征提取能力;TransBTS,结合了ViT和3D CNN,用于处理3D医学体积数据。
- 缺点:混合模型可能会增加模型复杂度,需要更多的计算资源。
-
Hybrid ViT in Decoder:
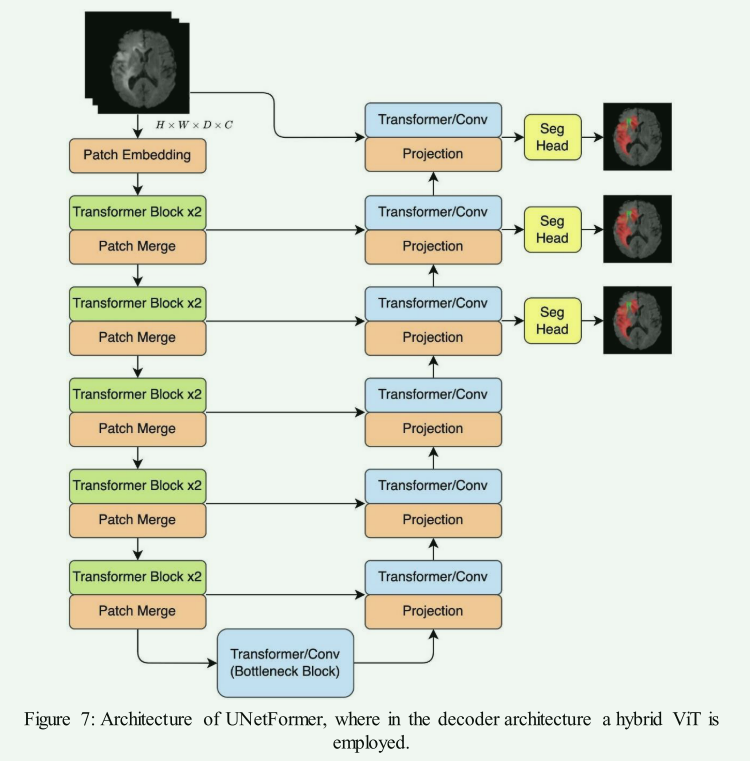
- 优点:在解码器中应用HVT可以提高分割边界的准确性,特别是在处理复杂的医学图像时。
- 代表模型:例如UNetFormer,结合了3D Swin Transformer和CNN,以及基于变换器的解码器。
- 缺点:这种方法可能导致解码阶段的计算负担加重。
-
Hybrid ViT in both Encoder-Decoder:
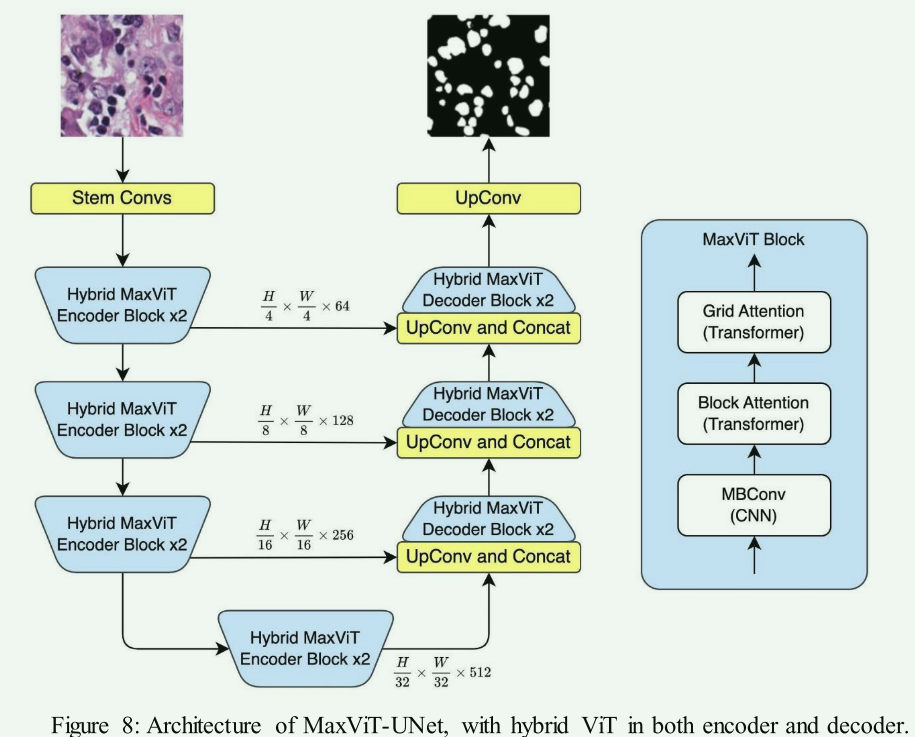
- 优点:在编码器和解码器中都使用HVT可以充分利用ViT和CNN的优势,实现全面的特征提取和细节捕获。
- 代表模型:例如MaxViT-UNet、SwinBTS,利用3D Swin Transformer和卷积操作来学习局部和全局级别的特征。
- 缺点:这种结构可能导致模型过于复杂,难以训练和优化。
【5. ViT-based Medical Image Segmentation Applications】
作者详细讨论了基于视觉Transformers(Vision Transformers, ViTs)的医学图像分割应用,覆盖了从CT图像到X射线图像的多种医学成像方式。以下是对这一部分内容的概括总结:
- CT图像(CT Images):
- 应用了ViT的方法能有效地处理CT图像,提高了病灶检测的准确性。
- 代表模型:如TransBTS,利用ViT与3D CNN相结合,以处理3D CT数据。
- 病理学图像(Histopathological Images):
- 在病理学图像分析中,ViT有助于细胞结构的精准分割和识别。
- 代表模型:如TransPath,它将ViT与传统的CNN技术结合,以提高细胞和组织的分割效果。
- 显微镜图像(Microscopy Images):
- ViT在处理显微镜图像时展现了提高分割准确性的潜力,特别是在复杂的细胞结构分割方面。
- 代表模型:例如使用ViT的各种混合方法,它们结合CNN的局部特征识别能力和ViT的全局信息处理能力。
- MRI图像(MRI Images):
- ViT在MRI图像分割中特别有效,能够处理复杂的脑部结构。
- 代表模型:如Swin UNETR和TransBTS,它们在处理脑肿瘤分割等高复杂度任务中表现出色。
- 超声图像(Ultrasound Images):
- ViT在超声图像分割中有助于提高边界检测的准确性,特别是在不规则形状的肿瘤识别方面。
- 代表模型:例如结合ViT和CNN技术的混合模型,用于提高超声图像中特定组织或病变的识别能力。
- X射线图像(X-Ray Images):
- ViT在X射线图像分割中表现出对细节的高敏感性,特别是在骨骼和其他硬组织的分割方面。
- 代表模型:如结合CNN和ViT的模型,用于提高诸如肺部疾病识别和骨折检测的准确性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!