数模学习day06-主成分分析
????????主成分分析(Principal Component Analysis,PCA)主成分分析是一种降维算法,它能将多个指标转换为少数几个主成分,这些主成分是原始变量的线性组合,且彼此之间互不相关,其能反映出原始数据的大部分信息。一般来说当研究的问题涉及到多变量且变量之间存在很强的相关性时我们可考虑使用主成分分析的方法来对数据进行简化。
问题引出
????????在实际问题研究中,多变量问题是经常会遇到的。变量太多,无疑会增加分析问题的难度与复杂性,而且在许多实际问题中,多个变量之间是具有一定的相关关系的.
????????因此,人们会很自然地想到,能否在相关分析的基础上,用较少的新变量代替原来较多的旧变量,而且使这些较少的新变量尽可能多地保留原来变量所反映的信息?
????????事实上,这种想法是可以实现的,主成分分析方法就是综合处理这种问题的一种强有力的工具。
????????主成分分析是把原来多个变量划为少数几个综合指标的一种统计分析方法。从数学角度来看,这是一种降维处理技术
数据降维的作用
????????降维是将高维度的数据 (指标太多) 保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。
????????在实际的生产和应用中,降维在一定的信息损失范围内可以为我们节省大量的时间和成本。降维也成为应用非常广泛的数据预处理方法。
降维具有如下一些优点:
(1)使得数据集更易使用
(2)降低算法的计算开销
(3)去除噪声
(4)使得结果容易理解
例子

主成分分析的
思想


?
计算步骤
?



例题一
相关系数矩阵可以使用? corrcoef 这个函数计算


表中可以看到前三个主成分的累计贡献率达85.9%,因此可以考虑只取前面三个主成分,它们能够很好的概括原式变量。


例题二


这里为什么上半部分是空白的呢,是因为这个样本相关系数矩阵是一个对称的矩阵,所以是空白的。
然后就是计算相关的关键变量.

只要前两项贡献率已经达到了90%多了,所以后面的已经不重要了了。
然后重点就是如何解释主成分了。
由上表可知,前两个主成分的累计贡献率已高达93.7%,第一主成分F1在所有变量上有几乎相等的正载荷,可称为在径赛项目上的强弱成分第二主成分F2在各个指标上的载荷基本上逐个递减,反映了速度与耐力成绩的对比。
MATLAB代码实现
lambda = lambda(end:-1:1)
从大到小排序
V=rot90(V)';
disp(V)
将列的顺序调换
clear;clc
load data1.mat % 主成分聚类
% load data2.mat % 主成分回归
% 注意,这里可以对数据先进行描述性统计
% 描述性统计的内容见第5讲.相关系数,该文章还未更新
[n,p] = size(x); % n是样本个数,p是指标个数
%% 第一步:对数据x标准化为X
X=zscore(x); % matlab内置的标准化函数(x-mean(x))/std(x)
%% 第二步:计算样本协方差矩阵
R = cov(X);
%% 注意:以上两步可合并为下面一步:直接计算样本相关系数矩阵
R = corrcoef(x);
disp('样本相关系数矩阵为:')
disp(R)
%% 第三步:计算R的特征值和特征向量
% 注意:R是半正定矩阵,所以其特征值不为负数
% R同时是对称矩阵,Matlab计算对称矩阵时,会将特征值按照从小到大排列哦
% eig函数的详解见第一讲层次分析法的视频
[V,D] = eig(R); % V 特征向量矩阵 D 特征值构成的对角矩阵
%% 第四步:计算主成分贡献率和累计贡献率
lambda = diag(D); % diag函数用于得到一个矩阵的主对角线元素值(返回的是列向量)
lambda = lambda(end:-1:1); % 因为lambda向量是从小大到排序的,我们将其调个头
contribution_rate = lambda / sum(lambda); % 计算贡献率
cum_contribution_rate = cumsum(lambda)/ sum(lambda); % 计算累计贡献率 cumsum是求累加值的函数
disp('特征值为:')
disp(lambda') % 转置为行向量,方便展示
disp('贡献率为:')
disp(contribution_rate')
disp('累计贡献率为:')
disp(cum_contribution_rate')
disp('与特征值对应的特征向量矩阵为:')
% 注意:这里的特征向量要和特征值一一对应,之前特征值相当于颠倒过来了,因此特征向量的各列需要颠倒过来
% rot90函数可以使一个矩阵逆时针旋转90度,然后再转置,就可以实现将矩阵的列颠倒的效果
V=rot90(V)';
disp(V)
%% 计算我们所需要的主成分的值
m =input('请输入需要保存的主成分的个数: ');
F = zeros(n,m); %初始化保存主成分的矩阵(每一列是一个主成分)
for i = 1:m
ai = V(:,i)'; % 将第i个特征向量取出,并转置为行向量
Ai = repmat(ai,n,1); % 将这个行向量重复n次,构成一个n*p的矩阵
F(:, i) = sum(Ai .* X, 2); % 注意,对标准化的数据求了权重后要计算每一行的和
end
%% (1)主成分聚类 : 将主成分指标所在的F矩阵复制到Excel表格,然后再用Spss进行聚类
% 在Excel第一行输入指标名称(F1,F2, ..., Fm)
% 双击Matlab工作区的F,进入变量编辑中,然后复制里面的数据到Excel表格
% 导出数据之后,我们后续的分析就可以在Spss中进行。
%%(2)主成分回归:将x使用主成分得到主成分指标,并将y标准化,接着导出到Excel,然后再使用Stata回归
% Y = zscore(y); % 一定要将y进行标准化哦~
% 在Excel第一行输入指标名称(Y,F1, F2, ..., Fm)
% 分别双击Matlab工作区的Y和F,进入变量编辑中,然后复制里面的数据到Excel表格
% 导出数据之后,我们后续的分析就可以在Stata中进行。

然后就是解释
????????从上表可以看出,前两个和前三个主成分的累计贡献率分别达到80.6%和87.8%,第一主成分F1在所有变量(除在x2上的载荷稍偏小外)上都有近似相等的正载荷,反映了综合消费性支出的水平,因此第一主成分可称为综合消费性支出成分。第二主成分F2在变量x2上有很高的正载荷,在变量x4上有中等的正载荷,而在其余变量上有负载荷或很小的正载荷。可以认为这个主成分度量了受地区气候影响的消费性支出(主要是衣着,其次是医疗保健 )在所有消费性支出中占的比重(也可理解为一种消费倾向),第二主成分可称为消费倾向成分。第三主成分很难给出明显的解释,因此我们只取前面两个主成分。
数据可视化
求出R之后将它粘贴到Excel表格中
然后调整行高到? ?50? 这样就是方形的了

然后再选择条件格式

再选择色阶

再修改管理规则

点击编辑规则
再修改成这样就基本上是一个颜色了

样子如下

颜色越深相关系数越强
主成分分析的滥用:主成分得分

主成分分析用于聚类

(1)主成分聚类 : 将主成分指标所在的F矩阵复制到Excel表格,然后再用Spss进行聚类
在Excel第一行输入指标名称(F1,F2, ..., Fm)
双击Matlab工作区的F,进入变量编辑中,然后复制里面的数据到Excel表格
导出数据之后,我们后续的分析就可以在Spss中进行。(2)主成分回归:将x使用主成分得到主成分指标,并将y标准化,接着导出到Excel,然后再使用Stata回归
Y = zscore(y); ?% 一定要将y进行标准化哦~
在Excel第一行输入指标名称(Y,F1, F2, ..., Fm)
分别双击Matlab工作区的Y和F,进入变量编辑中,然后复制里面的数据到Excel表格
导出数据之后,我们后续的分析就可以在Stata中进行。
?
spss聚类操作
首先找到系统聚类

移动指标

加上谱系图

画图


通过这个图就可以大致看出聚类的效果
主成分回归
用于解决多重共线性的问题
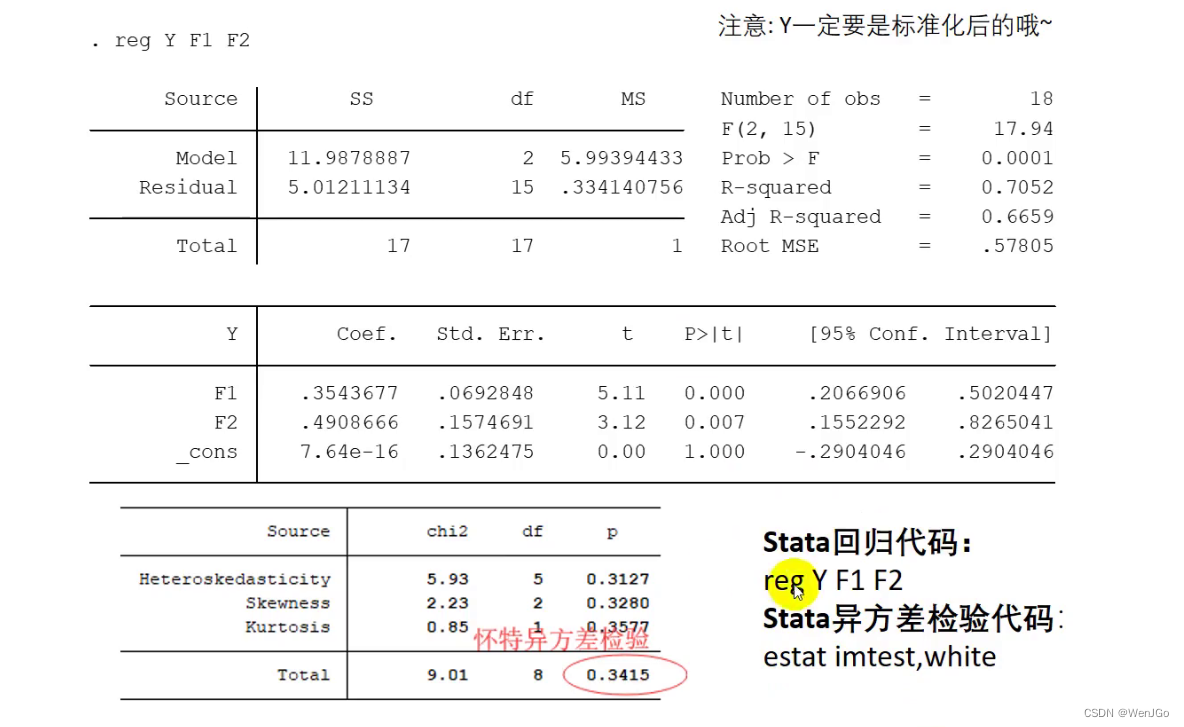
问题1: 之前学过逐步回归,逐步回归也可以用来解决多重共线性问题,我该用逐步回归还是今天学习的主成分分析呢?如果你能够很好的解释清楚主成分代表的含义,那么我建议你在正文中既用主成分分析,又用逐步回归 (多分析点没啥坏处只要你能保证你不分析错就行),如果你解释不清楚,那么还是用逐步回归吧。
问题2: 主成分回归后,需要将原来的变量带回到回归方程吗?我觉得没必要,要是你带回去了,那和普通的回归有什么区别呢。主成分的核心作用就是降维,带回去了维度也没降下来呀
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!